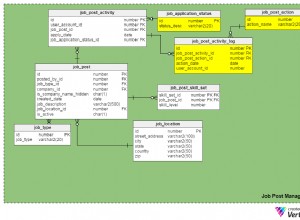
Le problème ici est le sous-typage . Il existe trois approches de base pour traiter les sous-types.
- Placez chaque type d'enregistrement dans un tableau complètement séparé ;
- Mettez un enregistrement dans une table parent, puis un enregistrement dans une table de sous-type ; et
- Mettez tous les enregistrements dans une table, avec des colonnes acceptant les valeurs nulles pour les données "facultatives" (c'est-à-dire les éléments qui ne s'appliquent pas à ce type).
Chaque stratégie a ses mérites.
Par exemple, (3) est particulièrement applicable s'il y a peu ou pas de différence entre les différents sous-types. Dans votre cas, différents enregistrements de journal ont-ils des colonnes supplémentaires s'ils sont d'un type particulier ? S'ils ne le font pas ou s'il y a peu de cas où ils le font, les mettre tous dans un seul tableau est parfaitement logique.
(2) est couramment utilisé pour une table de fête. Il s'agit d'un modèle courant dans les CRM qui implique un objet Partie parent qui a des sous-types pour Personne et Organisation (l'Organisation peut également avoir des sous-types comme Entreprise, Association, etc.). La personne et l'organisation ont des propriétés différentes (par exemple, salutation, prénoms, date de naissance, etc. pour la personne), il est donc logique de diviser cela plutôt que d'utiliser des colonnes nullables.
(2) est potentiellement plus économe en espace (bien que la surcharge des colonnes NULL dans les SGBD modernes soit très faible). Le plus gros problème est que (2) pourrait être plus déroutant pour les développeurs. Vous obtiendrez une situation où quelqu'un a besoin de stocker un champ supplémentaire quelque part et le placera dans une colonne vide pour ce type simplement parce que c'est plus facile que d'obtenir l'approbation des administrateurs de base de données pour ajouter une colonne (non, je ne plaisante pas ).
(1) est probablement le schéma le moins fréquemment utilisé des 3 selon mon expérience.
Enfin, l'évolutivité doit être prise en compte et est probablement le meilleur cas pour (1). À un certain moment, les JOIN ne s'adaptent pas efficacement et vous devrez utiliser une sorte de schéma de partitionnement pour réduire la taille de vos tables. (1) est une méthode pour le faire (mais une méthode grossière).
Je ne m'en soucierais pas trop cependant. Vous devrez généralement accéder à des centaines de millions ou de milliards d'enregistrements avant que cela ne devienne un problème (sauf si vos enregistrements sont vraiment très volumineux, auquel cas cela se produira plus tôt).