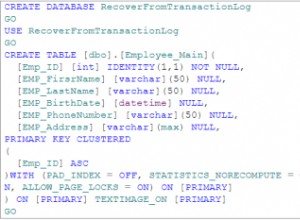
En général, utf8_general_ci est plus rapide que utf8_unicode_ci , mais moins correct.
Voici la différence :
Pour tout jeu de caractères Unicode, les opérations effectuées à l'aide du classement _general_ci sont plus rapides que celles du classement _unicode_ci . Par exemple, les comparaisons pour le classement utf8_general_ci sont plus rapides, mais légèrement moins correctes, que les comparaisons pour utf8_unicode_ci. La raison en est que utf8_unicode_ci prend en charge les mappages tels que les expansions; c'est-à-dire lorsqu'un caractère est comparé à des combinaisons d'autres caractères. Par exemple, en allemand et dans certaines autres langues, "ß" est égal à "ss". utf8_unicode_ci prend également en charge les contractions et les caractères ignorables. utf8_general_ci est un classement hérité qui ne prend pas en charge les expansions, les contractions ou les caractères ignorables. Il ne peut faire que des comparaisons un à un entre les caractères.
Cité de :https://dev.mysql. com/doc/refman/5.0/en/charset-unicode-sets.html
Pour une explication plus détaillée, veuillez lire le post suivant des forums MySQL :http:/ /forums.mysql.com/read.php?103,187048,188748
Comme pour utf8_bin :les deux utf8_general_ci et utf8_unicode_ci effectuer une comparaison insensible à la casse. En revanche, utf8_bin est sensible à la casse (entre autres différences), car il compare les valeurs binaires des caractères.