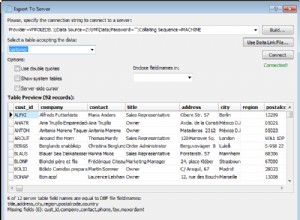
Le problème était que l'object dtype est trompeur. Je pensais que cela signifiait que tous les éléments étaient des chaînes. Mais apparemment, lors de la lecture du fichier, pandas convertissait certains éléments en entiers et laissait le reste sous forme de chaînes.
La solution consistait à s'assurer que chaque champ est une chaîne :
>>> df1.col1 = df1.col1.astype(str)
>>> df2.col2 = df2.col2.astype(str)
Ensuite, la fusion fonctionne comme prévu.
(J'aimerais qu'il y ait un moyen de spécifier un dtype de str ...)