Dans les deux derniers blogs, nous avons expliqué comment exécuter un cluster Galera sur Docker, que ce soit sur Docker autonome ou sur Docker Swarm multi-hôte avec réseau superposé. Dans cet article de blog, nous examinerons l'exécution de Galera Cluster sur Kubernetes, un outil d'orchestration pour exécuter des conteneurs à grande échelle. Certaines parties sont différentes, telles que la manière dont l'application doit se connecter au cluster, la manière dont Kubernetes gère le basculement et le fonctionnement de l'équilibrage de charge dans Kubernetes.
Kubernetes contre Docker Swarm
Notre objectif ultime est de garantir que Galera Cluster fonctionne de manière fiable dans un environnement de conteneurs. Nous avons déjà couvert Docker Swarm, et il s'est avéré que l'exécution de Galera Cluster comporte un certain nombre de bloqueurs, qui l'empêchent d'être prêt pour la production. Notre voyage se poursuit maintenant avec Kubernetes, un outil d'orchestration de conteneurs de production. Voyons quel niveau de "préparation à la production" il peut prendre en charge lors de l'exécution d'un service avec état comme Galera Cluster.
Avant d'aller plus loin, soulignons certaines des principales différences entre Kubernetes (1.6) et Docker Swarm (17.03) lors de l'exécution de Galera Cluster sur des conteneurs :
- Kubernetes prend en charge deux vérifications d'état :la vivacité et l'état de préparation. Ceci est important lors de l'exécution d'un cluster Galera sur des conteneurs, car un conteneur Galera actif ne signifie pas qu'il est prêt à servir et doit être inclus dans l'ensemble d'équilibrage de charge (pensez à un état jointeur/donateur). Docker Swarm ne prend en charge qu'une seule sonde de vérification de l'état similaire à la vivacité de Kubernetes, un conteneur est soit sain et continue de fonctionner, soit malsain et est reprogrammé. Lisez ici pour plus de détails.
- Kubernetes dispose d'un tableau de bord d'interface utilisateur accessible via "proxy kubectl".
- Docker Swarm ne prend en charge que l'équilibrage de charge circulaire (entrée), tandis que Kubernetes utilise le moins de connexion.
- Docker Swarm prend en charge le maillage de routage pour publier un service sur le réseau externe, tandis que Kubernetes prend en charge quelque chose de similaire appelé NodePort, ainsi que des équilibreurs de charge externes (GCE GLB/AWS ELB) et des noms DNS externes (comme pour la v1.7)
Installer Kubernetes à l'aide de Kubeadm
Nous allons utiliser kubeadm pour installer un cluster Kubernetes à 3 nœuds sur CentOS 7. Il se compose de 1 maître et de 2 nœuds (minions). Notre architecture physique ressemble à ceci :
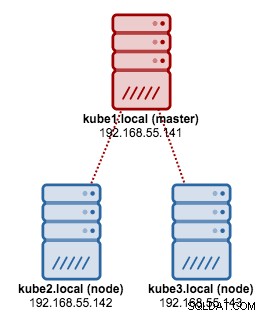
1. Installez kubelet et Docker sur tous les nœuds :
$ ARCH=x86_64
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-${ARCH}
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
$ setenforce 0
$ yum install -y docker kubelet kubeadm kubectl kubernetes-cni
$ systemctl enable docker && systemctl start docker
$ systemctl enable kubelet && systemctl start kubelet2. Sur le maître, initialisez le maître, copiez le fichier de configuration, configurez le réseau Pod à l'aide de Weave et installez le tableau de bord Kubernetes :
$ kubeadm init
$ cp /etc/kubernetes/admin.conf $HOME/
$ export KUBECONFIG=$HOME/admin.conf
$ kubectl apply -f https://git.io/weave-kube-1.6
$ kubectl create -f https://git.io/kube-dashboard3. Puis sur les autres nœuds restants :
$ kubeadm join --token 091d2a.e4862a6224454fd6 192.168.55.140:64434. Vérifiez que les nœuds sont prêts :
$ kubectl get nodes
NAME STATUS AGE VERSION
kube1.local Ready 1h v1.6.3
kube2.local Ready 1h v1.6.3
kube3.local Ready 1h v1.6.3Nous avons maintenant un cluster Kubernetes pour le déploiement de Galera Cluster.
Cluster Galera sur Kubernetes
Dans cet exemple, nous allons déployer un cluster MariaDB Galera 10.1 à l'aide d'une image Docker extraite de notre référentiel DockerHub. Les fichiers de définition YAML utilisés dans ce déploiement se trouvent dans le répertoire example-kubernetes du référentiel Github.
Kubernetes prend en charge un certain nombre de contrôleurs de déploiement. Pour déployer un cluster Galera, on peut utiliser :
- Ensemble de répliques
- StatefulSet
Chacun d'eux a ses propres avantages et inconvénients. Nous allons examiner chacun d'eux et voir quelle est la différence.
Prérequis
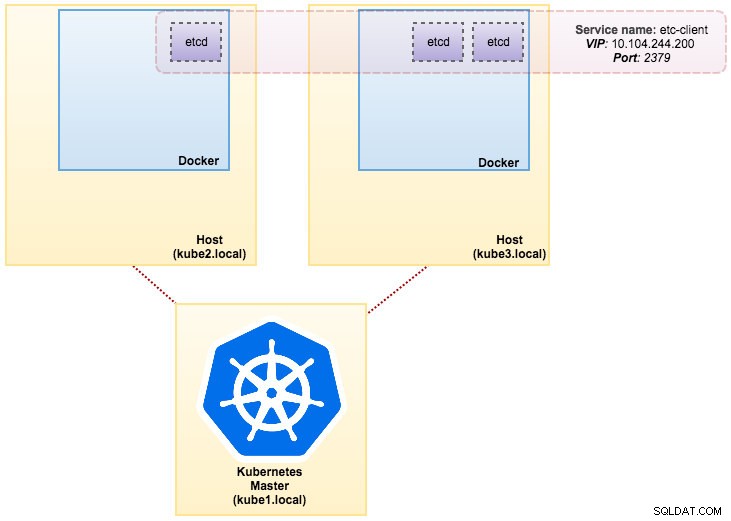
L'image que nous avons construite nécessite un etcd (autonome ou cluster) pour la découverte de service. Pour exécuter un cluster etcd, chaque instance etcd doit être exécutée avec différentes commandes. Nous allons donc utiliser le contrôleur de pods au lieu du déploiement et créer un service appelé "etcd-client" comme point de terminaison des pods etcd. Le fichier de définition etcd-cluster.yaml dit tout.
Pour déployer un cluster etcd à 3 pods, exécutez simplement :
$ kubectl create -f etcd-cluster.yamlVérifiez si le cluster etcd est prêt :
$ kubectl get po,svc
NAME READY STATUS RESTARTS AGE
po/etcd0 1/1 Running 0 1d
po/etcd1 1/1 Running 0 1d
po/etcd2 1/1 Running 0 1d
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/etcd-client 10.104.244.200 <none> 2379/TCP 1d
svc/etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d
svc/etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d
svc/etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1dNotre architecture ressemble maintenant à ceci :
 Severalnines MySQL on Docker :How to Containerize Your DatabaseDécouvrez tout ce que vous devez comprendre lorsque vous envisagez d'exécuter un service MySQL sur top de la virtualisation des conteneurs DockerTélécharger le livre blanc
Severalnines MySQL on Docker :How to Containerize Your DatabaseDécouvrez tout ce que vous devez comprendre lorsque vous envisagez d'exécuter un service MySQL sur top de la virtualisation des conteneurs DockerTélécharger le livre blanc Utilisation de ReplicaSet
Un ReplicaSet garantit qu'un nombre spécifié de "répliques" de pod s'exécutent à un moment donné. Cependant, un déploiement est un concept de niveau supérieur qui gère les ReplicaSets et fournit des mises à jour déclaratives aux pods ainsi que de nombreuses autres fonctionnalités utiles. Par conséquent, il est recommandé d'utiliser les déploiements au lieu d'utiliser directement les ReplicaSets, sauf si vous avez besoin d'une orchestration de mise à jour personnalisée ou si vous n'avez pas du tout besoin de mises à jour. Lorsque vous utilisez des déploiements, vous n'avez pas à vous soucier de la gestion des ReplicaSets qu'ils créent. Les déploiements possèdent et gèrent leurs ReplicaSets.
Dans notre cas, nous allons utiliser Deployment comme contrôleur de charge de travail, comme indiqué dans cette définition YAML. Nous pouvons directement créer le Galera Cluster ReplicaSet and Service en exécutant la commande suivante :
$ kubectl create -f mariadb-rs.ymlVérifiez si le cluster est prêt en examinant le ReplicaSet (rs), les pods (po) et les services (svc) :
$ kubectl get rs,po,svc
NAME DESIRED CURRENT READY AGE
rs/galera-251551564 3 3 3 5h
NAME READY STATUS RESTARTS AGE
po/etcd0 1/1 Running 0 1d
po/etcd1 1/1 Running 0 1d
po/etcd2 1/1 Running 0 1d
po/galera-251551564-8c238 1/1 Running 0 5h
po/galera-251551564-swjjl 1/1 Running 1 5h
po/galera-251551564-z4sgx 1/1 Running 1 5h
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/etcd-client 10.104.244.200 <none> 2379/TCP 1d
svc/etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d
svc/etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d
svc/etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1d
svc/galera-rs 10.107.89.109 <nodes> 3306:30000/TCP 5h
svc/kubernetes 10.96.0.1 <none> 443/TCP 1dÀ partir de la sortie ci-dessus, nous pouvons illustrer nos pods et notre service comme ci-dessous :
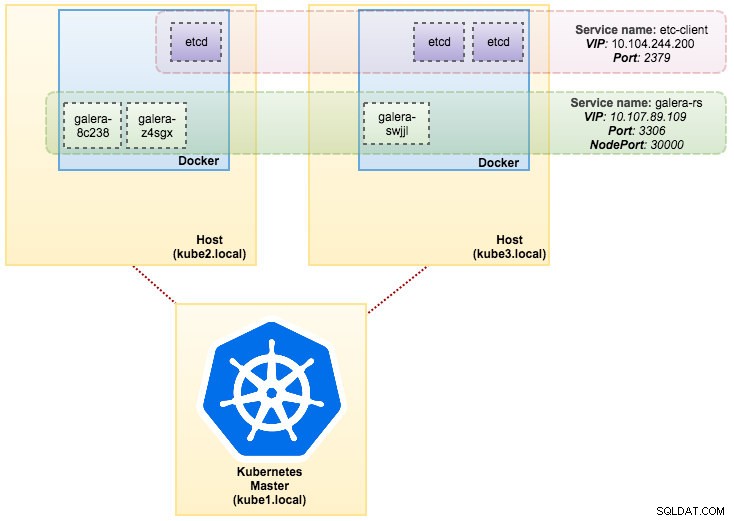
L'exécution de Galera Cluster sur ReplicaSet revient à le traiter comme une application sans état. Il orchestre la création, la suppression et les mises à jour des pods et peut être ciblé pour les mises à l'échelle horizontales des pods (HPA), c'est-à-dire qu'un ReplicaSet peut être mis à l'échelle automatiquement s'il atteint certains seuils ou cibles (utilisation du processeur, paquets par seconde, demande par seconde etc.).
Si l'un des nœuds Kubernetes tombe en panne, de nouveaux pods seront planifiés sur un nœud disponible pour répondre aux répliques souhaitées. Les volumes associés au pod seront supprimés si le pod est supprimé ou replanifié. Le nom d'hôte du pod sera généré de manière aléatoire, ce qui rendra plus difficile le suivi de l'appartenance du conteneur en regardant simplement le nom d'hôte.
Tout cela fonctionne plutôt bien dans les environnements de test et de mise en scène, où vous pouvez effectuer un cycle de vie complet du conteneur comme le déploiement, la mise à l'échelle, la mise à jour et la destruction sans aucune dépendance. La mise à l'échelle vers le haut et vers le bas est simple, en mettant à jour le fichier YAML et en le publiant sur le cluster Kubernetes ou en utilisant la commande scale :
$ kubectl scale replicaset galera-rs --replicas=5Utiliser StatefulSet
Connu sous le nom de PetSet sur la version antérieure à 1.6, StatefulSet est le meilleur moyen de déployer Galera Cluster en production, car :
- La suppression et/ou la réduction d'un StatefulSet ne supprimera pas les volumes associés au StatefulSet. Ceci est fait pour assurer la sécurité des données, ce qui est généralement plus précieux qu'une purge automatique de toutes les ressources StatefulSet associées.
- Pour un StatefulSet avec N réplicas, lorsque les pods sont déployés, ils sont créés de manière séquentielle, dans l'ordre de {0 .. N-1 }.
- Lorsque les pods sont supprimés, ils sont résiliés dans l'ordre inverse, à partir de {N-1 .. 0}.
- Avant qu'une opération de mise à l'échelle soit appliquée à un pod, tous ses prédécesseurs doivent être en cours d'exécution et prêts.
- Avant qu'un pod ne soit résilié, tous ses successeurs doivent être complètement arrêtés.
StatefulSet fournit une prise en charge de première classe pour les conteneurs avec état. Il offre une garantie de déploiement et de mise à l'échelle. Lorsqu'un cluster Galera à trois nœuds est créé, trois pods seront déployés dans l'ordre db-0, db-1, db-2. db-1 ne sera pas déployé tant que db-0 n'est pas "En cours d'exécution et prêt", et db-2 ne sera pas déployé tant que db-1 n'est pas "En cours d'exécution et prêt". Si db-0 doit échouer, après que db-1 est "En cours d'exécution et prêt", mais avant que db-2 ne soit lancé, db-2 ne sera pas lancé tant que db-0 n'est pas relancé avec succès et devient "En cours d'exécution et prêt".
Nous allons utiliser l'implémentation Kubernetes du stockage persistant appelé PersistentVolume et PersistentVolumeClaim. Ceci pour garantir la persistance des données si le pod est reprogrammé sur l'autre nœud. Même si Galera Cluster fournit la copie exacte des données sur chaque réplique, la persistance des données dans chaque pod est utile à des fins de dépannage et de récupération.
Pour créer un stockage persistant, nous devons d'abord créer PersistentVolume pour chaque pod. Les PV sont des plugins de volume comme Volumes dans Docker, mais ont un cycle de vie indépendant de tout pod individuel qui utilise le PV. Puisque nous allons déployer un cluster Galera à 3 nœuds, nous devons créer 3 PV :
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-0
labels:
app: galera-ss
podindex: "0"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-0/datadir
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-1
labels:
app: galera-ss
podindex: "1"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-1/datadir
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-2
labels:
app: galera-ss
podindex: "2"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-2/datadirLa définition ci-dessus montre que nous allons créer 3 PV, mappés sur le chemin physique des nœuds Kubernetes avec 10 Go d'espace de stockage. Nous avons défini ReadWriteOnce, ce qui signifie que le volume peut être monté en lecture-écriture par un seul nœud. Enregistrez les lignes ci-dessus dans mariadb-pv.yml et publiez-les sur Kubernetes :
$ kubectl create -f mariadb-pv.yml
persistentvolume "datadir-galera-0" created
persistentvolume "datadir-galera-1" created
persistentvolume "datadir-galera-2" createdEnsuite, définissez les ressources PersistentVolumeClaim :
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-0
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "0"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-1
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "1"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-2
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "2"La définition ci-dessus montre que nous aimerions réclamer les ressources PV et utiliser les spec.selector.matchLabels pour rechercher notre PV (metadata.labels.app :galera-ss ) en fonction de l'index de pod respectif (metadata.labels.podindex ) attribué par Kubernetes. Le metadata.name la ressource doit utiliser le format "{volumeMounts.name}-{pod}-{ordinal index}" défini sous spec.templates.containers afin que Kubernetes sache quel point de montage mapper la revendication dans le pod.
Enregistrez les lignes ci-dessus dans mariadb-pvc.yml et publiez-les sur Kubernetes :
$ kubectl create -f mariadb-pvc.yml
persistentvolumeclaim "mysql-datadir-galera-ss-0" created
persistentvolumeclaim "mysql-datadir-galera-ss-1" created
persistentvolumeclaim "mysql-datadir-galera-ss-2" createdNotre stockage persistant est maintenant prêt. Nous pouvons ensuite démarrer le déploiement de Galera Cluster en créant une ressource StatefulSet avec une ressource de service Headless, comme indiqué dans mariadb-ss.yml :
$ kubectl create -f mariadb-ss.yml
service "galera-ss" created
statefulset "galera-ss" createdMaintenant, récupérez le résumé de notre déploiement StatefulSet :
$ kubectl get statefulsets,po,pv,pvc -o wide
NAME DESIRED CURRENT AGE
statefulsets/galera-ss 3 3 1d galera severalnines/mariadb:10.1 app=galera-ss
NAME READY STATUS RESTARTS AGE IP NODE
po/etcd0 1/1 Running 0 7d 10.36.0.1 kube3.local
po/etcd1 1/1 Running 0 7d 10.44.0.2 kube2.local
po/etcd2 1/1 Running 0 7d 10.36.0.2 kube3.local
po/galera-ss-0 1/1 Running 0 1d 10.44.0.4 kube2.local
po/galera-ss-1 1/1 Running 1 1d 10.36.0.5 kube3.local
po/galera-ss-2 1/1 Running 0 1d 10.44.0.5 kube2.local
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE
pv/datadir-galera-0 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-0 4d
pv/datadir-galera-1 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-1 4d
pv/datadir-galera-2 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-2 4d
NAME STATUS VOLUME CAPACITY ACCESSMODES STORAGECLASS AGE
pvc/mysql-datadir-galera-ss-0 Bound datadir-galera-0 10Gi RWO 4d
pvc/mysql-datadir-galera-ss-1 Bound datadir-galera-1 10Gi RWO 4d
pvc/mysql-datadir-galera-ss-2 Bound datadir-galera-2 10Gi RWO 4dÀ ce stade, notre cluster Galera fonctionnant sur StatefulSet peut être illustré comme dans le schéma suivant :
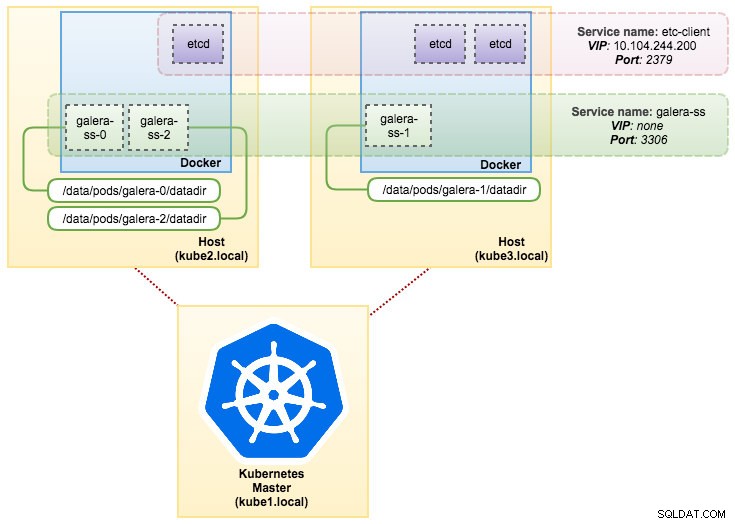
L'exécution sur StatefulSet garantit des identifiants cohérents tels que le nom d'hôte, l'adresse IP, l'ID réseau, le domaine du cluster, le DNS du pod et le stockage. Cela permet au Pod de se distinguer facilement des autres dans un groupe de Pods. Le volume sera conservé sur l'hôte et ne sera pas supprimé si le pod est supprimé ou reprogrammé sur un autre nœud. Cela permet la récupération des données et réduit le risque de perte totale de données.
Du côté négatif, le temps de déploiement sera N-1 fois (N =répliques) plus longtemps car Kubernetes obéira à la séquence ordinale lors du déploiement, de la replanification ou de la suppression des ressources. Il serait un peu fastidieux de préparer le PV et les réclamations avant de penser à faire évoluer votre cluster. Notez que la mise à jour d'un StatefulSet existant est actuellement un processus manuel, où vous ne pouvez que mettre à jour spec.replicas pour le moment.
Connexion au service de cluster Galera et aux pods
Il existe plusieurs façons de se connecter au cluster de bases de données. Vous pouvez vous connecter directement au port. Dans l'exemple de service "galera-rs", nous utilisons NodePort, exposant le service sur l'IP de chaque nœud à un port statique (le NodePort). Un service ClusterIP, vers lequel le service NodePort sera acheminé, est automatiquement créé. Vous pourrez contacter le service NodePort, depuis l'extérieur du cluster, en demandant {NodeIP} :{NodePort} .
Exemple pour se connecter au cluster Galera en externe :
(external)$ mysql -udb_user -ppassword -h192.168.55.141 -P30000
(external)$ mysql -udb_user -ppassword -h192.168.55.142 -P30000
(external)$ mysql -udb_user -ppassword -h192.168.55.143 -P30000Au sein de l'espace réseau Kubernetes, les pods peuvent se connecter via l'adresse IP du cluster ou le nom du service en interne, qui est récupérable à l'aide de la commande suivante :
$ kubectl get services -o wide
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
etcd-client 10.104.244.200 <none> 2379/TCP 1d app=etcd
etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd0
etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd1
etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd2
galera-rs 10.107.89.109 <nodes> 3306:30000/TCP 4h app=galera-rs
galera-ss None <none> 3306/TCP 3m app=galera-ss
kubernetes 10.96.0.1 <none> 443/TCP 1d <none>Dans la liste des services, nous pouvons voir que l'IP du cluster Galera Cluster ReplicaSet est 10.107.89.109. En interne, un autre pod peut accéder à la base de données via cette adresse IP ou ce nom de service en utilisant le port exposé, 3306 :
(etcd0 pod)$ mysql -udb_user -ppassword -hgalera-rs -P3306 -e 'select @@hostname'
+------------------------+
| @@hostname |
+------------------------+
| galera-251551564-z4sgx |
+------------------------+Vous pouvez également vous connecter au NodePort externe depuis n'importe quel pod sur le port 30000 :
(etcd0 pod)$ mysql -udb_user -ppassword -h192.168.55.143 -P30000 -e 'select @@hostname'
+------------------------+
| @@hostname |
+------------------------+
| galera-251551564-z4sgx |
+------------------------+La connexion aux pods backend sera équilibrée en fonction de la charge en fonction du moindre algorithme de connexion.
Résumé
À ce stade, l'exécution de Galera Cluster sur Kubernetes en production semble beaucoup plus prometteuse par rapport à Docker Swarm. Comme indiqué dans le dernier article de blog, les préoccupations soulevées sont abordées différemment avec la façon dont Kubernetes orchestre les conteneurs dans StatefulSet (bien qu'il s'agisse toujours d'une fonctionnalité bêta dans la v1.6). Nous espérons que l'approche suggérée aidera à exécuter Galera Cluster sur des conteneurs à grande échelle en production.



