Veuillez jeter un œil au code suivant, si votre réponse à mon commentaire est yes :) Depuis vos données toutes en 2012, et mois de novembre, j'ai pris jour.
- SQLFIDDLE échantillon
Requête :
select y.id, y.userid, y.score, y.datestamp
from (select id, userid, score, datestamp
from scores
group by day(datestamp)) as y
where (select count(*)
from (select id, userid, score, datestamp
from scores group by day(datestamp)) as x
where y.score >= x.score
and y.userid = x.userid
) =1 -- Top 3rd, 2nd, 1st
order by y.score desc
;
Résultats :
ID USERID SCORE DATESTAMP
8 2 8.5 December, 07 2012 00:00:00+0000
20 3 6 December, 08 2012 00:00:00+0000
1 1 5 December, 06 2012 00:00:00+0000
Sur la base de vos dernières mises à jour de la question. Si vous en avez besoin par utilisateur par année/mois/jour et que vous trouvez ensuite le plus élevé, vous pouvez simplement ajouter une fonction d'agrégation comme sum à la requête ci-dessus. Je me répète, puisque votre exemple de données ne porte que sur une année, il n'y a pas de groupe de points par année ou par mois. C'est pourquoi j'ai pris la journée.
select y.id, y.userid, y.score, y.datestamp
from (select id, userid, sum(score) as score,
datestamp
from scores
group by userid, day(datestamp)) as y
where (select count(*)
from (select id, userid, sum(score) as score
, datestamp
from scores
group by userid, day(datestamp)) as x
where y.score >= x.score
and y.userid = x.userid
) =1 -- Top 3rd, 2nd, 1st
order by y.score desc
;
Résultats basés sur la somme :
ID USERID SCORE DATESTAMP
1 1 47.5 December, 06 2012 00:00:00+0000
8 2 16 December, 07 2012 00:00:00+0000
20 3 6 December, 08 2012 00:00:00+0000
MIS À JOUR AVEC UN NOUVEL ÉCHANTILLON DE DONNÉES SOURCE
Simon, s'il vous plaît jetez un oeil à mon propre échantillon. Comme vos données changeaient, j'ai utilisé les miennes. Voici la référence. J'ai utilisé pur ansi style sans aucun over partition ou dense_rank Notez également que les données que j'ai utilisées obtiennent les 2 meilleurs scores et non les 3 meilleurs. Vous pouvez le modifier en conséquence.
Devinez quoi, la réponse est 10 fois plus simple que la première impression que vos premières données ont donnée...
SQLFIDDLE
Requête à 1 :-- pour la somme des 2 top par utilisateur et par jour
SELECT userid, sum(Score), datestamp
FROM scores t1
where 2 >=
(SELECT count(*)
from scores t2
where t1.score <= t2.score
and t1.userid = t2.userid
and day(t1.datestamp) = day(t2.datestamp)
order by t2.score desc)
group by userid, datestamp
;
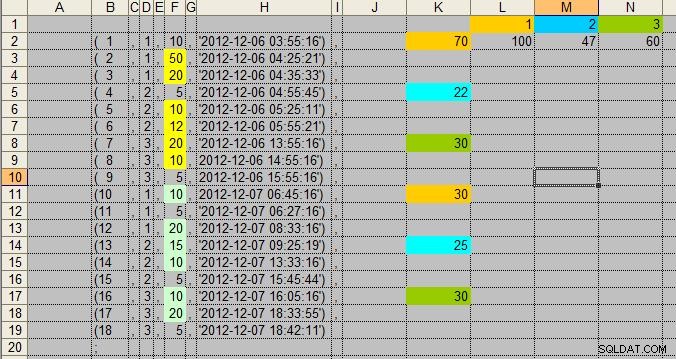
Résultats pour la requête 1 :
USERID SUM(SCORE) DATESTAMP
1 70 December, 06 2012 00:00:00+0000
1 30 December, 07 2012 00:00:00+0000
2 22 December, 06 2012 00:00:00+0000
2 25 December, 07 2012 00:00:00+0000
3 30 December, 06 2012 00:00:00+0000
3 30 December, 07 2012 00:00:00+0000
Requête finale : - pour les deux jours, la somme des 2 top par utilisateur
SELECT userid, sum(Score)
FROM scores t1
where 2 >=
(SELECT count(*)
from scores t2
where t1.score <= t2.score
and t1.userid = t2.userid
and day(t1.datestamp) = day(t2.datestamp)
order by t2.score desc)
group by userid
;
Résultats finaux :
USERID SUM(SCORE)
1 100
2 47
3 60
Voici un aperçu des calculs directs des données que j'ai utilisées.