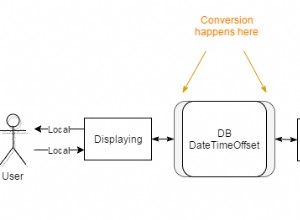
Les clusters suiveurs sont une fonctionnalité de ScaleGrid qui vous permet de synchroniser deux systèmes de base de données indépendants (du même type). Contrairement au clonage ou à la réplication, cela vous permet de conserver une copie active et ponctuelle de vos données de production. Ce cluster supplémentaire, appelé cluster suiveur, peut être utilisé pour plusieurs cas d'utilisation, notamment pour analyser, optimiser et tester les performances de votre application pour MongoDB, MySQL et PostgreSQL. Dans cet article de blog, nous couvrirons les trois principaux scénarios pour tirer parti des clusters de suiveurs pour votre application.
En quoi les clusters suiveurs diffèrent-ils de la réplication ?
Contrairement à un clone statique, ces données sont importées selon un calendrier défini afin que votre cluster suiveur soit toujours synchronisé avec votre cluster de production. Voici quelques différences essentielles par rapport à la réplication :
- Vous pouvez contrôler la fréquence à laquelle le système de destination se synchronise à partir de la source :une fois par semaine, une fois par jour ou même moins fréquemment. Cela permet de réduire la charge sur le système source.
- Puisqu'il s'agit de deux systèmes indépendants, vous bénéficiez d'une plus grande flexibilité concernant les données synchronisées. Vous pouvez avoir différentes informations d'identification utilisateur et même supprimer certaines données de la destination en fonction des exigences de sécurité (remarque :cela nécessite un script côté utilisateur - ce n'est pas une fonctionnalité intégrée des clusters suiveurs).
- Le système "suiveur" est accessible en écriture, vous pouvez donc l'utiliser comme environnement intermédiaire pour tester les modifications apportées à votre application. Ce n'est pas quelque chose que vous pouvez faire sur un nœud de réplique.
Remarque :ScaleGrid implémente des clusters suiveurs à l'aide d'instantanés de stockage. Il n'est pas disponible pour nos offres de base de données en mémoire comme l'hébergement pour Redis™*.
1. Configuration du développement/test de la base de données
Nous sommes tous passés par là :un morceau de code soi-disant bien testé est déployé en production, puis l'enfer se déchaîne. Les workflows de production échouent ou sont si lents qu'ils sont pratiquement inutilisables. Les ingénieurs sont réveillés de leur lit pour lancer une opération complète de lutte contre l'incendie. Un tas de nuits blanches plus tard, cette cause profonde redoutée émerge.
L'application se comporte différemment sur les configurations de production et d'ingénierie.
En d'autres termes, nous l'avons testé sur des "données de test". Ce qui, en fin de compte, n'avait rien à voir avec les données de production. Du tout.
Le moyen évident d'éviter cette situation consiste à exécuter des tests sur vos données de production. Pas la production réelle bien sûr – cela flirtera avec le désastre. Sur une copie clonée des données de production. Bien que les préoccupations concernant la confidentialité et la sécurité des données rendent cela impossible dans de nombreux scénarios, si les exigences de confidentialité le permettent, il s'agit de la meilleure solution. Nous n'avons plus besoin de compter sur les ingénieurs pour générer des ensembles de données appropriés :s'il transmet des données de test, il transmettra des données de production.
En d'autres termes, jusqu'à ce que les données de test ne soient pas suffisamment synchronisées avec la production, elles ne constituent plus une bonne approximation. Et nous sommes de retour à la case départ.
C'est là qu'interviennent les clusters suiveurs.
En utilisant des clusters suiveurs, vous pouvez périodiquement importer des données de votre base de données de production dans la base de données de développement/test. Et comme l'intégralité de l'importation est effectuée à l'aide d'instantanés de stockage, plutôt que d'un vidage logique, le processus est presque instantané. Vous pouvez programmer vos importations une fois toutes les 24 heures, une fois par semaine ou selon la fréquence qui convient à votre scénario particulier.
Avec vos clusters de développement et d'assurance qualité configurés pour suivre le cluster de production, vous pouvez dormir tranquille. Si votre application réussit l'ensemble de données de test, elle est définitivement apte à être déployée en production !
2. Analyse des données
Si vous avez travaillé en tant que DBA, vous avez probablement eu une conversation avec votre équipe au sujet du ralentissement « mystérieux » des performances du système à certains moments. Dans la plupart des cas, le coupable s'avère être un travail d'analyse qui accède à des tonnes de données et finit par ralentir l'ensemble du système.
En tant que fournisseur DBaaS, nous avons eu cette conversation à plusieurs reprises avec nos clients. Voici les deux options que nous suggérons généralement :
- Si la tâche d'analyse s'exécute sur le serveur principal/maître, déplacez-la vers un serveur secondaire/réplica.
- Si la tâche d'analyse est déjà en cours d'exécution sur un nœud secondaire et que la dégradation des performances est inacceptable, nous vous recommandons de déplacer les tâches vers un cluster d'analyse dédié.
Grâce à notre fonctionnalité de cluster suiveur, il est très facile de maintenir un cluster d'analyse à jour avec les données de production réelles. Vous pouvez créer un calendrier suiveur pour synchroniser les dernières données de production juste avant le début de votre travail d'analyse.
La meilleure partie ? La synchronisation des suiveurs n'effectue aucune opération au niveau de la base de données - elle restaure simplement le dernier instantané ! Il n'y a donc aucun impact sur votre cluster de production.
3. Rapport
Un autre cas d'utilisation courant où nos clients utilisent la fonctionnalité de clusters suiveurs est la génération de rapports. Les processus de génération de rapports s'exécutent généralement peu fréquemment, mais accèdent à de grandes quantités de données et occupent la plupart des ressources d'un cluster de bases de données. Lorsque la dégradation des performances est inacceptable, nous recommandons à nos clients de déplacer la charge de travail de création de rapports vers un nouveau cluster.
Étant donné que les opérations de création de rapports sont peu fréquentes, bon nombre de nos clients préfèrent tirer parti de notre fonction de pause/reprise pour mettre en pause les clusters de création de rapports lorsqu'ils ne sont pas utilisés. Cela permet d'économiser massivement sur les coûts d'infrastructure. En règle générale, les clusters de création de rapports sont également beaucoup plus "petits" (moins de CPU/RAM), pour aider à réduire les coûts.
Après avoir créé un cluster de suiveurs à partir de notre interface utilisateur, vous pouvez utiliser ce flux de travail pour automatiser votre flux de création de rapports :
- Utilisez notre API de reprise pour reprendre le cluster.
- Attendez que le cluster soit de nouveau en état d'exécution (vous pouvez utiliser votre API get-status à cette fin).
- Déclenchez une sauvegarde sur votre cluster de production, si nécessaire (généralement, si des sauvegardes régulières sont planifiées sur votre production, vous pouvez ignorer cette étape. Toutefois, si vous souhaitez que vos rapports s'exécutent sur les données les plus récentes, cela est essentiel).
- Attendez que la sauvegarde soit terminée.
- Déclencher une tâche de synchronisation sur le suiveur :cela trouve le dernier instantané sur le cluster source et le restaure vers la destination.
- Attendez la fin de la tâche de synchronisation.
- Exécutez vos tâches de création de rapports.
- Utilisez notre API de pause pour suspendre le cluster jusqu'à votre prochaine tâche de création de rapports !
Pensez-vous que les clusters d'abonnés conviennent à votre cas d'utilisateur particulier ? Vous pouvez tout savoir sur le déploiement et la gestion des clusters suiveurs pour MongoDB, MySQL et PostgreSQL dans nos documents d'aide !
Si vous ne savez pas si les clusters de suiveurs sont la bonne solution pour votre cas d'utilisation, laissez un commentaire ou contactez-nous à support@scalegrid.io - nous sont heureux de discuter de la fonctionnalité qui correspond le mieux à vos besoins.