Auparavant, nous avons publié un blog sur la réalisation du basculement et du rétablissement de MySQL sur Google Cloud Platform (GCP). Dans ce blog, nous verrons comment son rival, Amazon Relational Database Service (RDS), gère le basculement. Nous verrons également comment vous pouvez effectuer un rétablissement de votre ancien nœud maître, en le ramenant à son ordre d'origine en tant que maître.
En comparant les clouds publics géants de la technologie qui prennent en charge les services de bases de données relationnelles gérées, Amazon est le seul à proposer une option alternative (avec MySQL/MariaDB, PostgreSQL, Oracle et SQL Server) pour fournir son propre type de gestion de base de données appelé Amazon Aurora. Pour ceux qui ne connaissent pas Aurora, il s'agit d'un moteur de base de données relationnelle entièrement géré compatible avec MySQL et PostgreSQL. Aurora fait partie du service de base de données géré Amazon RDS, un service Web qui facilite la configuration, l'exploitation et la mise à l'échelle d'une base de données relationnelle dans le cloud.
Pourquoi auriez-vous besoin d'un basculement ou d'un rétablissement ?
La conception d'un grand système tolérant aux pannes, hautement disponible, sans point de défaillance unique (SPOF) nécessite des tests appropriés pour déterminer comment il réagirait en cas de problème.
Si vous êtes préoccupé par les performances de votre système lors de la réponse à la détection, à l'isolement et à la récupération des pannes (FDIR) de votre système, le basculement et le retour arrière doivent être d'une grande importance.
Basculement de base de données dans Amazon RDS
Le basculement se produit automatiquement (car le basculement manuel est appelé basculement). Comme indiqué dans un blog précédent, le besoin de basculement se produit une fois que votre maître de base de données actuel subit une panne de réseau ou un arrêt anormal du système hôte. Le basculement le bascule vers un état de redondance stable ou vers un serveur, un système, un composant matériel ou un réseau de secours.
Dans Amazon RDS, vous n'avez pas besoin de le faire, ni de le surveiller vous-même, car RDS est un service de base de données géré (ce qui signifie qu'Amazon gère le travail pour vous). Ce service gère des éléments tels que les problèmes matériels, la sauvegarde et la récupération, les mises à jour logicielles, les mises à niveau de stockage et même les correctifs logiciels. Nous en reparlerons plus tard dans ce blog.
Rétablissement de base de données dans Amazon RDS
Dans le blog précédent, nous avons également expliqué pourquoi vous auriez besoin d'une restauration automatique. Dans un environnement répliqué typique, le maître doit être suffisamment puissant pour supporter une charge énorme, en particulier lorsque la charge de travail requise est élevée. Votre configuration principale nécessite des spécifications matérielles adéquates pour garantir qu'elle peut traiter les écritures, générer des événements de réplication, traiter les lectures critiques, etc., de manière stable. Lorsqu'un basculement est requis pendant la reprise après sinistre (ou pour la maintenance), il n'est pas rare que lors de la promotion d'un nouveau maître, vous utilisiez du matériel de qualité inférieure. Cette situation peut être acceptable temporairement, mais à long terme, le maître désigné doit être ramené pour diriger la réplication une fois qu'il est jugé sain (ou que la maintenance est terminée).
Contrairement au basculement, les opérations de restauration se produisent généralement dans un environnement contrôlé en utilisant le basculement. C'est rarement fait en mode panique. Cette approche donne à vos ingénieurs suffisamment de temps pour planifier soigneusement et répéter l'exercice afin d'assurer une transition en douceur. Son objectif principal est simplement de ramener le bon ancien maître au dernier état et de restaurer la configuration de réplication à sa topologie d'origine. Puisque nous traitons avec Amazon RDS, vous n'avez vraiment pas besoin de vous préoccuper outre mesure de ce type de problèmes, car il s'agit d'un service géré dont la plupart des tâches sont gérées par Amazon.
Comment Amazon RDS gère-t-il le basculement de base de données ?
Lors du déploiement de vos nœuds Amazon RDS, vous pouvez configurer votre cluster de base de données avec une zone de disponibilité multiple (AZ) ou une zone de disponibilité unique. Vérifions chacun d'eux sur la façon dont le basculement est traité.
Qu'est-ce qu'une configuration multi-AZ ?
Lorsqu'une catastrophe ou un sinistre se produit, comme des pannes imprévues ou des catastrophes naturelles affectant vos instances de base de données, Amazon RDS bascule automatiquement vers un réplica de secours dans une autre zone de disponibilité. Cette AZ se trouve généralement dans une autre branche du centre de données, souvent loin de la zone de disponibilité actuelle où se trouvent les instances. Ces AZ sont des installations de pointe hautement disponibles protégeant vos instances de base de données. Les temps de basculement dépendent de l'achèvement de la configuration qui est souvent basée sur la taille et l'activité de la base de données ainsi que sur d'autres conditions présentes au moment où l'instance de base de données principale est devenue indisponible.
Les délais de basculement sont généralement de 60 à 120 secondes. Cependant, ils peuvent être plus longs, car des transactions volumineuses ou un long processus de récupération peuvent augmenter le temps de basculement. Une fois le basculement terminé, la console RDS (UI) peut également prendre plus de temps pour refléter la nouvelle zone de disponibilité.
Qu'est-ce qu'une configuration mono-AZ ?
Les configurations Single-AZ ne doivent être utilisées pour vos instances de base de données que si votre RTO (Recovery Time Objective) et RPO (Recovery Point Objective) sont suffisamment élevés pour le permettre. L'utilisation d'un Single-AZ comporte des risques, tels que des temps d'arrêt importants qui pourraient perturber les opérations commerciales.
Scénarios d'échec RDS courants
Le temps d'arrêt dépend du type de panne. Passons en revue ce qu'ils sont et comment la récupération de l'instance est gérée.
Échec de l'instance récupérable
Une défaillance d'instance Amazon RDS se produit lorsque l'instance EC2 sous-jacente subit une défaillance. En cas d'occurrence, AWS déclenchera une notification d'événement et vous enverra une alerte à l'aide des notifications d'événement Amazon RDS. Ce système utilise AWS Simple Notification Service (SNS) comme processeur d'alerte.
RDS essaiera automatiquement de lancer une nouvelle instance dans la même zone de disponibilité, d'attacher le volume EBS et de tenter une récupération. Dans ce scénario, le RTO est généralement inférieur à 30 minutes. Le RPO est nul car le volume EBS a pu être récupéré. Le volume EBS se trouve dans une seule zone de disponibilité et ce type de récupération se produit dans la même zone de disponibilité que l'instance d'origine.
Échecs d'instance non récupérables ou échecs de volume EBS
En cas d'échec de la récupération d'instance RDS (ou si le volume EBS sous-jacent subit une défaillance de perte de données), une récupération ponctuelle (PITR) est requise. PITR n'est pas automatiquement géré par Amazon, vous devez donc soit créer un script pour l'automatiser (à l'aide d'AWS Lambda), soit le faire manuellement.
Le minutage RTO nécessite le démarrage d'une nouvelle instance Amazon RDS, qui aura un nouveau nom DNS une fois créé, puis l'application de toutes les modifications depuis la dernière sauvegarde.
Le RPO est généralement de 5 minutes, mais vous pouvez le trouver en appelant RDS:describe-db-instances:LatestRestorableTime. Le temps peut varier de 10 minutes à plusieurs heures selon le nombre de bûches à appliquer. Il ne peut être déterminé que par des tests car il dépend de la taille de la base de données, du nombre de modifications apportées depuis la dernière sauvegarde et des niveaux de charge de travail sur la base de données. Étant donné que les sauvegardes et les journaux de transactions sont stockés dans Amazon S3, cette récupération peut se produire dans n'importe quelle zone de disponibilité prise en charge dans la région.
Une fois la nouvelle instance créée, vous devrez mettre à jour le nom du point de terminaison de votre client. Vous avez également la possibilité de le renommer avec le nom du point de terminaison de l'ancienne instance de base de données (mais cela vous oblige à supprimer l'ancienne instance défaillante), mais cela rend impossible la détermination de la cause première du problème.
Perturbations de la zone de disponibilité
Les perturbations de la zone de disponibilité peuvent être temporaires et sont rares, cependant, si l'échec AZ est plus permanent, l'instance sera définie sur un état d'échec. La récupération fonctionnerait comme décrit précédemment et une nouvelle instance pourrait être créée dans une AZ différente, à l'aide de la récupération ponctuelle. Cette étape doit être effectuée manuellement ou par script. La stratégie pour ce type de scénario de récupération doit faire partie de vos plans de reprise après sinistre (DR) plus larges.
Si l'échec de la zone de disponibilité est temporaire, la base de données sera arrêtée mais restera dans l'état disponible. Vous êtes responsable de la surveillance au niveau de l'application (à l'aide d'outils d'Amazon ou de tiers) pour détecter ce type de scénario. Si cela se produit, vous pouvez attendre que la zone de disponibilité récupère, ou vous pouvez choisir de récupérer l'instance dans une autre zone de disponibilité avec une récupération ponctuelle.
Le RTO serait le temps nécessaire pour démarrer une nouvelle instance RDS, puis appliquer toutes les modifications depuis la dernière sauvegarde. Le RPO peut être plus long, jusqu'au moment où l'échec de la zone de disponibilité s'est produit.
Test du basculement et du rétablissement sur Amazon RDS
Nous avons créé et configuré un Amazon RDS Aurora à l'aide de db.r4.large avec un déploiement multi-AZ (qui créera un réplica/lecteur Aurora dans un autre AZ) accessible uniquement via EC2. Vous devrez vous assurer de choisir cette option lors de la création si vous avez l'intention d'utiliser Amazon RDS comme mécanisme de basculement.
Lors du provisionnement de notre instance RDS, il a fallu environ 11 minutes avant les instances sont devenues disponibles et accessibles. Ci-dessous une capture d'écran des nœuds disponibles dans RDS après la création :
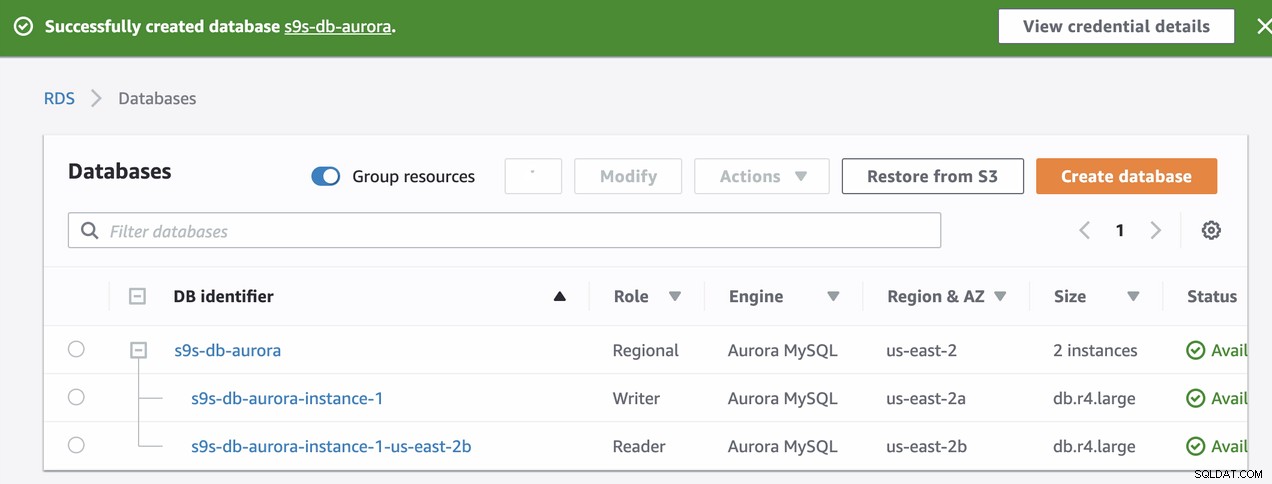
Ces deux nœuds auront leurs propres noms de point de terminaison désignés, que nous allons utiliser pour se connecter du point de vue du client. Vérifiez-le d'abord et vérifiez le nom d'hôte sous-jacent pour chacun de ces nœuds. Pour vérifier, vous pouvez exécuter cette commande bash ci-dessous et simplement remplacer les noms d'hôtes/endpoints en conséquence :
example@sqldat.com:~# host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done;
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Le résultat clarifie comme suit,
s9s-db-aurora-instance-1 = s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-0-94 (read-write)
s9s-db-aurora-instance-1-us-east-2b = s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-1-139 (read-only)Simulation du basculement Amazon RDS
Maintenant, simulons un plantage pour simuler un basculement pour l'instance d'écriture Amazon RDS Aurora, qui est s9s-db-aurora-instance-1 avec le point de terminaison s9s-db-aurora.cluster-cmu8qdlvkepg.us -east-2.rds.amazonaws.com.
Pour ce faire, connectez-vous à votre instance de rédacteur à l'aide de l'invite de commande du client mysql, puis émettez la syntaxe ci-dessous :
ALTER SYSTEM SIMULATE percentage_of_failure PERCENT DISK FAILURE [ IN DISK index | NODE index ]
FOR INTERVAL quantity [ YEAR | QUARTER | MONTH | WEEK| DAY | HOUR | MINUTE | SECOND ];L'émission de cette commande a sa détection de récupération Amazon RDS et agit assez rapidement. Bien que la requête soit à des fins de test, elle peut différer lorsque cette occurrence se produit dans un événement factuel. Vous pourriez être intéressé d'en savoir plus sur le test d'un crash d'instance dans leur documentation. Découvrez comment nous nous retrouvons ci-dessous :
mysql> ALTER SYSTEM SIMULATE 100 PERCENT DISK FAILURE FOR INTERVAL 3 MINUTE;
Query OK, 0 rows affected (0.01 sec)L'exécution de la commande SQL ci-dessus signifie qu'elle doit simuler une panne de disque pendant au moins 3 minutes. J'ai surveillé le moment pour commencer la simulation et il a fallu environ 18 secondes avant que le basculement ne commence.
Voir ci-dessous comment RDS gère l'échec de la simulation et le basculement,
Tue Sep 24 10:06:29 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
….
…..
………..
Tue Sep 24 10:06:44 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
……..
………..
Tue Sep 24 10:06:51 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
….
………..
…………………
Tue Sep 24 10:07:13 UTC 2019
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Les résultats de cette simulation sont assez intéressants. Prenons celui-ci à la fois.
- Vers 10:06:29, j'ai commencé à exécuter la requête de simulation comme indiqué ci-dessus.
- Vers 10:06:44, cela indique que le point de terminaison s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com avec le nom d'hôte attribué ip-10-20-1- 139 où il s'agit en fait de l'instance en lecture seule, est devenu inaccessible néanmoins que la commande de simulation a été exécutée sous l'instance en lecture-écriture.
- Vers 10:06:51, il montre que le point de terminaison s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com avec le nom d'hôte attribué ip-10-20-1- 139 est activé mais il a la marque comme état de lecture-écriture. Notez que la variable innodb_read_only, pour les instances gérées Aurora MySQL, est son identifiant pour déterminer si l'hôte est un nœud en lecture-écriture ou en lecture seule et Aurora s'exécute également uniquement sur le moteur de stockage InnoDB pour les instances MySQL comptables.
- Vers 10:07:13, l'ordre a changé. Cela signifie que le basculement a été effectué et que les instances ont été attribuées à ses points de terminaison désignés.
Consultez le résultat ci-dessous qui s'affiche dans la console RDS :
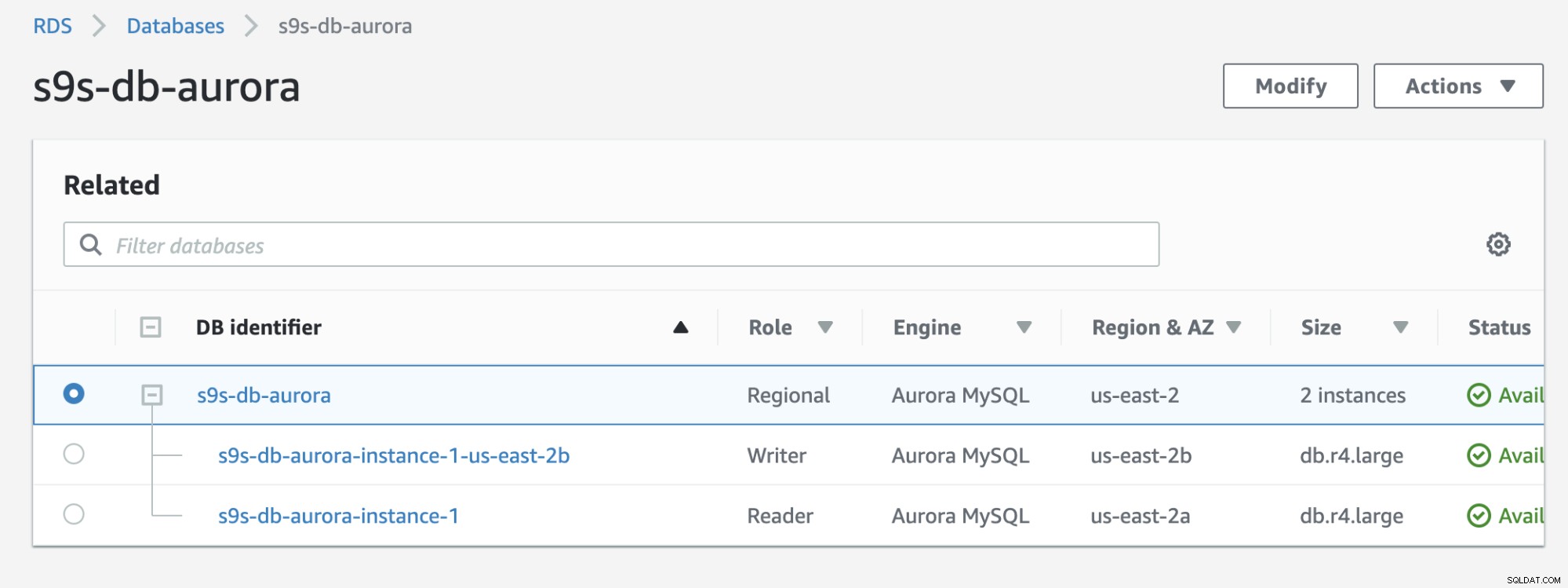
Si vous comparez au précédent, le s9s-db-aurora- instance-1 était un lecteur, mais a ensuite été promu en tant qu'écrivain après le basculement. Le processus, y compris le test, a pris environ 44 secondes pour terminer la tâche, mais le basculement s'affiche en près de 30 secondes. C'est impressionnant et rapide pour un basculement, d'autant plus qu'il s'agit d'une base de données de services gérés ; ce qui signifie que vous n'avez pas à vous soucier des problèmes de matériel ou de maintenance.
Exécution d'une restauration automatique dans Amazon RDS
La restauration automatique dans Amazon RDS est assez simple. Avant de le parcourir, ajoutons une nouvelle réplique de lecteur. Nous avons besoin d'une option pour tester et identifier le nœud qu'AWS RDS choisirait lorsqu'il essaie de revenir au maître souhaité (ou de revenir au maître précédent) et de voir s'il sélectionne le bon nœud en fonction de la priorité. La liste actuelle des instances à ce jour et ses points de terminaison sont présentés ci-dessous.
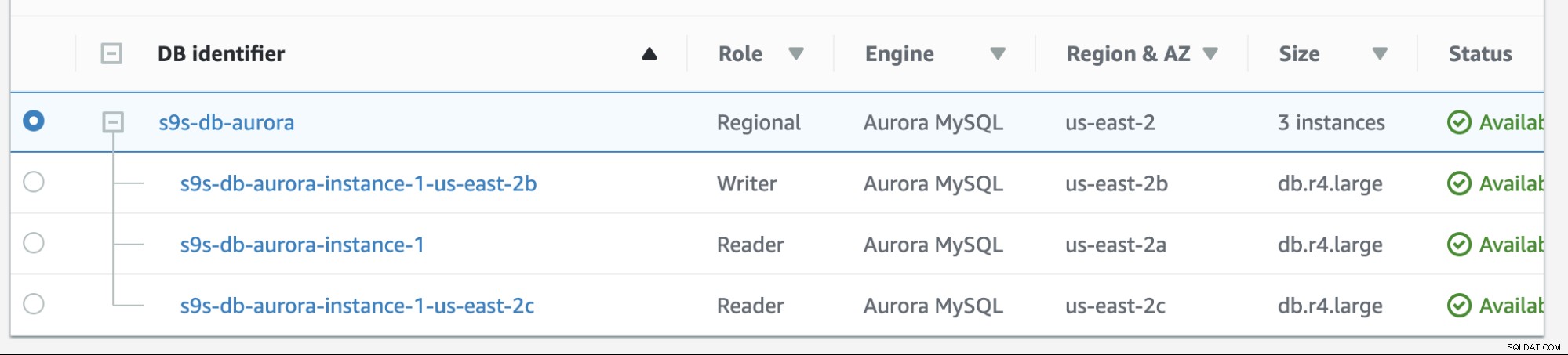

Le nouveau réplica est situé sur us-east-2c AZ avec le nom d'hôte db de ip-10-20-2-239.
Nous tenterons d'effectuer une restauration en utilisant l'instance s9s-db-aurora-instance-1 comme cible de restauration souhaitée. Dans cette configuration, nous avons deux instances de lecteur. Afin de garantir que le nœud correct est sélectionné lors du basculement, vous devrez déterminer si la priorité ou la disponibilité est prioritaire (niveau 0 > niveau 1 > niveau 2, etc. jusqu'au niveau 15). Cela peut être fait en modifiant l'instance ou lors de la création de la réplique.
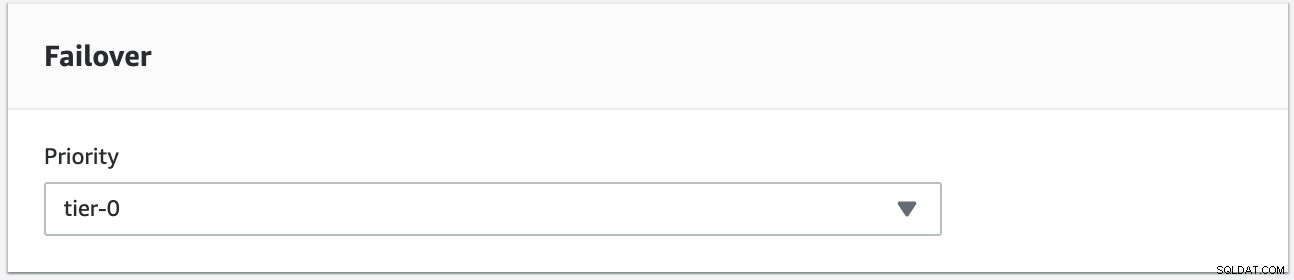
Vous pouvez vérifier cela dans votre console RDS.
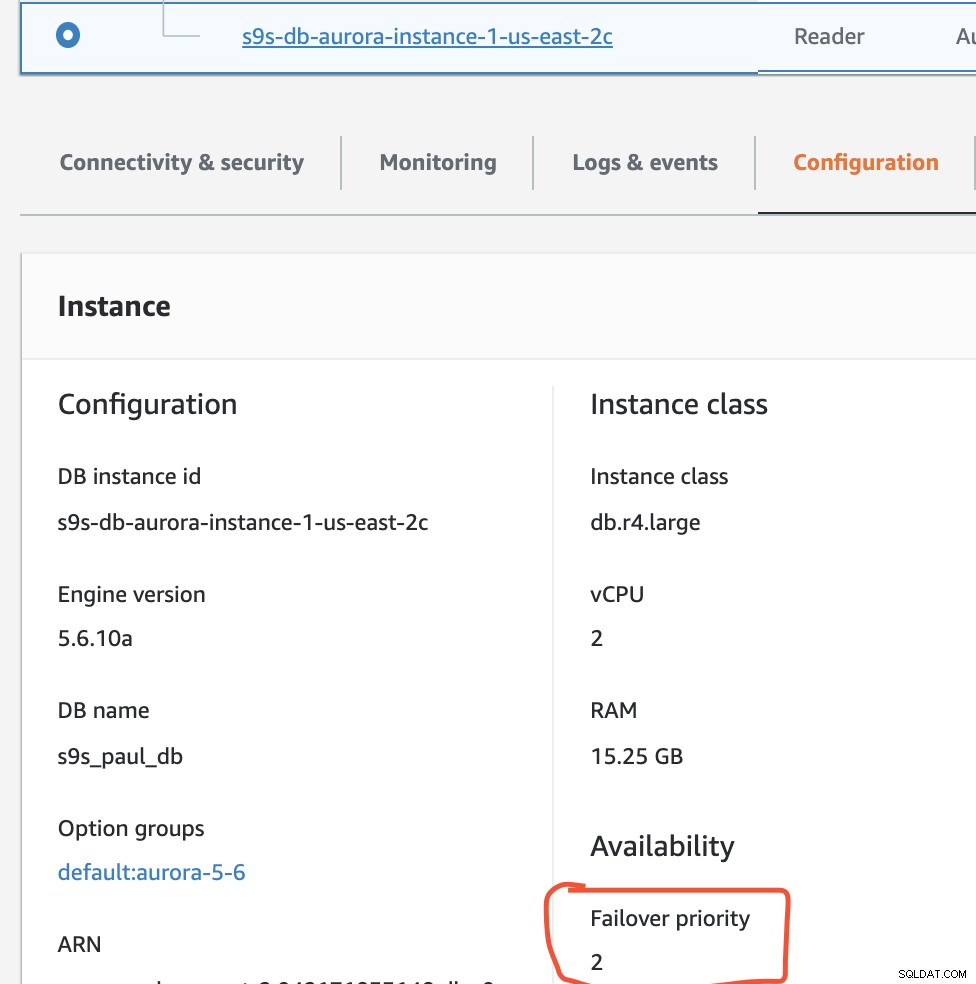
Dans cette configuration, s9s-db-aurora-instance-1 a la priorité =0 (et est un réplica en lecture), s9s-db-aurora-instance-1-us-east-2b a la priorité =1 (et est l'écrivain actuel) et s9s-db-aurora-instance-1-us- east-2c a la priorité =2 (et est également une réplique en lecture). Voyons ce qui se passe lorsque nous essayons de revenir en arrière.
Vous pouvez surveiller l'état en utilisant cette commande.
$ host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); while true; do echo -e "\n==========================================="; date; echo -e "===========================================\n"; for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done; sleep 1; done;Une fois le basculement déclenché, il reviendra à notre cible souhaitée, qui est le nœud s9s-db-aurora-instance-1.
===========================================
Tue Sep 24 13:30:59 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
…
……
………
===========================================
Tue Sep 24 13:31:35 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
…..
===========================================
Tue Sep 24 13:31:38 UTC 2019
===========================================
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+La tentative de rétablissement a commencé à 13:30:59 et s'est terminée vers 13:31:38 (la marque la plus proche de 30 secondes). Cela prend environ 32 secondes sur ce test, qui est toujours rapide.
J'ai vérifié le basculement/retour arrière plusieurs fois et il a constamment échangé son état de lecture-écriture entre les instances s9s-db-aurora-instance-1 et s9s-db-aurora-instance-1- nous-est-2b. Cela laisse s9s-db-aurora-instance-1-us-east-2c non sélectionné à moins que les deux nœuds ne rencontrent des problèmes (ce qui est très rare car ils sont tous situés dans des AZ différentes).
Pendant les tentatives de basculement/retour arrière, RDS passe à un rythme de transition rapide pendant le basculement à environ 15 - 25 secondes (ce qui est très rapide). Gardez à l'esprit que nous n'avons pas d'énormes fichiers de données stockés sur cette instance, mais c'est quand même assez impressionnant étant donné qu'il n'y a rien d'autre à gérer.
Conclusion
L'exécution d'un Single-AZ présente un danger lors de l'exécution d'un basculement. Amazon RDS vous permet de modifier et de convertir votre Single-AZ en une configuration compatible Multi-AZ, bien que cela vous coûtera plus cher. Single-AZ peut convenir si vous êtes d'accord avec un temps RTO et RPO plus élevé, mais n'est certainement pas recommandé pour les applications professionnelles critiques à fort trafic.
Avec Multi-AZ, vous pouvez automatiser le basculement et la restauration automatique sur Amazon RDS, en passant votre temps à vous concentrer sur le réglage ou l'optimisation des requêtes. Cela atténue de nombreux problèmes rencontrés par les DevOps ou les DBA.
Bien qu'Amazon RDS puisse poser un dilemme dans certaines organisations (car il n'est pas indépendant de la plate-forme), il mérite tout de même d'être pris en considération ; surtout si votre application nécessite un plan de reprise après sinistre à long terme et que vous ne voulez pas perdre de temps à vous soucier de la planification du matériel et de la capacité.