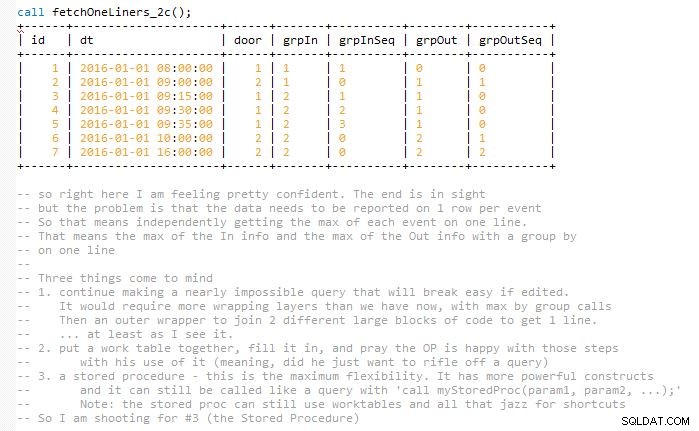
Cela s'efforce de garder la solution facilement maintenable sans terminer la requête finale en une seule fois, ce qui aurait presque doublé sa taille (dans mon esprit). En effet, les résultats doivent correspondre et être représentés sur une ligne avec des événements In et Out correspondants. Donc à la fin, j'utilise quelques tables de travail. Il est implémenté dans une procédure stockée.
La procédure stockée utilise plusieurs variables qui sont introduites avec une cross join . Considérez la jointure croisée comme un simple mécanisme d'initialisation des variables. Les variables sont maintenues en toute sécurité, donc je crois, dans l'esprit de ce document
souvent référencé dans les requêtes variables. Les parties importantes de la référence sont la gestion sûre des variables sur une ligne forçant leur définition avant que d'autres colonnes ne les utilisent. Ceci est réalisé grâce au greatest() et least() les fonctions qui ont une priorité plus élevée que les variables définies sans l'utilisation de ces fonctions. Notez également que coalesce() est souvent utilisé dans le même but. Si leur utilisation semble étrange, comme prendre le plus grand d'un nombre connu pour être supérieur à 0, ou 0, eh bien c'est délibéré. Délibéré en forçant l'ordre de priorité des variables définies.
Les colonnes de la requête ont nommé des choses comme dummy2 etc sont des colonnes dont la sortie n'a pas été utilisée, mais elles ont été utilisées pour définir des variables à l'intérieur, disons, du greatest() ou un autre. Cela a été mentionné ci-dessus. Une sortie comme 7777 était un espace réservé dans le 3ème emplacement, car une certaine valeur était nécessaire pour le if() qui a été utilisé. Alors ignore tout ça.
J'ai inclus plusieurs captures d'écran du code au fur et à mesure de sa progression couche par couche pour vous aider à visualiser le résultat. Et comment ces itérations de développement sont lentement intégrées à la phase suivante pour développer la précédente.
Je suis sûr que mes pairs pourraient améliorer cela en une seule requête. J'aurais pu le finir comme ça. Mais je crois que cela aurait entraîné un désordre déroutant qui se briserait si on le touchait.
Schéma :
create table attendance2(Id int, DateTime datetime, Door char(20), Active_door char(20));
INSERT INTO attendance2 VALUES
( 1, '2016-01-01 08:00:00', 'In', ''),
( 2, '2016-01-01 09:00:00', 'Out', ''),
( 3, '2016-01-01 09:15:00', 'In', ''),
( 4, '2016-01-01 09:30:00', 'In', ''),
( 5, '2016-01-01 09:35:00', '', 'On'),
( 6, '2016-01-01 10:00:00', 'Out', ''),
( 7, '2016-01-01 16:00:00', '', 'Off');
drop table if exists oneLinersDetail;
create table oneLinersDetail
( -- architect this depending on multi-user concurrency
id int not null,
dt datetime not null,
door int not null,
grpIn int not null,
grpInSeq int not null,
grpOut int not null,
grpOutSeq int not null
);
drop table if exists oneLinersSummary;
create table oneLinersSummary
( -- architect this depending on multi-user concurrency
id int not null,
grpInSeq int null,
grpOutSeq int null,
checkIn datetime null, -- we are hoping in the end it is not null
checkOut datetime null -- ditto
);
Procédure stockée :
DROP PROCEDURE IF EXISTS fetchOneLiners;
DELIMITER $$
CREATE PROCEDURE fetchOneLiners()
BEGIN
truncate table oneLinersDetail; -- architect this depending on multi-user concurrency
insert oneLinersDetail(id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq)
select id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq
from
( select id,dt,door,
if(@lastEvt!=door and door=1,
greatest(@grpIn:example@sqldat.com+1,0),
7777) as dummy2, -- this output column we don't care about (we care about the variable being set)
if(@lastEvt!=door and door=2,
greatest(@grpOut:example@sqldat.com+1,0),
7777) as dummy3, -- this output column we don't care about (we care about the variable being set)
if (@lastEvt!=door,greatest(@flip:=1,0),least(@flip:=0,1)) as flip,
if (door=1 and @flip=1,least(@grpOutSeq:=0,1),7777) as dummy4,
if (door=1 and @flip=1,greatest(@grpInSeq:=1,0),7777) as dummy5,
if (door=1 and @flip!=1,greatest(@grpInSeq:example@sqldat.comnSeq+1,0),7777) as dummy6,
if (door=2 and @flip=1,least(@grpInSeq:=0,1),7777) as dummy7,
if (door=2 and @flip=1,greatest(@grpOutSeq:=1,0),7777) as dummy8,
if (door=2 and @flip!=1,greatest(@grpOutSeq:example@sqldat.com+1,0),7777) as dummy9,
@grpIn as grpIn,
@grpInSeq as grpInSeq,
@grpOut as grpOut,
@grpOutSeq as grpOutSeq,
@lastEvt:=door as lastEvt
from
( select id,`datetime` as dt,
CASE
WHEN Door='in' or Active_door='on' THEN 1
ELSE 2
END as door
from attendance2
order by id
) xD1 -- derived table #1
cross join (select @grpIn:=0,@grpInSeq:=0,@grpOut:=0,@grpOutSeq:=0,@lastEvt:=-1,@flip:=0) xParams
order by id
) xD2 -- derived table #2
order by id;
-- select * from oneLinersDetail;
truncate table oneLinersSummary; -- architect this depending on multi-user concurrency
insert oneLinersSummary (id,grpInSeq,grpOutSeq,checkIn,checkOut)
select distinct grpIn,null,null,null,null
from oneLinersDetail
order by grpIn;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpIn,max(grpInSeq) m
from oneLinersDetail
where door=1
group by grpIn
) d1
on d1.grpIn=ols.id
set ols.grpInSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpOut,max(grpOutSeq) m
from oneLinersDetail
where door=2
group by grpOut
) d1
on d1.grpOut=ols.id
set ols.grpOutSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=1 and old.grpIn=ols.id and old.grpInSeq=ols.grpInSeq
set ols.checkIn=old.dt;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=2 and old.grpOut=ols.id and old.grpOutSeq=ols.grpOutSeq
set ols.checkOut=old.dt;
-- select * from oneLinersSummary;
-- dump out the results
select id,checkIn,checkOut
from oneLinersSummary
order by id;
-- rows are left in those two tables (oneLinersDetail,oneLinersSummary)
END$$
DELIMITER ;
Test :
call fetchOneLiners();
+----+---------------------+---------------------+
| id | checkIn | checkOut |
+----+---------------------+---------------------+
| 1 | 2016-01-01 08:00:00 | 2016-01-01 09:00:00 |
| 2 | 2016-01-01 09:35:00 | 2016-01-01 16:00:00 |
+----+---------------------+---------------------+
C'est la fin de la réponse. Ce qui suit est pour la visualisation par un développeur des étapes qui ont conduit à la fin de la procédure stockée.
Des versions de développement qui ont mené jusqu'à la fin. Espérons que cela aide à la visualisation au lieu de simplement laisser tomber un morceau de code déroutant de taille moyenne.
Étape A
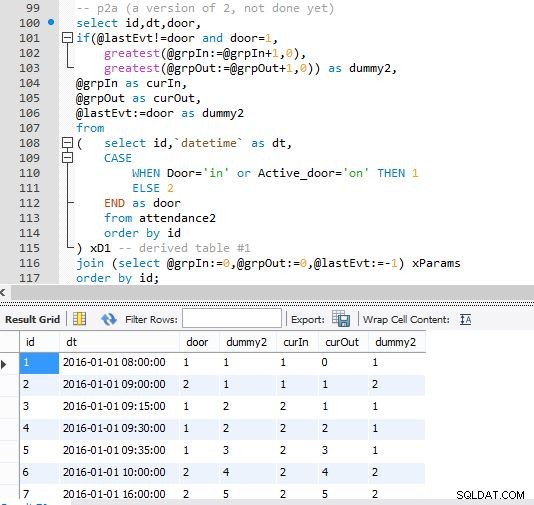
Étape B
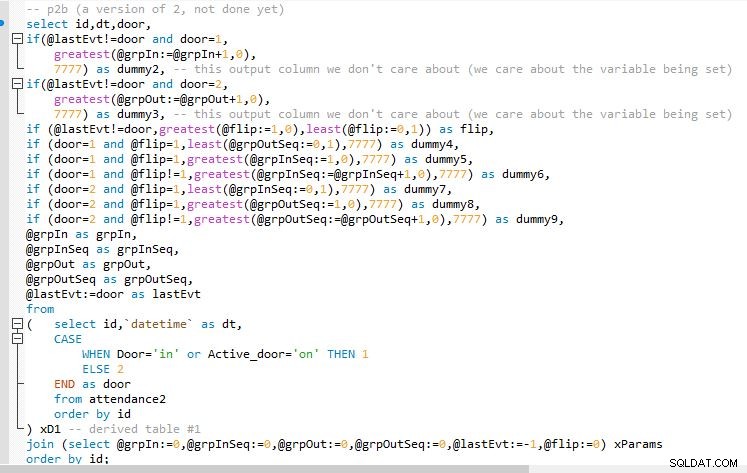
Résultat de l'étape B

Étape C
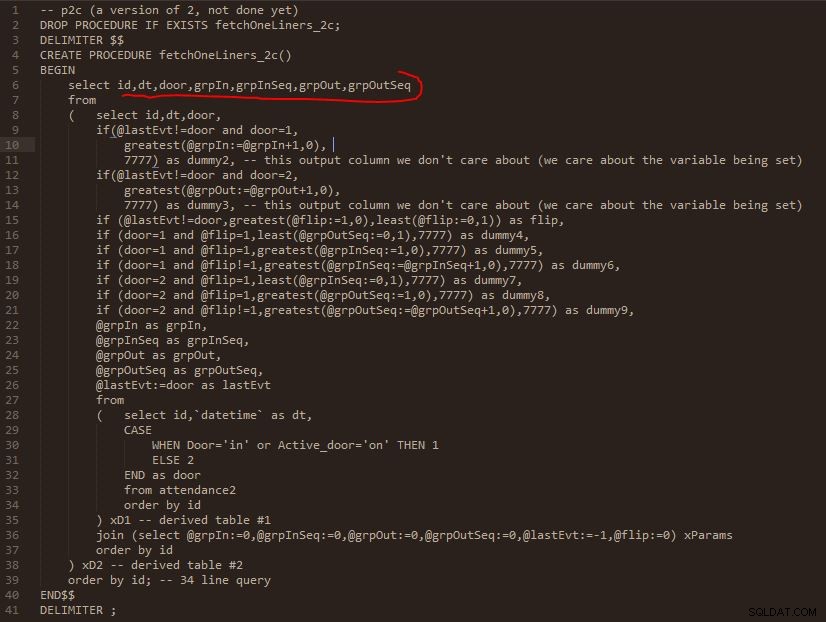
Résultat de l'étape C