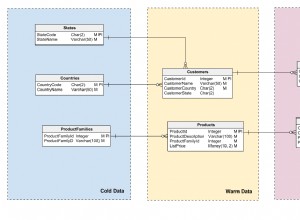
Si les user_resources (t1) était une 'table normalisée' avec une ligne pour chaque user => resource combinaison alors la requête pour obtenir la réponse serait aussi simple que de simplement joining les tables ensemble.
Hélas, il est denormalized en ayant les resources colonne sous la forme d'une :'liste d'ID de ressource' séparés par un ';' caractère.
Si nous pouvions convertir la colonne « ressources » en lignes, la plupart des difficultés disparaîtraient à mesure que les jointures de table deviendraient simples.
La requête pour générer la sortie demandée :
SELECT user_resource.user,
resource.data
FROM user_resource
JOIN integerseries AS isequence
ON isequence.id <= COUNT_IN_SET(user_resource.resources, ';') /* normalize */
JOIN resource
ON resource.id = VALUE_IN_SET(user_resource.resources, ';', isequence.id)
ORDER BY
user_resource.user, resource.data
Le résultat :
user data
---------- --------
sampleuser abcde
sampleuser azerty
sampleuser qwerty
stacky qwerty
testuser abcde
testuser azerty
Comment :
Le "truc" est d'avoir une table qui contient les nombres de 1 à une certaine limite. Je l'appelle integerseries . Il peut être utilisé pour convertir des éléments 'horizontaux' tels que :';' delimited strings en rows .
La façon dont cela fonctionne est que lorsque vous "rejoignez" avec integerseries , vous faites une cross join , ce qui se passe "naturellement" avec les "jointures internes".
Chaque ligne est dupliquée avec un "numéro de séquence" différent de la integerseries table que nous utilisons comme 'index' de la 'ressource' dans la liste que nous voulons utiliser pour cette row .
L'idée est de :
- comptez le nombre d'éléments dans la liste.
- extraire chaque élément en fonction de sa position dans la liste.
- Utilisez des
integerseriespour convertir une ligne en un ensemble de lignes en extrayant l'identifiant de ressource individuel deuser.resourcesau fur et à mesure.
J'ai décidé d'utiliser deux fonctions :
-
fonction qui, étant donné une 'liste de chaînes délimitée' et un 'index', renverra la valeur à la position dans la liste. Je l'appelle :
VALUE_IN_SET. c'est-à-dire qu'étant donné 'A;B;C' et un 'index' de 2, il renvoie 'B'. -
fonction qui, étant donné une "liste de chaînes délimitée", renverra le nombre d'éléments de la liste. Je l'appelle :
COUNT_IN_SET. c'est-à-dire que 'A;B;C' renverra 3
Il s'avère que ces deux fonctions et integerseries devrait fournir une solution générale à la delimited items list in a column .
Ça marche ?
La requête pour créer une table 'normalisée' à partir d'un ';' delimited string in column . Il affiche toutes les colonnes, y compris les valeurs générées en raison du 'cross_join' (isequence.id comme resources_index ):
SELECT user_resource.user,
user_resource.resources,
COUNT_IN_SET(user_resource.resources, ';') AS resources_count,
isequence.id AS resources_index,
VALUE_IN_SET(user_resource.resources, ';', isequence.id) AS resources_value
FROM
user_resource
JOIN integerseries AS isequence
ON isequence.id <= COUNT_IN_SET(user_resource.resources, ';')
ORDER BY
user_resource.user, isequence.id
Le résultat du tableau "normalisé" :
user resources resources_count resources_index resources_value
---------- --------- --------------- --------------- -----------------
sampleuser 1;2;3 3 1 1
sampleuser 1;2;3 3 2 2
sampleuser 1;2;3 3 3 3
stacky 2 1 1 2
testuser 1;3 2 1 1
testuser 1;3 2 2 3
Utilisation des user_resources "normalisés" ci-dessus table, il s'agit d'une simple jointure pour fournir la sortie requise :
Les fonctions nécessaires (ce sont des fonctions générales qui peuvent être utilisées n'importe où )
note :Les noms de ces fonctions sont liés au mysql fonction FIND_IN_SET . c'est-à-dire qu'ils font des choses similaires en ce qui concerne les listes de chaînes ?
Le COUNT_IN_SET fonction :renvoie le nombre d'éléments character delimited items dans la colonne.
DELIMITER $$
DROP FUNCTION IF EXISTS `COUNT_IN_SET`$$
CREATE FUNCTION `COUNT_IN_SET`(haystack VARCHAR(1024),
delim CHAR(1)
) RETURNS INTEGER
BEGIN
RETURN CHAR_LENGTH(haystack) - CHAR_LENGTH( REPLACE(haystack, delim, '')) + 1;
END$$
DELIMITER ;
Le VALUE_IN_SET fonction :traite la delimited list en tant que one based array et renvoie la valeur à 'l'index' donné.
DELIMITER $$
DROP FUNCTION IF EXISTS `VALUE_IN_SET`$$
CREATE FUNCTION `VALUE_IN_SET`(haystack VARCHAR(1024),
delim CHAR(1),
which INTEGER
) RETURNS VARCHAR(255) CHARSET utf8 COLLATE utf8_unicode_ci
BEGIN
RETURN SUBSTRING_INDEX(SUBSTRING_INDEX(haystack, delim, which),
delim,
-1);
END$$
DELIMITER ;
Informations connexes :
-
Enfin trouvé comment obtenir SQLFiddle - code de travail pour compiler des fonctions.
-
Il existe une version de ceci qui fonctionne pour
SQLitebases de données également SQLite- Normaliser un champ concaténé et le joindre ?
Les tableaux (avec données) :
CREATE TABLE `integerseries` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=500 DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
/*Data for the table `integerseries` */
insert into `integerseries`(`id`) values (1);
insert into `integerseries`(`id`) values (2);
insert into `integerseries`(`id`) values (3);
insert into `integerseries`(`id`) values (4);
insert into `integerseries`(`id`) values (5);
insert into `integerseries`(`id`) values (6);
insert into `integerseries`(`id`) values (7);
insert into `integerseries`(`id`) values (8);
insert into `integerseries`(`id`) values (9);
insert into `integerseries`(`id`) values (10);
Ressource :
CREATE TABLE `resource` (
`id` int(11) NOT NULL,
`data` varchar(250) COLLATE utf8_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
/*Data for the table `resource` */
insert into `resource`(`id`,`data`) values (1,'abcde');
insert into `resource`(`id`,`data`) values (2,'qwerty');
insert into `resource`(`id`,`data`) values (3,'azerty');
User_resource :
CREATE TABLE `user_resource` (
`user` varchar(50) COLLATE utf8_unicode_ci NOT NULL,
`resources` varchar(250) COLLATE utf8_unicode_ci DEFAULT NULL,
PRIMARY KEY (`user`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
/*Data for the table `user_resource` */
insert into `user_resource`(`user`,`resources`) values ('sampleuser','1;2;3');
insert into `user_resource`(`user`,`resources`) values ('stacky','3');
insert into `user_resource`(`user`,`resources`) values ('testuser','1;3');