La documentation
pour LAST_INSERT_ID() dit :
Sachant cela, vous pouvez en faire un processus en plusieurs étapes :
- INSÉRER IGNORER
- si LAST_INSERT_ID(), alors terminé (une nouvelle ligne a été insérée)
- else SELECT your_primary key FROM yourtable WHERE (contraintes UNIQUE de vos données insérées)
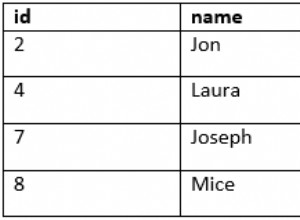
Exemple avec les États américains :
id | abbrev | other_data
1 | AL | ...
2 | AK |
UNIQUE KEY abbr (abbrev)
Maintenant, insérez une nouvelle ligne :
INSERT IGNORE INTO `states` (`abbrev`,`other_data`) VALUES ('AZ','foo bar');
> OK
SELECT LAST_INSERT_ID();
> "3"
// we have the ID, we're done
Insertion d'une ligne qui sera ignorée :
INSERT IGNORE INTO `states` (`abbrev`,`other_data`) VALUES ('AK','duplicate!');
> OK
SELECT LAST_INSERT_ID();
> "0"
// oops, it already exists!
SELECT id FROM `states` WHERE `abbrev` = 'AK'; // our UNIQUE constraint here
> "2"
// there we go!
Alternativement, il existe une solution de contournement possible pour le faire en une seule étape - utilisez REPLACE INTO au lieu de INSERT IGNORE INTO - la syntaxe est très similaire
. Notez cependant qu'il existe des effets secondaires avec cette approche - ceux-ci peuvent ou non être importants pour vous :
- REPLACE supprime + recrée la ligne
- donc les déclencheurs DELETE sont, euh, déclenchés
- également, l'ID principal sera incrémenté même si la ligne existe
INSERT IGNOREconserve les anciennes données de ligne,REPLACEle remplace par de nouvelles données de ligne