Les performances sont extrêmement importantes dans de nombreux produits de consommation tels que le commerce électronique, les systèmes de paiement, les jeux, les applications de transport, etc. Bien que les bases de données soient optimisées en interne via plusieurs mécanismes pour répondre à leurs exigences de performances dans le monde moderne, beaucoup dépend également du développeur de l'application. Après tout, seul un développeur sait quelles requêtes l'application doit effectuer.
Les développeurs qui traitent des bases de données relationnelles ont utilisé ou du moins entendu parler de l'indexation, et c'est un concept très courant dans le monde des bases de données. Cependant, la partie la plus importante est de comprendre ce qu'il faut indexer et comment l'indexation va augmenter le temps de réponse aux requêtes. Pour ce faire, vous devez comprendre comment vous allez interroger les tables de votre base de données. Un index approprié ne peut être créé que lorsque vous savez exactement à quoi ressemblent vos modèles de requête et d'accès aux données.
En termes simples, un index mappe les clés de recherche aux données correspondantes sur le disque en utilisant différentes structures de données en mémoire et sur disque. L'index est utilisé pour accélérer la recherche en réduisant le nombre d'enregistrements à rechercher.
Généralement, un index est créé sur les colonnes spécifiées dans WHERE clause d'une requête lorsque la base de données récupère et filtre les données des tables en fonction de ces colonnes. Si vous ne créez pas d'index, la base de données analyse toutes les lignes, filtre les lignes correspondantes et renvoie le résultat. Avec des millions d'enregistrements, cette opération d'analyse peut prendre plusieurs secondes et ce temps de réponse élevé rend les API et les applications plus lentes et inutilisables. Voyons un exemple —
Nous utiliserons MySQL avec un moteur de base de données InnoDB par défaut, bien que les concepts expliqués dans cet article soient plus ou moins les mêmes dans d'autres serveurs de base de données comme Oracle, MSSQL, etc.
Créez une table appelée index_demo avec le schéma suivant :
CREATE TABLE index_demo (
name VARCHAR(20) NOT NULL,
age INT,
pan_no VARCHAR(20),
phone_no VARCHAR(20)
);Comment vérifions-nous que nous utilisons le moteur InnoDB ?
Exécutez la commande ci-dessous :
SHOW TABLE STATUS WHERE name = 'index_demo' \G;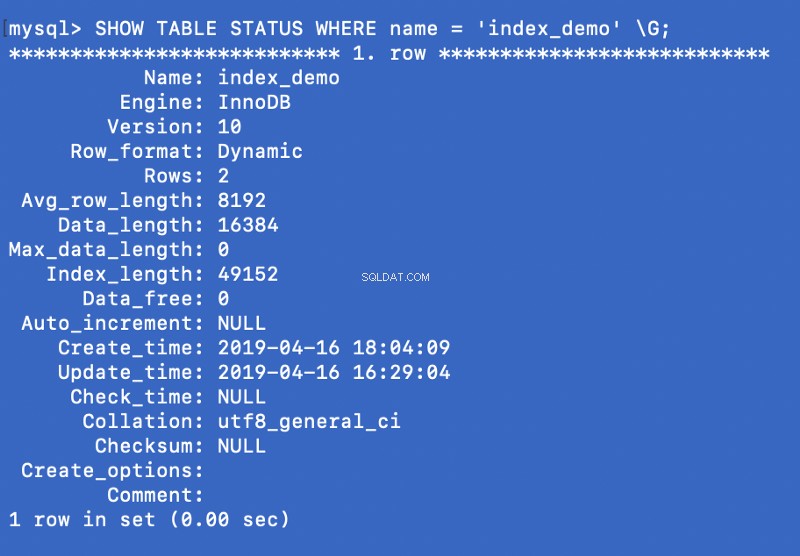
Le Engine La colonne dans la capture d'écran ci-dessus représente le moteur utilisé pour créer la table. Ici InnoDB est utilisé.
Insérez maintenant des données aléatoires dans le tableau, mon tableau de 5 lignes ressemble à ceci :
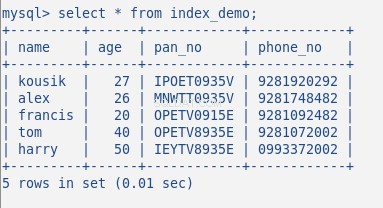
Je n'ai créé aucun index jusqu'à présent sur cette table. Vérifions cela par la commande :SHOW INDEX . Il renvoie 0 résultats.

À ce moment, si nous lançons un simple SELECT requête, puisqu'il n'y a pas d'index défini par l'utilisateur, la requête parcourra toute la table pour trouver le résultat :
EXPLAIN SELECT * FROM index_demo WHERE name = 'alex';
EXPLAIN montre comment le moteur de requête prévoit d'exécuter la requête. Dans la capture d'écran ci-dessus, vous pouvez voir que les rows la colonne renvoie 5 &possible_keys renvoie null . possible_keys représente tous les indices disponibles qui peuvent être utilisés dans cette requête. La key la colonne représente quel index va réellement être utilisé parmi tous les index possibles dans cette requête.
Clé primaire :
La requête ci-dessus est très inefficace. Optimisons cette requête. Nous ferons le phone_no colonne a PRIMARY KEY en supposant que deux utilisateurs ne peuvent exister dans notre système avec le même numéro de téléphone. Tenez compte des éléments suivants lors de la création d'une clé primaire :
- Une clé primaire doit faire partie de nombreuses requêtes vitales dans votre application.
- La clé primaire est une contrainte qui identifie de manière unique chaque ligne d'une table. Si plusieurs colonnes font partie de la clé primaire, cette combinaison doit être unique pour chaque ligne.
- La clé primaire doit être non nulle. Ne faites jamais de champs nullables votre clé primaire. Selon les normes ANSI SQL, les clés primaires doivent être comparables les unes aux autres et vous devez certainement être en mesure de dire si la valeur de la colonne de clé primaire pour une ligne particulière est supérieure, inférieure ou égale à celle d'une autre ligne. Depuis
NULLsignifie une valeur indéfinie dans les normes SQL, vous ne pouvez pas comparer de manière déterministeNULLavec n'importe quelle autre valeur, donc logiquementNULLn'est pas autorisé. - Le type de clé primaire idéal doit être un nombre comme
INTouBIGINTcar les comparaisons d'entiers sont plus rapides, donc parcourir l'index sera très rapide.
Souvent, nous définissons un id champ comme AUTO INCREMENT dans les tables et utilisez-la comme clé primaire, mais le choix d'une clé primaire dépend des développeurs.
Et si vous ne créez pas de clé primaire vous-même ?
Il n'est pas obligatoire de créer soi-même une clé primaire. Si vous n'avez défini aucune clé primaire, InnoDB en crée implicitement une pour vous car InnoDB, par conception, doit avoir une clé primaire dans chaque table. Ainsi, une fois que vous créez une clé primaire ultérieurement pour cette table, InnoDB supprime la clé primaire précédemment définie automatiquement.
Puisque nous n'avons pas défini de clé primaire pour l'instant, voyons ce qu'InnoDB a créé par défaut pour nous :
SHOW EXTENDED INDEX FROM index_demo;
EXTENDED affiche tous les index qui ne sont pas utilisables par l'utilisateur mais entièrement gérés par MySQL.
Ici, nous voyons que MySQL a défini un index composite (nous discuterons des index composites plus tard) sur DB_ROW_ID , DB_TRX_ID , DB_ROLL_PTR , &toutes les colonnes définies dans la table. En l'absence de clé primaire définie par l'utilisateur, cet index est utilisé pour rechercher des enregistrements de manière unique.
Quelle est la différence entre clé et index ?
Bien que les termes key &index sont utilisés de manière interchangeable, key signifie une contrainte imposée sur le comportement de la colonne. Dans ce cas, la contrainte est que la clé primaire est un champ non nullable qui identifie de manière unique chaque ligne. En revanche, index est une structure de données spéciale qui facilite la recherche de données dans le tableau.
Créons maintenant l'index primaire sur phone_no &examinez l'index créé :
ALTER TABLE index_demo ADD PRIMARY KEY (phone_no);
SHOW INDEXES FROM index_demo;
Notez que CREATE INDEX ne peut pas être utilisé pour créer un index primaire, mais ALTER TABLE est utilisé.

Dans la capture d'écran ci-dessus, nous voyons qu'un index primaire est créé sur la colonne phone_no . Les colonnes des images suivantes sont décrites comme suit :
Table :La table sur laquelle l'index est créé.
Non_unique :Si la valeur est 1, l'index n'est pas unique, si la valeur est 0, l'index est unique.
Key_name :Le nom de l'index créé. Le nom de l'index primaire est toujours PRIMARY dans MySQL, que vous ayez fourni ou non un nom d'index lors de la création de l'index.
Seq_in_index :Le numéro de séquence de la colonne dans l'index. Si plusieurs colonnes font partie de l'index, le numéro de séquence sera attribué en fonction de l'ordre des colonnes au moment de la création de l'index. Le numéro de séquence commence à partir de 1.
Collation :comment la colonne est triée dans l'index. A signifie ascendant, D signifie décroissant, NULL signifie non trié.
Cardinality :nombre estimé de valeurs uniques dans l'index. Plus de cardinalité signifie plus de chances que l'optimiseur de requête sélectionne l'index pour les requêtes.
Sub_part :Le préfixe d'index. C'est NULL si toute la colonne est indexée. Sinon, il affiche le nombre d'octets indexés au cas où la colonne serait partiellement indexée. Nous définirons l'index partiel plus tard.
Packed :Indique comment la clé est emballée ; NULL si ce n'est pas le cas.
Null :YES si la colonne peut contenir NULL valeurs et vide si ce n'est pas le cas.
Index_type :Indique quelle structure de données d'indexation est utilisée pour cet index. Certains candidats possibles sont - BTREE , HASH , RTREE , ou FULLTEXT .
Comment :Les informations sur l'index non décrites dans sa propre colonne.
Index_comment :Le commentaire de l'index spécifié lors de la création de l'index avec le COMMENT attribut.
Voyons maintenant si cet index réduit le nombre de lignes qui seront recherchées pour un phone_no donné dans le WHERE clause d'une requête.
EXPLAIN SELECT * FROM index_demo WHERE phone_no = '9281072002';
Dans cet instantané, notez que les rows la colonne a renvoyé 1 uniquement, les possible_keys &key les deux renvoient PRIMARY . Cela signifie donc essentiellement que l'utilisation de l'index primaire nommé PRIMARY (le nom est automatiquement attribué lorsque vous créez la clé primaire), l'optimiseur de requête va simplement directement à l'enregistrement et le récupère. C'est très efficace. C'est exactement à cela que sert un index :minimiser la portée de la recherche au détriment de l'espace supplémentaire.
Index cluster :
Un clustered index est colocalisé avec les données dans le même espace table ou le même fichier disque. On peut considérer qu'un index clusterisé est un B-Tree index dont les nœuds feuilles sont les blocs de données réels sur le disque, puisque l'index et les données résident ensemble. Ce type d'index organise physiquement les données sur le disque selon l'ordre logique de la clé d'index.
Que signifie l'organisation physique des données ?
Physiquement, les données sont organisées sur disque à travers des milliers ou des millions de blocs de disque/données. Pour un index clusterisé, il n'est pas obligatoire que tous les blocs du disque soient stockés de manière contagieuse. Les blocs de données physiques sont tout le temps déplacés ici et là par le système d'exploitation chaque fois que cela est nécessaire. Un système de base de données n'a aucun contrôle absolu sur la gestion de l'espace physique des données, mais à l'intérieur d'un bloc de données, les enregistrements peuvent être stockés ou gérés dans l'ordre logique de la clé d'index. Le schéma simplifié suivant l'explique :
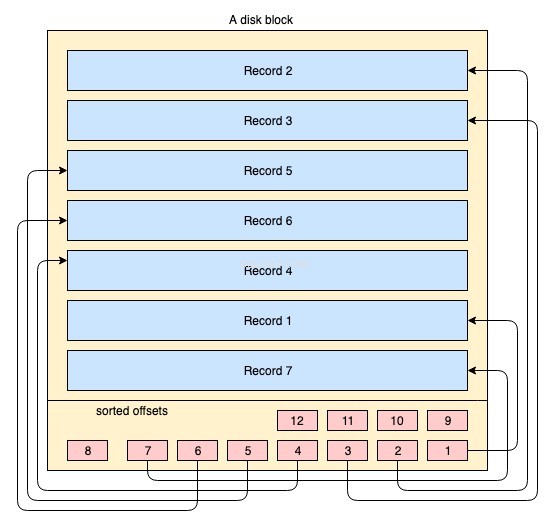
- Le grand rectangle de couleur jaune représente un bloc de disque/bloc de données
- les rectangles de couleur bleue représentent les données stockées sous forme de lignes à l'intérieur de ce bloc
- la zone de pied de page représente l'index du bloc où résident les petits rectangles de couleur rouge dans l'ordre trié d'une clé particulière. Ces petits blocs ne sont rien d'autre que des sortes de pointeurs pointant vers les décalages des enregistrements.
Les enregistrements sont stockés sur le bloc de disque dans n'importe quel ordre arbitraire. Chaque fois que de nouveaux enregistrements sont ajoutés, ils sont ajoutés dans le prochain espace disponible. Chaque fois qu'un enregistrement existant est mis à jour, le système d'exploitation décide si cet enregistrement peut toujours tenir dans la même position ou si une nouvelle position doit être attribuée à cet enregistrement.
Ainsi, la position des enregistrements est entièrement gérée par le système d'exploitation et aucune relation définie n'existe entre l'ordre de deux enregistrements. Afin de récupérer les enregistrements dans l'ordre logique de la clé, les pages de disque contiennent une section d'index dans le pied de page, l'index contient une liste de pointeurs décalés dans l'ordre de la clé. Chaque fois qu'un enregistrement est modifié ou créé, l'index est ajusté.
De cette façon, vous n'avez vraiment pas besoin de vous soucier d'organiser l'enregistrement physique dans un certain ordre, une petite section d'index est plutôt maintenue dans cet ordre et la récupération ou la maintenance des enregistrements devient très facile.
Avantage de l'index cluster :
Cet ordre ou cette co-localisation des données associées rend en fait un index clusterisé plus rapide. Lorsque les données sont extraites du disque, le bloc complet contenant les données est lu par le système puisque notre système d'E/S de disque écrit et lit les données par blocs. Ainsi, en cas de requêtes de plage, il est tout à fait possible que les données colocalisées soient mises en mémoire tampon. Supposons que vous lancez la requête suivante :
SELECT * FROM index_demo WHERE phone_no > '9010000000' AND phone_no < '9020000000'
Un bloc de données est récupéré en mémoire lorsque la requête est exécutée. Disons que le bloc de données contient phone_no dans la plage de 9010000000 à 9030000000 . Ainsi, quelle que soit la plage que vous avez demandée dans la requête, il ne s'agit que d'un sous-ensemble des données présentes dans le bloc. Si vous lancez maintenant la requête suivante pour obtenir tous les numéros de téléphone de la plage, dites de 9015000000 à 9019000000 , vous n'avez plus besoin de récupérer de blocs sur le disque. Les données complètes peuvent être trouvées dans le bloc de données actuel, donc clustered_index réduit le nombre d'E/S disque en colocalisant autant que possible les données associées dans le même bloc de données. Cette réduction des E/S disque entraîne une amélioration des performances.
Donc, si vous avez une bonne idée de la clé primaire et que vos requêtes sont basées sur la clé primaire, les performances seront super rapides.
Contraintes de l'index clusterisé :
Étant donné qu'un index clusterisé a un impact sur l'organisation physique des données, il ne peut y avoir qu'un seul index clusterisé par table.
Relation entre la clé primaire et l'index cluster :
Vous ne pouvez pas créer manuellement un index clusterisé à l'aide d'InnoDB dans MySQL. MySQL le choisit pour vous. Mais comment choisit-il ? Les extraits suivants proviennent de la documentation MySQL :
Lorsque vous définissez unePRIMARY KEYsur votre table,InnoDBl'utilise comme index clusterisé. Définissez une clé primaire pour chaque table que vous créez. S'il n'y a pas de colonne ou d'ensemble de colonnes logiques uniques et non nulles, ajoutez une nouvelle colonne à incrémentation automatique, dont les valeurs sont remplies automatiquement.
Si vous ne définissez pas dePRIMARY KEYpour votre table, MySQL localise le premierUNIQUEindex où toutes les colonnes clés sontNOT NULLetInnoDBl'utilise comme index clusterisé.
Si la table n'a pas dePRIMARY KEYouUNIQUEapproprié index,InnoDBgénère en interne un index cluster caché nomméGEN_CLUST_INDEXsur une colonne synthétique contenant des valeurs d'ID de ligne. Les lignes sont triées par l'ID queInnoDBattribue aux lignes d'une telle table. L'ID de ligne est un champ de 6 octets qui augmente de manière monotone à mesure que de nouvelles lignes sont insérées. Ainsi, les lignes triées par l'ID de ligne sont physiquement dans l'ordre d'insertion.
En bref, le moteur MySQL InnoDB gère en fait l'index primaire en tant qu'index clusterisé pour améliorer les performances, de sorte que la clé primaire et l'enregistrement réel sur le disque sont regroupés.
Structure de l'index de clé primaire (cluster) :
Un index est généralement conservé sous forme d'arborescence B+ sur disque et en mémoire, et tout index est stocké dans des blocs sur disque. Ces blocs sont appelés blocs d'index. Les entrées du bloc d'index sont toujours triées sur la clé d'index/recherche. Le bloc d'index feuille de l'index contient un localisateur de ligne. Pour l'index primaire, le localisateur de ligne fait référence à l'adresse virtuelle de l'emplacement physique correspondant des blocs de données sur le disque où résident les lignes triées selon la clé d'index.
Dans le diagramme suivant, les rectangles de gauche représentent les blocs d'index de niveau feuille et les rectangles de droite représentent les blocs de données. Logiquement, les blocs de données semblent être alignés dans un ordre trié, mais comme déjà décrit précédemment, les emplacements physiques réels peuvent être dispersés ici et là.
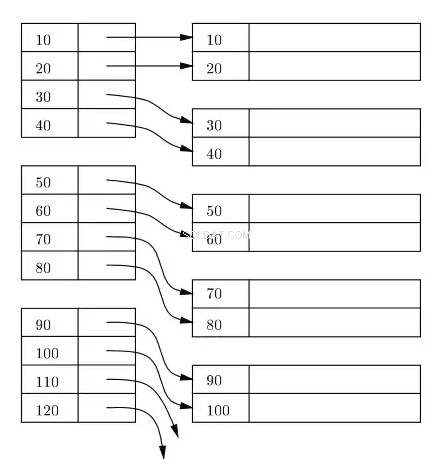
Est-il possible de créer un index primaire sur une clé non primaire ?
Dans MySQL, un index primaire est automatiquement créé, et nous avons déjà décrit ci-dessus comment MySQL choisit l'index primaire. Mais dans le monde des bases de données, il n'est en fait pas nécessaire de créer un index sur la colonne de clé primaire - l'index primaire peut également être créé sur n'importe quelle colonne de clé non primaire. Mais lorsqu'elles sont créées sur la clé primaire, toutes les entrées de clé sont uniques dans l'index, tandis que dans l'autre cas, l'index primaire peut également avoir une clé dupliquée.
Est-il possible de supprimer une clé primaire ?
Il est possible de supprimer une clé primaire. Lorsque vous supprimez une clé primaire, l'index clusterisé associé ainsi que la propriété d'unicité de cette colonne sont perdus.
ALTER TABLE `index_demo` DROP PRIMARY KEY;
- If the primary key does not exist, you get the following error:
"ERROR 1091 (42000): Can't DROP 'PRIMARY'; check that column/key exists"Avantages de l'index primaire :
- Les requêtes de plage basées sur l'index principal sont très efficaces. Il est possible que le bloc de disque que la base de données a lu à partir du disque contienne toutes les données appartenant à la requête, puisque l'index principal est en cluster et que les enregistrements sont triés physiquement. Ainsi, la localité des données peut être fournie par l'index primaire.
- Toute requête qui tire parti de la clé primaire est très rapide.
Inconvénients de l'index primaire :
- Étant donné que l'index principal contient une référence directe à l'adresse du bloc de données via l'espace d'adressage virtuel et que les blocs de disque sont physiquement organisés dans l'ordre de la clé d'index, chaque fois que le système d'exploitation effectue une division de page de disque en raison de
DMLopérations commeINSERT/UPDATE/DELETE, l'index principal doit également être mis à jour. DoncDMLopérations exerce une certaine pression sur les performances de l'index principal.
Index secondaire :
Tout index autre qu'un index clusterisé est appelé index secondaire. Les index secondaires n'ont pas d'impact sur les emplacements de stockage physiques contrairement aux index primaires.
Quand avez-vous besoin d'un index secondaire ?
Vous pouvez avoir plusieurs cas d'utilisation dans votre application où vous n'interrogez pas la base de données avec une clé primaire. Dans notre exemple phone_no est la clé primaire mais nous devrons peut-être interroger la base de données avec pan_no , ou name . Dans de tels cas, vous avez besoin d'index secondaires sur ces colonnes si la fréquence de ces requêtes est très élevée.
Comment créer un index secondaire dans MySQL ?
La commande suivante crée un index secondaire dans le name colonne dans index_demo tableau.
CREATE INDEX secondary_idx_1 ON index_demo (name);
Structure de l'index secondaire :
Dans le diagramme ci-dessous, les rectangles de couleur rouge représentent les blocs d'index secondaires. L'index secondaire est également conservé dans l'arborescence B+ et il est trié selon la clé sur laquelle l'index a été créé. Les nœuds feuilles contiennent une copie de la clé des données correspondantes dans l'index primaire.
Donc, pour comprendre, vous pouvez supposer que l'index secondaire fait référence à l'adresse de la clé primaire, bien que ce ne soit pas le cas. Récupérer des données via l'index secondaire signifie que vous devez traverser deux arbres B+ - l'un est l'arbre B+ de l'index secondaire lui-même, et l'autre est l'arbre B+ de l'index primaire.
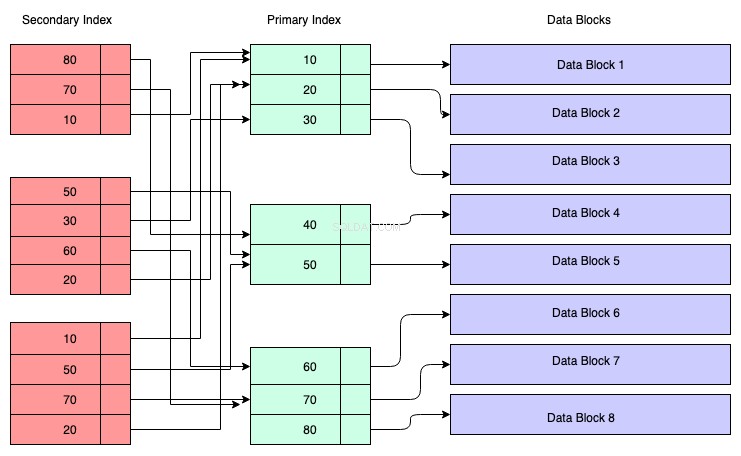
Avantages d'un index secondaire :
Logiquement, vous pouvez créer autant d'index secondaires que vous le souhaitez. Mais en réalité, le nombre d'indices réellement requis nécessite un processus de réflexion sérieux puisque chaque indice a sa propre pénalité.
Inconvénients d'un index secondaire :
Avec DML opérations comme DELETE / INSERT , l'index secondaire doit également être mis à jour afin que la copie de la colonne de clé primaire puisse être supprimée/insérée. Dans de tels cas, l'existence de nombreux index secondaires peut créer des problèmes.
Aussi, si une clé primaire est très grande comme une URL , puisque les index secondaires contiennent une copie de la valeur de la colonne de clé primaire, cela peut être inefficace en termes de stockage. Plus de clés secondaires signifie un plus grand nombre de copies en double de la valeur de la colonne de clé primaire, donc plus de stockage en cas de grande clé primaire. De plus, la clé primaire elle-même stocke les clés, de sorte que l'effet combiné sur le stockage sera très élevé.
Considération avant de supprimer un index primaire :
Dans MySQL, vous pouvez supprimer un index primaire en supprimant la clé primaire. Nous avons déjà vu qu'un index secondaire dépend d'un index primaire. Ainsi, si vous supprimez un index primaire, tous les index secondaires doivent être mis à jour pour contenir une copie de la nouvelle clé d'index primaire que MySQL ajuste automatiquement.
Ce processus est coûteux lorsque plusieurs index secondaires existent. De plus, d'autres tables peuvent avoir une référence de clé étrangère à la clé primaire, vous devez donc supprimer ces références de clé étrangère avant de supprimer la clé primaire.
Lorsqu'une clé primaire est supprimée, MySQL crée automatiquement une autre clé primaire en interne, et c'est une opération coûteuse.
Index de clé UNIQUE :
Comme les clés primaires, les clés uniques peuvent également identifier les enregistrements de manière unique avec une différence :la colonne de clé unique peut contenir null valeurs.
Contrairement à d'autres serveurs de base de données, dans MySQL, une colonne de clé unique peut avoir autant de null valeurs que possible. Dans la norme SQL, null signifie une valeur indéfinie. Donc si MySQL ne doit contenir qu'un seul null valeur dans une colonne de clé unique, il doit supposer que toutes les valeurs nulles sont identiques.
Mais logiquement ce n'est pas correct puisque null signifie indéfini - et les valeurs indéfinies ne peuvent pas être comparées les unes aux autres, c'est la nature de null . Comme MySQL ne peut pas affirmer si tout est null s signifie la même chose, il permet plusieurs null valeurs dans la colonne.
La commande suivante montre comment créer un index de clé unique dans MySQL :
CREATE UNIQUE INDEX unique_idx_1 ON index_demo (pan_no);
Indice composite :
MySQL vous permet de définir des index sur plusieurs colonnes, jusqu'à 16 colonnes. Cet index s'appelle un index Multi-colonnes / Composite / Composé.
Disons que nous avons un index défini sur 4 colonnes — col1 , col2 , col3 , col4 . Avec un index composite, nous avons une capacité de recherche sur col1 , (col1, col2) , (col1, col2, col3) , (col1, col2, col3, col4) . Nous pouvons donc utiliser n'importe quel préfixe du côté gauche des colonnes indexées, mais nous ne pouvons pas omettre une colonne du milieu et l'utiliser comme - (col1, col3) ou (col1, col2, col4) ou col3 ou col4 etc. Ce sont des combinaisons invalides.
Les commandes suivantes créent 2 index composites dans notre table :
CREATE INDEX composite_index_1 ON index_demo (phone_no, name, age);
CREATE INDEX composite_index_2 ON index_demo (pan_no, name, age);
Si vous avez des requêtes contenant un WHERE clause sur plusieurs colonnes, écrivez la clause dans l'ordre des colonnes de l'index composite. L'index bénéficiera de cette requête. En fait, tout en décidant des colonnes d'un index composite, vous pouvez analyser différents cas d'utilisation de votre système et essayer de trouver l'ordre des colonnes qui profitera à la plupart de vos cas d'utilisation.
Les indices composites peuvent vous aider dans JOIN &SELECT des requêtes également. Exemple :dans le SELECT * suivant requête, composite_index_2 est utilisé.

Lorsque plusieurs index sont définis, l'optimiseur de requête MySQL choisit l'index qui élimine le plus grand nombre de lignes ou parcourt le moins de lignes possible pour une meilleure efficacité.
Pourquoi utilisons-nous des indices composites ? ? Pourquoi ne pas définir plusieurs index secondaires sur les colonnes qui nous intéressent ?
MySQL utilise un seul index par table par requête sauf pour UNION. (Dans une UNION, chaque requête logique est exécutée séparément et les résultats sont fusionnés.) Ainsi, la définition de plusieurs index sur plusieurs colonnes ne garantit pas que ces index seront utilisés même s'ils font partie de la requête.
MySQL maintient quelque chose appelé statistiques d'index qui aide MySQL à déduire à quoi ressemblent les données dans le système. Les statistiques d'index sont cependant une généralisation, mais sur la base de ces métadonnées, MySQL décide quel index est approprié pour la requête actuelle.
Comment fonctionne l'index composite ?
Les colonnes utilisées dans les index composites sont concaténées ensemble, et ces clés concaténées sont stockées dans un ordre trié à l'aide d'un arbre B+. Lorsque vous effectuez une recherche, la concaténation de vos clés de recherche est comparée à celles de l'index composite. Ensuite, s'il y a une incohérence entre l'ordre de vos clés de recherche et l'ordre des colonnes de l'index composite, l'index ne peut pas être utilisé.
Dans notre exemple, pour l'enregistrement suivant, une clé d'index composite est formée en concaténant pan_no , name , age — HJKXS9086Wkousik28 .
+--------+------+------------+------------+
name
age
pan_no
phone_no
+--------+------+------------+------------+
kousik
28
HJKXS9086W
9090909090Comment déterminer si vous avez besoin d'un index composite :
- Analysez d'abord vos requêtes en fonction de vos cas d'utilisation. Si vous constatez que certains champs apparaissent ensemble dans de nombreuses requêtes, vous pouvez envisager de créer un index composite.
- Si vous créez un index dans
col1&un index composite dans (col1,col2), alors seul l'index composite devrait convenir.col1seul peut être servi par l'index composite lui-même puisqu'il s'agit d'un préfixe du côté gauche de l'index. - Tenez compte de la cardinalité. Si les colonnes utilisées dans l'index composite finissent par avoir ensemble une cardinalité élevée, elles sont de bons candidats pour l'index composite.
Index de couverture :
Un index de couverture est un type spécial d'index composite où toutes les colonnes spécifiées dans la requête existent quelque part dans l'index. Ainsi, l'optimiseur de requête n'a pas besoin d'accéder à la base de données pour obtenir les données, il obtient plutôt le résultat de l'index lui-même. Exemple :nous avons déjà défini un index composite sur (pan_no, name, age) , alors considérons maintenant la requête suivante :
SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = 'kousik'
Les colonnes mentionnées dans le SELECT &WHERE les clauses font partie de l'indice composite. Donc, dans ce cas, nous pouvons réellement obtenir la valeur de age colonne de l'index composite lui-même. Voyons ce que le EXPLAIN commande s'affiche pour cette requête :
EXPLAIN FORMAT=JSON SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = '111kousik1';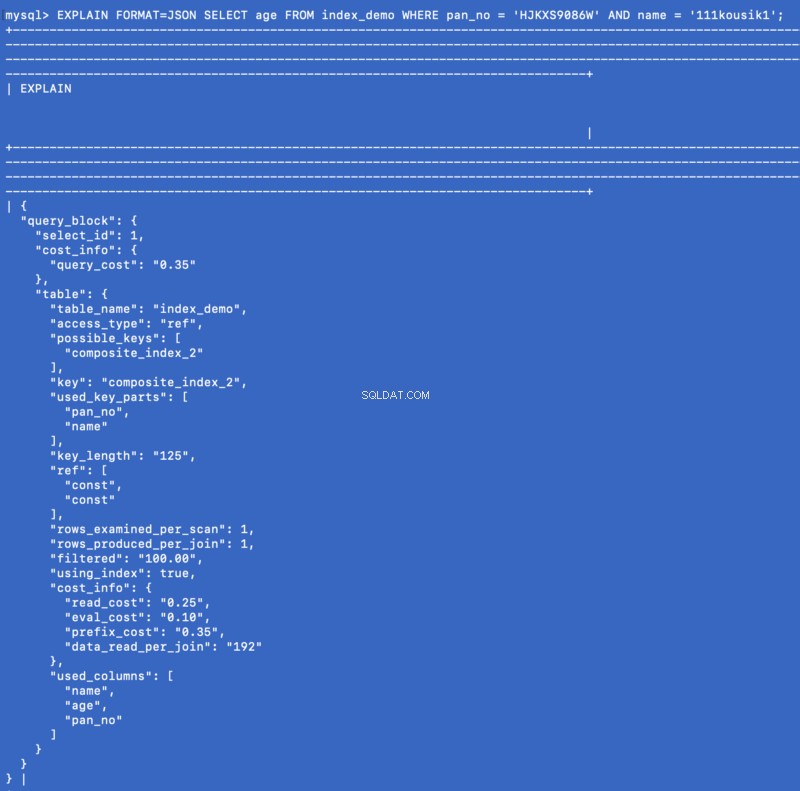
Dans la réponse ci-dessus, notez qu'il y a une clé - using_index qui est défini sur true ce qui signifie que l'index de recouvrement a été utilisé pour répondre à la requête.
Je ne sais pas à quel point les index de couverture sont appréciés dans les environnements de production, mais apparemment, cela semble être une bonne optimisation au cas où la requête conviendrait.
Index partiel :
Nous savons déjà que les indices accélèrent nos requêtes au détriment de l'espace. Plus vous avez d'indices, plus les besoins en stockage sont importants. Nous avons déjà créé un index appelé secondary_idx_1 sur la colonne name . La colonne name peut contenir de grandes valeurs de n'importe quelle longueur. Toujours dans l'index, les métadonnées des localisateurs de ligne ou des pointeurs de ligne ont leur propre taille. Donc, dans l'ensemble, un index peut avoir une charge de stockage et de mémoire élevée.
Dans MySQL, il est également possible de créer un index sur les premiers octets de données. Exemple :la commande suivante crée un index sur les 4 premiers octets de nom. Bien que cette méthode réduise la surcharge de mémoire d'une certaine quantité, l'index ne peut pas éliminer de nombreuses lignes, car dans cet exemple, les 4 premiers octets peuvent être communs à de nombreux noms. Habituellement, ce type d'indexation de préfixe est pris en charge sur CHAR ,VARCHAR , BINARY , VARBINARY type de colonnes.
CREATE INDEX secondary_index_1 ON index_demo (name(4));Que se passe-t-il sous le capot lorsque nous définissons un index ?
Lançons le SHOW EXTENDED commande à nouveau :
SHOW EXTENDED INDEXES FROM index_demo;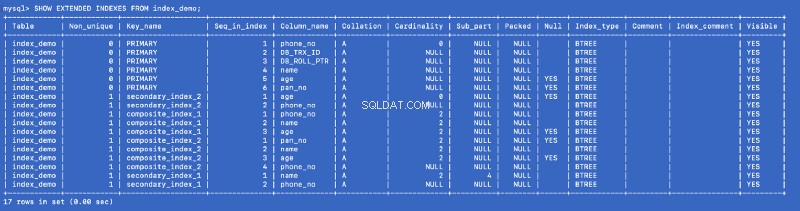
Nous avons défini secondary_index_1 sur name , mais MySQL a créé un index composite sur (name , phone_no ) où phone_no est la colonne de clé primaire. Nous avons créé secondary_index_2 sur age &MySQL a créé un index composite sur (age , phone_no ). Nous avons créé composite_index_2 sur (pan_no , name , age ) &MySQL a créé un index composite sur (pan_no , name , age , phone_no ). L'indice composite composite_index_1 a déjà phone_no dans le cadre de celui-ci.
Ainsi, quel que soit l'index que nous créons, MySQL crée en arrière-plan un index composite de support qui, à son tour, pointe vers la clé primaire. Cela signifie que la clé primaire est un citoyen de première classe dans le monde de l'indexation MySQL. It also proves that all the indexes are backed by a copy of the primary index —but I am not sure whether a single copy of the primary index is shared or different copies are used for different indexes.
There are many other indices as well like Spatial index and Full Text Search index offered by MySQL. I have not yet experimented with those indices, so I’m not discussing them in this post.
General Indexing guidelines:
- Since indices consume extra memory, carefully decide how many &what type of index will suffice your need.
- With
DMLoperations, indices are updated, so write operations are quite costly with indexes. The more indices you have, the greater the cost. Indexes are used to make read operations faster. So if you have a system that is write heavy but not read heavy, think hard about whether you need an index or not. - Cardinality is important — cardinality means the number of distinct values in a column. If you create an index in a column that has low cardinality, that’s not going to be beneficial since the index should reduce search space. Low cardinality does not significantly reduce search space.
Example:if you create an index on a boolean (int1or0only ) type column, the index will be very skewed since cardinality is less (cardinality is 2 here). But if this boolean field can be combined with other columns to produce high cardinality, go for that index when necessary. - Indices might need some maintenance as well if old data still remains in the index. They need to be deleted otherwise memory will be hogged, so try to have a monitoring plan for your indices.
In the end, it’s extremely important to understand the different aspects of database indexing. It will help while doing low level system designing. Many real-life optimizations of our applications depend on knowledge of such intricate details. A carefully chosen index will surely help you boost up your application’s performance.
Please do clap &share with your friends &on social media if you like this article. :)
References:
- https://dev.mysql.com/doc/refman/5.7/en/innodb-index-types.html
- https://www.quora.com/What-is-difference-between-primary-index-and-secondary-index-exactly-And-whats-advantage-of-one-over-another
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html
- https://www.oreilly.com/library/view/high-performance-mysql/0596003064/ch04.html
- https://www.unofficialmysqlguide.com/covering-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/multiple-column-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/show-index.html
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html