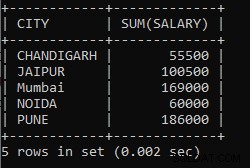
Pour répondre à cette question, il faut d'abord analyser le réel problème auquel vous êtes confronté.
Le vrai problème serait la combinaison la plus efficace d'écriture et de récupération de données.
Passons en revue vos conclusions :
-
des milliers de tables - eh bien, cela viole l'objectif des bases de données et rend plus difficile le travail avec. Vous ne gagnez rien non plus. La recherche de disque est toujours impliquée, cette fois avec de nombreux descripteurs de fichiers en cours d'utilisation. Vous devez également connaître les noms des tables, et il y en a des milliers. Il est également difficile d'extraire des données, ce à quoi servent les bases de données - de structurer les données de manière à pouvoir facilement recouper les enregistrements. Des milliers de tables - pas efficace de perf. point de vue. Pas efficace du point de vue de l'utilisation. Mauvais choix.
-
un fichier csv - c'est probablement excellent pour récupérer les données, si vous avez besoin de tout le contenu en même temps. Mais c'est loin d'être bon pour manipuler ou transformer les données. Étant donné que vous comptez sur une mise en page spécifique, vous devez faire très attention lorsque vous écrivez au format CSV. Si cela atteint des milliers de fichiers CSV, vous ne vous êtes pas rendu service. Vous avez supprimé toute la surcharge de SQL (qui n'est pas si importante) mais vous n'avez rien fait pour récupérer des parties de l'ensemble de données. Vous avez également des problèmes pour récupérer des données historiques ou faire des références croisées. Mauvais choix.
Le scénario idéal serait de pouvoir accéder à n'importe quelle partie de l'ensemble de données de manière efficace et rapide sans aucun type de changement de structure.
Et c'est exactement la raison pour laquelle nous utilisons des bases de données relationnelles et pourquoi nous dédions des serveurs entiers avec beaucoup de RAM à ces bases de données.
Dans votre cas, vous utilisez des tables MyISAM (extension de fichier .MYD). C'est un ancien format de stockage qui fonctionnait très bien pour le matériel bas de gamme utilisé à l'époque. Mais de nos jours, nous avons des ordinateurs excellents et rapides. C'est pourquoi nous utilisons InnoDB et lui permettons d'utiliser beaucoup de RAM afin de réduire les coûts d'E/S. La variable en question qui la contrôle s'appelle innodb_buffer_pool_size - googler qui produira des résultats significatifs.
Pour répondre à la question - une solution efficace et satisfaisante serait d'utiliser une table où vous stockez les informations du capteur (id, titre, description) et une autre table où vous stockez les lectures du capteur. Vous allouez suffisamment de RAM ou de stockage suffisamment rapide (un SSD). Les tableaux ressembleraient à ceci :
CREATE TABLE sensors (
id int unsigned not null auto_increment,
sensor_title varchar(255) not null,
description varchar(255) not null,
date_created datetime,
PRIMARY KEY(id)
) ENGINE = InnoDB DEFAULT CHARSET = UTF8;
CREATE TABLE sensor_readings (
id int unsigned not null auto_increment,
sensor_id int unsigned not null,
date_created datetime,
reading_value varchar(255), -- note: this column's value might vary, I do not know what data type you need to hold value(s)
PRIMARY KEY(id),
FOREIGN KEY (sensor_id) REFERENCES sensors (id) ON DELETE CASCADE
) ENGINE = InnoDB DEFAULT CHARSET = UTF8;
InnoDB, par défaut, utilise un fichier plat pour l'ensemble de la base de données/installation. Cela atténue le problème de dépassement de la limite de descripteur de fichier du système d'exploitation / système de fichiers. Plusieurs, voire des dizaines de millions d'enregistrements ne devraient pas poser de problème si vous deviez allouer 5 à 6 Go de RAM pour conserver l'ensemble de données de travail en mémoire, ce qui vous permettrait un accès rapide aux données.
Si je devais concevoir un tel système, c'est la première approche que je ferais (personnellement). À partir de là, il est facile de s'adapter en fonction de ce que vous devez faire avec ces informations.