Mettre à jour :à partir de pandas 0.15, to_sql prend en charge l'écriture de NaN valeurs (elles seront écrites sous la forme NULL dans la base de données), la solution de contournement décrite ci-dessous ne devrait donc plus être nécessaire (voir https:// github.com/pydata/pandas/pull/8208
).
Pandas 0.15 sera publié en octobre prochain, et la fonctionnalité est fusionnée dans la version de développement.
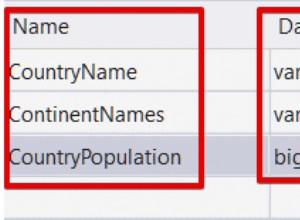
Ceci est probablement dû à NaN valeurs dans votre table, et c'est une lacune connue pour le moment que les fonctions pandas sql ne gèrent pas bien les NaN (https://github.com/pydata/pandas/issues/2754
, https://github.com/pydata/pandas/issues/4199
)
Comme solution de contournement pour le moment (pour les versions pandas 0.14.1 et inférieures), vous pouvez convertir manuellement le nan valeurs à Aucun avec :
df2 = df.astype(object).where(pd.notnull(df), None)
puis écrivez le dataframe dans sql. Cependant, cela convertit toutes les colonnes en type d'objet. Pour cette raison, vous devez créer la table de base de données en fonction de la trame de données d'origine. Par exemple, si votre première ligne ne contient pas NaN s :
df[:1].to_sql('table_name', con)
df2[1:].to_sql('table_name', con, if_exists='append')