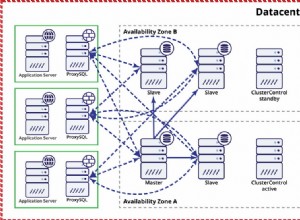
Ce qui suit est un extrait de notre livre blanc "Comment concevoir des environnements de base de données Open Source hautement disponibles" qui peut être téléchargé gratuitement.
Quelques mots sur la "haute disponibilité"
De nos jours, la haute disponibilité est indispensable pour tout déploiement sérieux. L'époque où vous pouviez programmer une interruption de votre base de données pendant plusieurs heures pour effectuer une maintenance est révolue depuis longtemps. Si vos services ne sont pas disponibles, vous perdez des clients et de l'argent. Par conséquent, rendre un environnement de base de données hautement disponible est généralement l'une des priorités les plus élevées.
Cela pose un défi important aux administrateurs de bases de données. Tout d'abord, comment savoir si votre environnement est hautement disponible ou non ? Comment le mesureriez-vous ? Quelles sont les étapes à suivre pour améliorer la disponibilité ? Comment concevoir votre configuration pour la rendre hautement disponible dès le début ?
Il existe de nombreuses solutions HA disponibles dans l'écosystème MySQL (et MariaDB), mais comment savoir à quelles solutions nous pouvons faire confiance ? Certaines solutions peuvent fonctionner dans certaines conditions spécifiques, mais peuvent causer plus de problèmes lorsqu'elles sont appliquées en dehors de ces conditions. Même une fonctionnalité de base comme la réplication MySQL, qui peut être configurée de plusieurs manières, peut causer des dommages importants - par exemple, la réplication circulaire avec plusieurs maîtres inscriptibles. Bien qu'il soit facile de mettre en place une "configuration multi-maître" à l'aide de la réplication, elle peut très facilement casser et nous laisser avec des ensembles de données divergents sur différents serveurs. Pour une base de données, qui est souvent considérée comme la seule source de vérité, une intégrité compromise des données peut avoir des conséquences catastrophiques.
Dans les chapitres suivants, nous discuterons des exigences de haute disponibilité dans les configurations de base de données
et de la manière de concevoir le système à partir de zéro.
Mesurer la haute disponibilité
Qu'est-ce que la haute disponibilité ? Pour pouvoir décider si un environnement donné est hautement disponible ou non, il faut disposer de métriques pour cela. Il existe de nombreuses façons de mesurer la haute disponibilité, nous nous concentrerons sur certaines des choses les plus élémentaires.
Mais d'abord, réfléchissons à quoi consiste toute cette haute disponibilité ? Quel est son but? Il s'agit de s'assurer que votre environnement sert son objectif. Le but peut être défini de plusieurs façons mais, généralement, il s'agira de fournir un service. Dans le monde des bases de données, c'est généralement quelque peu lié aux données. Il pourrait servir des données à votre application interne. Il peut s'agir de stocker des données et de les rendre interrogeables par des processus analytiques. Il peut s'agir de stocker certaines données pour vos utilisateurs et de les fournir sur demande à la demande. Une fois que nous sommes clairs sur le but, nous pouvons établir les facteurs de succès impliqués. Cela nous aidera à définir ce que signifie la haute disponibilité dans notre cas spécifique.
SLA
Contrat de niveau de service (SLA). Il est également assez courant de définir des SLA pour les services internes. Qu'est-ce qu'un SLA ? Il s'agit d'une définition du niveau de service que vous envisagez de fournir à vos clients. Il s'agit pour eux de mieux comprendre quel niveau de stabilité vous envisagez pour un service qu'ils ont acheté ou envisagent d'acheter. Il existe de nombreuses méthodes que vous pouvez utiliser pour préparer un SLA, mais les plus typiques sont :
- Disponibilité du service (pourcentage)
- Réactivité du service :latence (moyenne, maximale, 95 centile, 99 centile)
- Perte de paquets sur le réseau (pourcentage)
- Débit (moyen, minimum, 95 centile, 99 centile)
Cela peut cependant devenir plus complexe que cela. Dans un environnement partagé et multi-utilisateurs, vous pouvez définir, disons, votre SLA comme :"Le service sera disponible 99,99 % du temps, un temps d'arrêt est déclaré lorsque plus de 2 % des utilisateurs sont concernés. Aucun incident ne peut prendre plus de 15 minutes pour être résolu ». Ce SLA peut également être étendu pour intégrer le temps de réponse aux requêtes :"le temps d'arrêt est appelé si le 99 centile de latence pour les requêtes dépasse 200 ms".
Neuf
La disponibilité est généralement mesurée en «neuf», examinons ce qu'exactement une quantité donnée de «neuf» garantit. Le tableau ci-dessous est extrait de Wikipédia :
| % de disponibilité | Temps d'indisponibilité par an | Temps d'indisponibilité par mois | Temps d'indisponibilité par semaine | Temps d'indisponibilité par jour |
|---|---|---|---|---|
| 90 % ("un neuf") | 36,5 jours | 72 heures | 16,8 heures | 2,4 heures |
| 95 % ("un neuf et demi") | 18,25 jours | 36 heures | 8,4 heures | 1,2 heure |
| 97 % | 10,96 jours | 21,6 heures | 5,04 heures | 43,2 minutes |
| 98 % | 7,30 jours | 14,4 heures | 3,36 heures | 28,8 minutes |
| 99 % ("deux neuf") | 3,65 jours | 7h20 | 1,68 heure | 14,4 minutes |
| 99,5 % ("deux neuf et demi") | 1,83 jours | 3,60 heures | 50,4 minutes | 7,2 minutes |
| 99,8 % | 17,52 heures | 86,23 minutes | 20.16 min | 2,88 minutes |
| 99,9 % ("trois neuf") | 8,76 heures | 43,8 minutes | 10,1 minutes | 1,44 min |
| 99,95 % ("trois neuf et demi") | 4,38 heures | 21,56 minutes | 5,04 minutes | 43,2 s |
| 99,99 % ("quatre neuf") | 52,56 minutes | 4,38 minutes | 1.01 min | 8,64 s |
| 99,995 % ("quatre neuf et demi") | 26,28 minutes | 2,16 minutes | 30,24 s | 4,32 s |
| 99,999 % ("cinq neuf") | 5,26 minutes | 25,9 s | 6,05 s | 864,3 ms |
| 99,9999 % ("six neuf") | 31,5 s | 2,59 s | 604,8 ms | 86,4 ms |
| 99,99999 % ("sept neuf") | 3,15 s | 262,97 ms | 60,48 ms | 8,64 ms |
| 99,999999 % ("huit neuf") | 315,569 ms | 26,297 ms | 6,048 ms | 0,864 ms |
| 99,9999999 % ("neuf neuf") | 31,5569 ms | 2,6297 ms | 0,6048 ms | 0,0864 ms |
Comme on peut le voir, ça dégénère rapidement. Cinq neuf (disponibilité à 99 999 %) équivaut à 5,26 minutes d'indisponibilité au cours d'une année. La disponibilité peut également être calculée dans différentes plages plus petites :par mois, par semaine, par jour. Gardez ces chiffres à l'esprit, car ils seront utiles lorsque nous commencerons à discuter des coûts associés au maintien de différents niveaux de disponibilité.
Mesurer la disponibilité
Pour dire s'il y a un temps d'arrêt ou non, il faut avoir un aperçu de l'environnement. Vous devez suivre les métriques qui définissent la disponibilité de vos systèmes. Il est important de garder à l'esprit que vous devez le mesurer du point de vue d'un client, en prenant en considération l'image plus large. Peu importe si vos bases de données sont actives si, disons, en raison d'un problème de réseau, aucune application ne peut les atteindre. Chaque élément constitutif de votre configuration a son impact sur la disponibilité.
L'un des bons endroits où rechercher des données de disponibilité est les journaux de serveur Web. Toutes les requêtes qui se sont soldées par des erreurs signifient que quelque chose s'est produit. Il peut s'agir de l'erreur HTTP 500 renvoyée par l'application, car la connexion à la base de données a échoué. Il peut s'agir d'erreurs de programmation pointant vers des problèmes de base de données et qui se sont retrouvées dans le journal des erreurs d'Apache. Vous pouvez également utiliser une métrique simple comme disponibilité des serveurs de base de données, bien qu'avec des SLA plus complexes, il puisse être difficile de déterminer l'impact de l'indisponibilité d'une base de données sur votre base d'utilisateurs. Peu importe ce que vous faites, vous devez utiliser plus d'une métrique - cela est nécessaire pour capturer les problèmes qui ont pu se produire sur différentes couches de votre environnement.
Numéro magique :"Trois"
Même si la haute disponibilité concerne également la redondance, dans le cas des clusters de bases de données, trois est un nombre magique. Il ne suffit pas d'avoir deux nœuds pour la redondance - une telle configuration ne fournit aucune haute disponibilité intégrée. Bien sûr, c'est peut-être mieux qu'un seul nœud, mais une intervention humaine est nécessaire pour récupérer les services. Voyons pourquoi il en est ainsi.
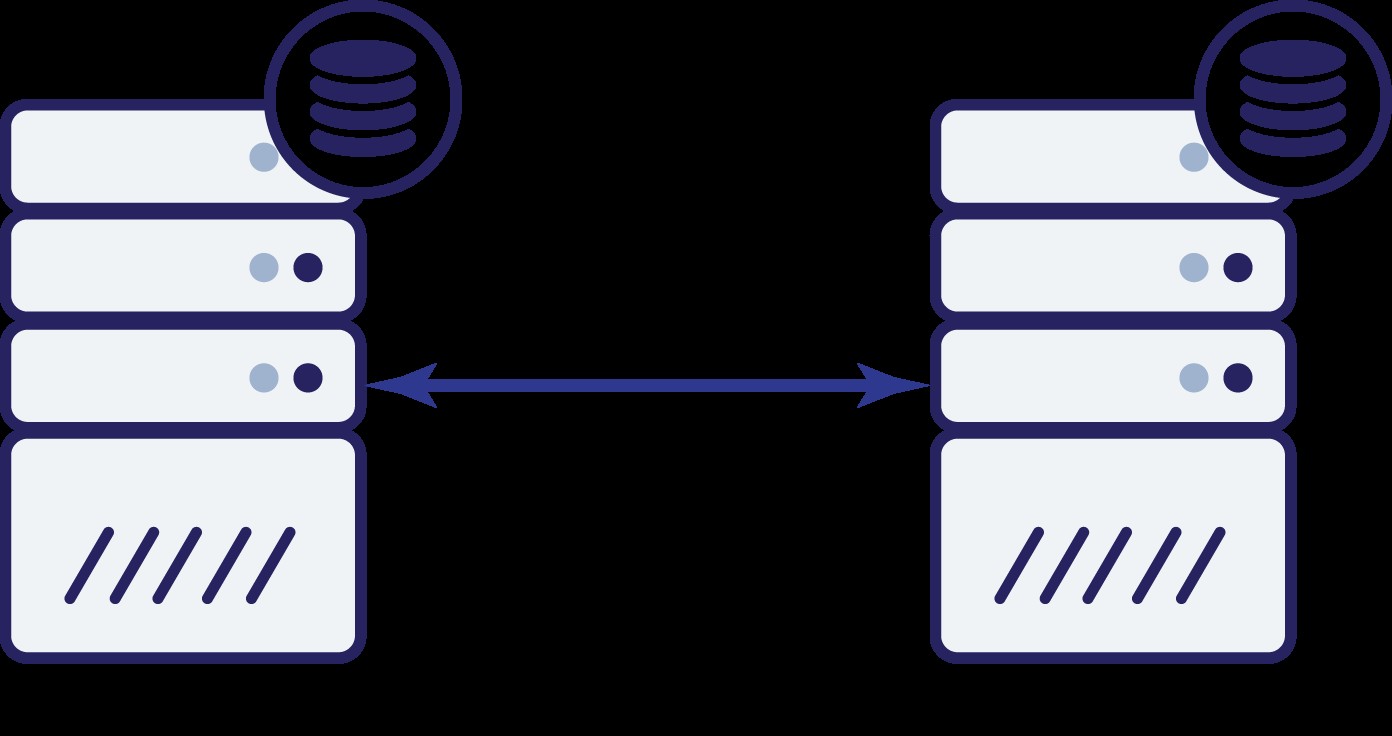
Supposons que nous ayons deux nœuds, A et B. Il existe un lien réseau entre eux. Supposons que A et B servent des écritures et que l'application choisisse au hasard où se connecter (ce qui signifie qu'une partie de l'application se connectera au nœud A et l'autre partie se connectera au nœud B). Maintenant, imaginons que nous ayons un problème de réseau qui entraîne une perte de connectivité réseau entre A et B.
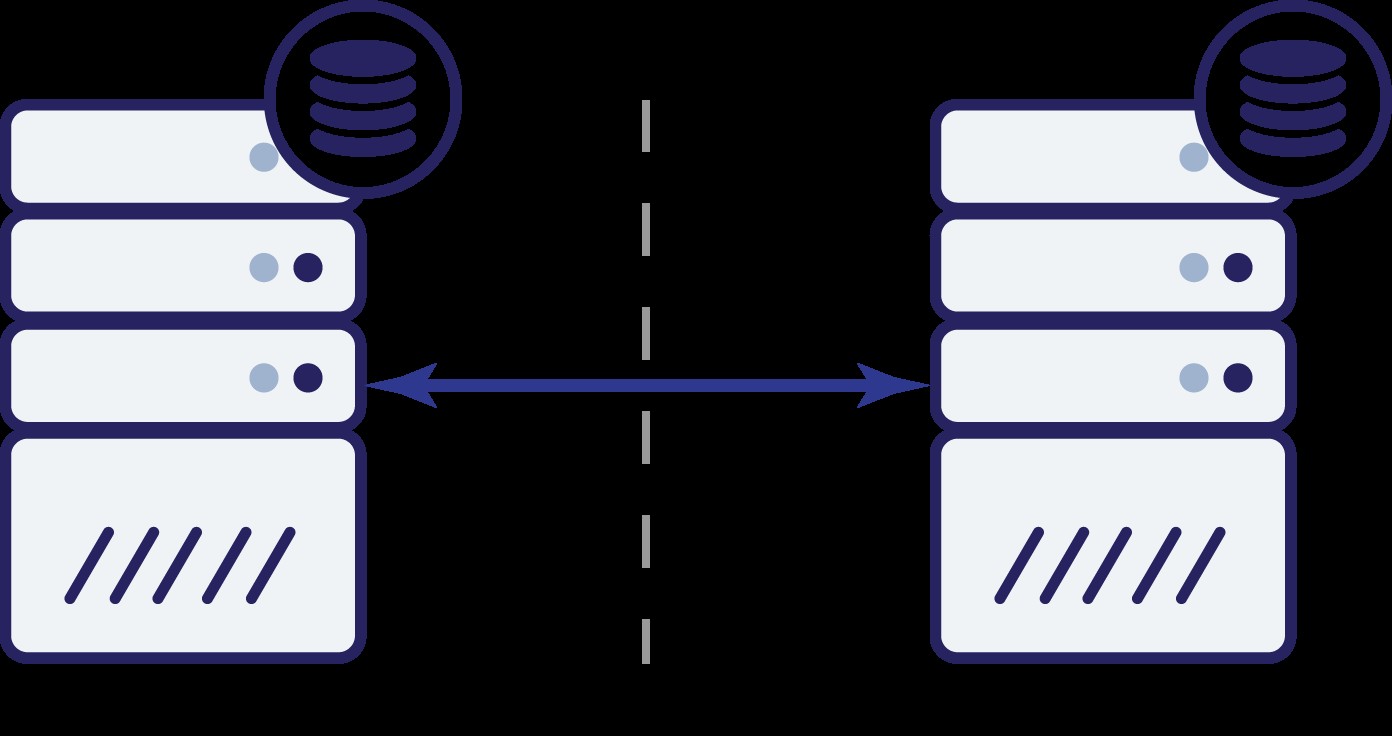
Et maintenant? Ni A ni B ne peuvent connaître l'état de l'autre nœud. Deux actions peuvent être effectuées par les deux nœuds :
- Ils peuvent continuer à accepter du trafic
- Ils peuvent cesser de fonctionner et refuser de desservir tout trafic
Pensons à la première option. Tant que l'autre nœud est effectivement en panne, c'est l'action préférée à prendre - nous voulons que notre base de données continue à servir le trafic. C'est l'idée principale derrière la haute disponibilité après tout. Que se passerait-il, cependant, si les deux nœuds continuaient à accepter du trafic tout en étant déconnectés l'un de l'autre ? De nouvelles données seront ajoutées des deux côtés et les ensembles de données seront désynchronisés. Lorsque le problème de réseau sera résolu, ce sera une tâche ardue de fusionner ces deux ensembles de données. Par conséquent, il n'est pas acceptable de maintenir les deux nœuds opérationnels. Le problème est - comment le nœud A peut-il dire si le nœud B est vivant ou non (et vice versa) ? La réponse est - il ne peut pas. Si toute la connectivité est interrompue, il n'y a aucun moyen de distinguer un nœud défaillant d'un réseau défaillant. Par conséquent, la seule action sûre est que les deux nœuds cessent toutes les opérations et refusent de
servir le trafic.
Réfléchissons maintenant à la manière dont un troisième nœud peut nous aider dans une telle situation.
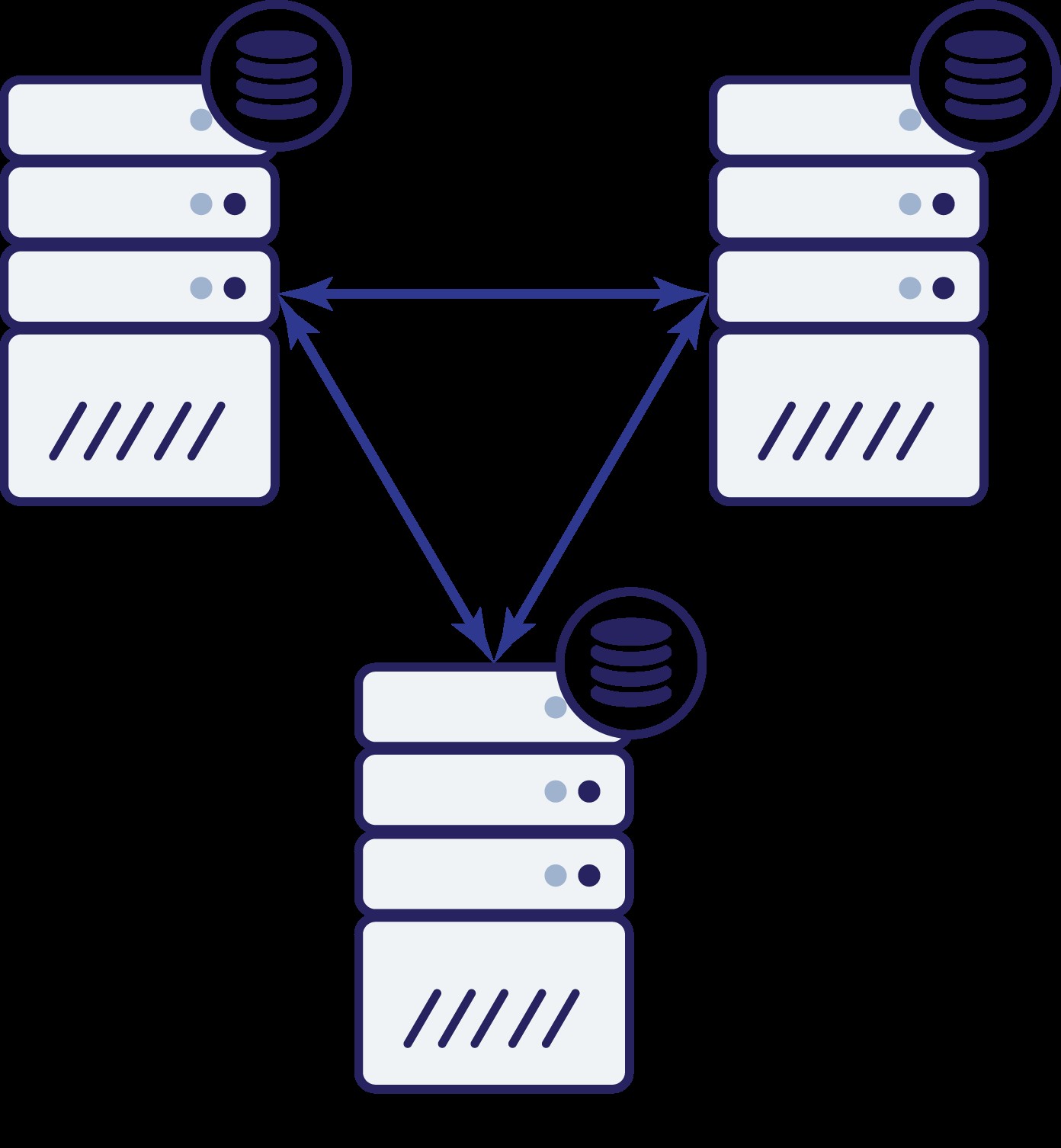
Nous avons donc maintenant trois nœuds :A, B et C. Tous sont interconnectés, tous gèrent les lectures et les écritures.
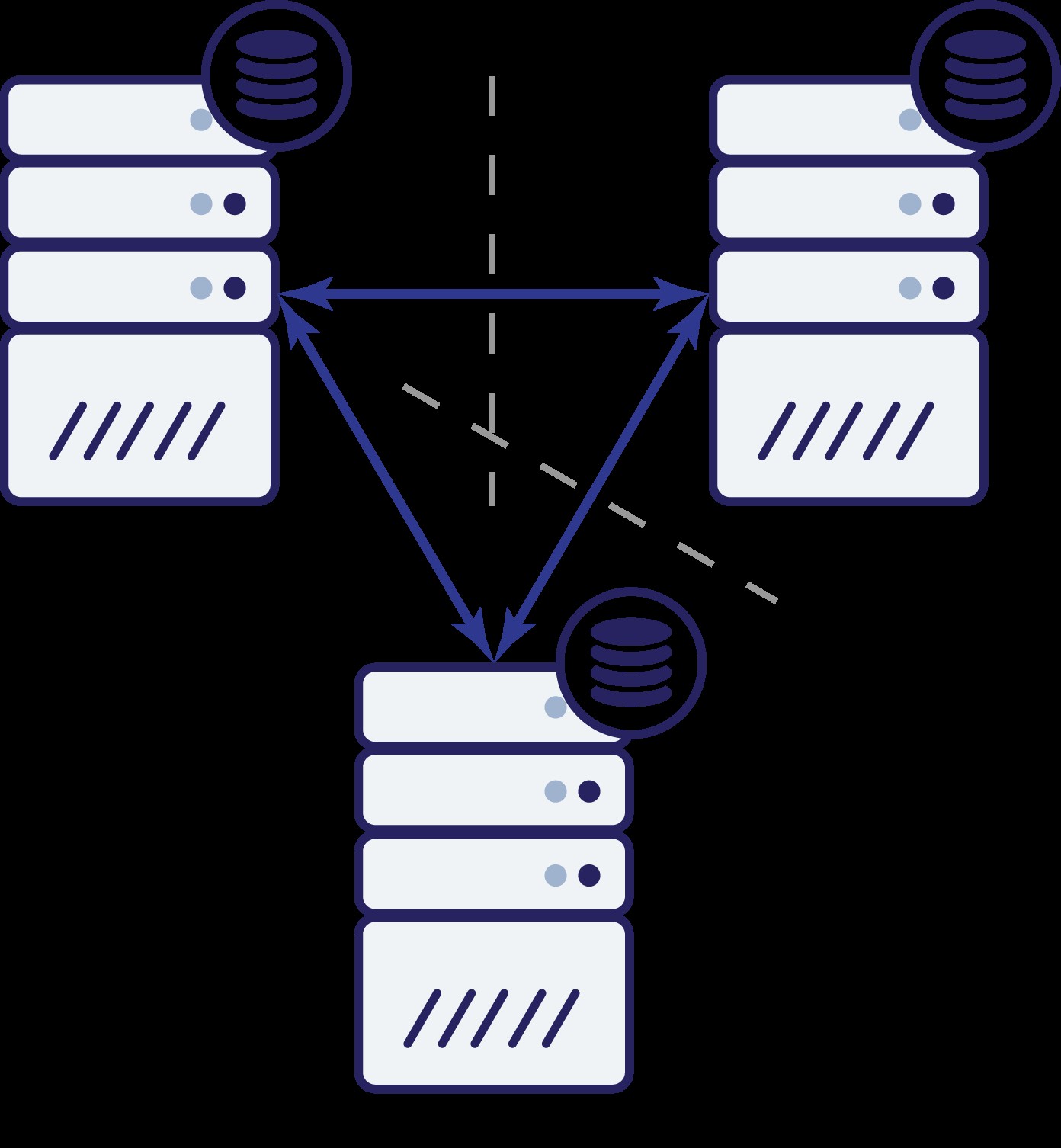
Encore une fois, comme dans l'exemple précédent, le nœud B a été coupé du reste du cluster en raison de problèmes de réseau. Que peut-il se passer ensuite ? Eh bien, la situation est assez similaire à ce dont nous avons discuté plus tôt. Deux options - le nœud B peut soit être en panne (et le reste du cluster doit continuer), soit il peut être en marche, auquel cas il ne doit pas être autorisé à gérer le trafic. Pouvons-nous maintenant dire quel est l'état du cluster ? En fait, oui. Nous pouvons voir que les nœuds A et C peuvent se parler et, par conséquent, ils peuvent convenir que le nœud B n'est pas disponible. Ils ne pourront pas dire pourquoi cela s'est produit, mais ce qu'ils savent, c'est que sur trois nœuds du cluster, deux ont toujours une connectivité entre eux. Étant donné que ces deux nœuds forment la majorité du cluster, cela permet de continuer à gérer le trafic. Dans le même temps, le nœud B peut également déduire que le problème est de son côté. Il ne peut accéder ni au nœud A ni au nœud C, ce qui rend le nœud B séparé du reste du cluster. Comme il est isolé et ne fait pas partie d'une majorité (1 sur 3), la seule action sûre qu'il peut prendre est d'arrêter de servir le trafic et de refuser d'accepter toute requête, en s'assurant que la dérive des données ne se produira pas.
Bien sûr, cela ne signifie pas que vous ne pouvez avoir que trois nœuds dans le cluster. Si vous souhaitez une meilleure tolérance aux pannes, vous pouvez en ajouter d'autres. Gardez cependant à l'esprit qu'il doit s'agir d'un nombre impair si vous souhaitez améliorer la haute disponibilité. De plus, nous parlions de "nœuds" dans les exemples ci-dessus. Veuillez garder à l'esprit que cela est également vrai pour les centres de données, les zones de disponibilité, etc. Si vous avez deux centres de données, chacun ayant le même nombre de nœuds (disons trois nœuds chacun), et que vous perdez la connectivité entre ces deux DC, les mêmes principes s'appliquent ici - vous ne pouvez pas dire quelle moitié du cluster doit commencer à gérer le trafic. Pour pouvoir dire cela, vous devez avoir un observateur dans un troisième centre de données. Il peut s'agir d'un autre ensemble de nœuds, ou d'un seul hôte, avec pour tâche
d'observer l'état des dataceters restants et de participer à la prise de décisions (un exemple ici serait l'arbitre Galera).
Points de défaillance uniques
La haute disponibilité consiste à supprimer les points de défaillance uniques (SPOF) et à ne pas en introduire de nouveaux dans le processus. Que sont les SPOF ? Toute partie de votre infrastructure qui, en cas de défaillance, entraîne un temps d'arrêt tel que défini dans le SLA, est appelée SPOF. La conception des infrastructures nécessite une approche holistique, les différents composants ne peuvent pas être conçus indépendamment les uns des autres. Vous n'êtes probablement pas responsable de l'ensemble de la conception -
les administrateurs de bases de données ont tendance à se concentrer sur les bases de données et non, par exemple, sur la couche réseau. Néanmoins, vous devez garder à l'esprit les autres parties et travailler avec les équipes qui en sont responsables, pour vous assurer que non seulement la partie dont vous êtes responsable est conçue correctement, mais aussi que les éléments restants de l'infrastructure ont été conçus à l'aide du mêmes principes. De plus, une telle connaissance de la façon dont l'ensemble de l'infrastructure est conçue vous aide également à concevoir la pile de la base de données. Savoir quels problèmes peuvent survenir permet de créer des mécanismes pour les empêcher d'affecter la disponibilité de la base de données.