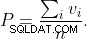La réponse à cette question dépend du fait que vous utilisiez mysql avant 5.7 ou 5.7 et après. Je modifie peut-être légèrement votre question, mais j'espère que ce qui suit reflète ce que vous recherchez.
Votre tableau SELECT * FROM Table effectue une analyse de table via l'index clusterisé (l'ordre physique). Dans le cas d'aucune clé primaire, on est implicitement
disponible pour le moteur. Il n'y a pas de clause where comme vous le dites. Aucun filtrage ou choix d'un autre index n'est tenté.
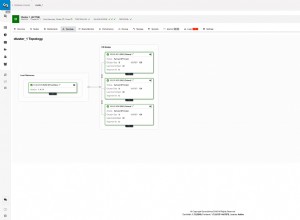
L'Expliquer
sortie (voir aussi
) affiche 1 ligne dans son résumé. C'est relativement simple. La sortie d'explication et les performances avec votre table dérivée B sera différent selon que vous êtes sur une version antérieure à 5.7, ou 5.7 et après.
Le document Tables dérivées dans MySQL 5.7 le décrit bien pour les versions 5.6 et 5.7, où cette dernière ne fournira aucune pénalité en raison de la modification de la sortie matérialisée de la table dérivée incorporée dans la requête externe. Dans les versions précédentes, des frais généraux substantiels étaient supportés avec des tables temporaires avec les dérivés.
Il est assez facile de tester la pénalité de performance avant la version 5.7. Tout ce qu'il faut, c'est une table de taille moyenne pour voir l'impact notable que la table dérivée de votre question a sur les performances. L'exemple suivant est sur une petite table dans la version 5.6 :
explain
select qm1.title
from questions_mysql qm1
join questions_mysql qm2
on qm2.qid<qm1.qid
where qm1.qid>3333 and qm1.status='O';
+----+-------------+-------+-------+-----------------+---------+---------+------+-------+------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+-----------------+---------+---------+------+-------+------------------------------------------------+
| 1 | SIMPLE | qm1 | range | PRIMARY,cactus1 | PRIMARY | 4 | NULL | 5441 | Using where |
| 1 | SIMPLE | qm2 | ALL | PRIMARY,cactus1 | NULL | NULL | NULL | 10882 | Range checked for each record (index map: 0x3) |
+----+-------------+-------+-------+-----------------+---------+---------+------+-------+------------------------------------------------+
explain
select b.title from
( select qid,title from questions_mysql where qid>3333 and status='O'
) b
join questions_mysql qm2
on qm2.qid<b.qid;
+----+-------------+-----------------+-------+-----------------+---------+---------+------+-------+----------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------------+-------+-----------------+---------+---------+------+-------+----------------------------------------------------+
| 1 | PRIMARY | qm2 | index | PRIMARY,cactus1 | cactus1 | 10 | NULL | 10882 | Using index |
| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 5441 | Using where; Using join buffer (Block Nested Loop) |
| 2 | DERIVED | questions_mysql | range | PRIMARY,cactus1 | PRIMARY | 4 | NULL | 5441 | Using where |
+----+-------------+-----------------+-------+-----------------+---------+---------+------+-------+----------------------------------------------------+
Remarque, j'ai changé la question, mais cela illustre l'impact des tables dérivées et leur manque d'utilisation de l'index avec l'optimiseur dans les versions antérieures à 5.7. La table dérivée bénéficie des index lors de sa matérialisation. Mais par la suite, il supporte la surcharge en tant que table temporaire et est incorporé dans la requête externe sans utiliser d'index. Ce n'est pas le cas dans la version 5.7