La surveillance est l'une des tâches fondamentales de tout système. Cela peut nous aider à détecter les problèmes et à prendre des mesures, ou simplement à connaître l'état actuel de nos systèmes. L'utilisation d'affichages visuels peut nous rendre plus efficaces, car nous pouvons détecter plus facilement les problèmes de performances.
Dans ce blog, nous verrons comment utiliser SCUMM pour surveiller nos bases de données PostgreSQL et quelles métriques nous pouvons utiliser pour cette tâche. Nous passerons également en revue les tableaux de bord disponibles, afin que vous puissiez facilement comprendre ce qui se passe réellement avec vos instances PostgreSQL.
Qu'est-ce que SCUMM ?
Tout d'abord, voyons ce qu'est SCUMM (Severalnines ClusterControl Unified Monitoring and Management).
Il s'agit d'une nouvelle solution basée sur des agents avec des agents installés sur les nœuds de la base de données.
Les agents SCUMM sont des exportateurs Prometheus qui exportent des métriques à partir de services comme PostgreSQL en tant que métriques Prometheus.
Un serveur Prometheus est utilisé pour récupérer et stocker les données de séries chronologiques des agents SCUMM.
Prometheus est une boîte à outils open-source de surveillance et d'alerte du système, conçue à l'origine sur SoundCloud. Il s'agit désormais d'un projet open source autonome et maintenu de manière indépendante.
Prometheus est conçu pour être fiable, pour être le système vers lequel vous vous dirigez pendant une panne afin de vous permettre de diagnostiquer rapidement les problèmes.
Comment utiliser SCUMM ?
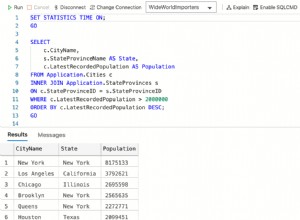
Lorsque vous utilisez ClusterControl, lorsque nous sélectionnons un cluster, nous pouvons voir un aperçu de nos bases de données, ainsi que certaines métriques de base qui peuvent être utilisées pour identifier un problème. Dans le tableau de bord ci-dessous, nous pouvons voir une configuration maître-esclave avec un maître et 2 esclaves, avec HAProxy et Keepalived.
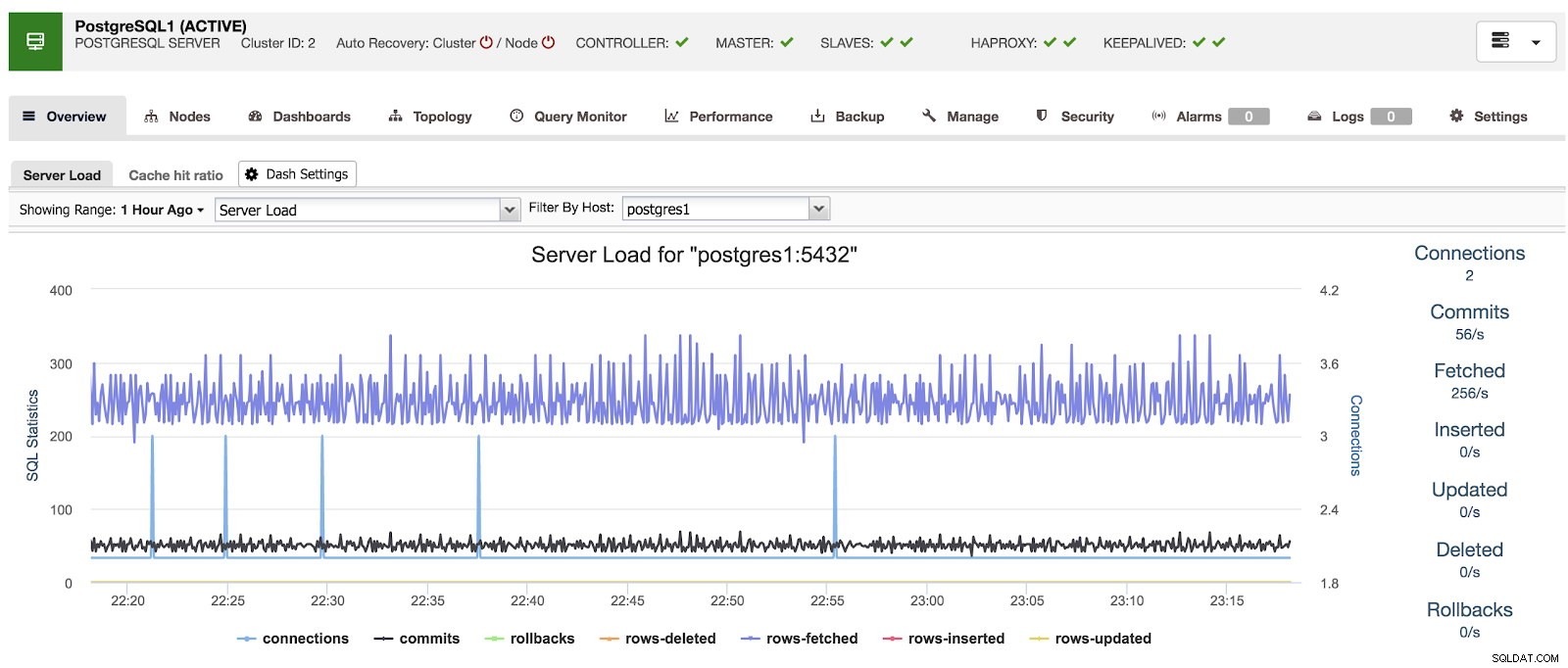 Présentation de ClusterControl
Présentation de ClusterControl Si nous allons à l'option "Tableaux de bord", nous pouvons voir un message comme le suivant.
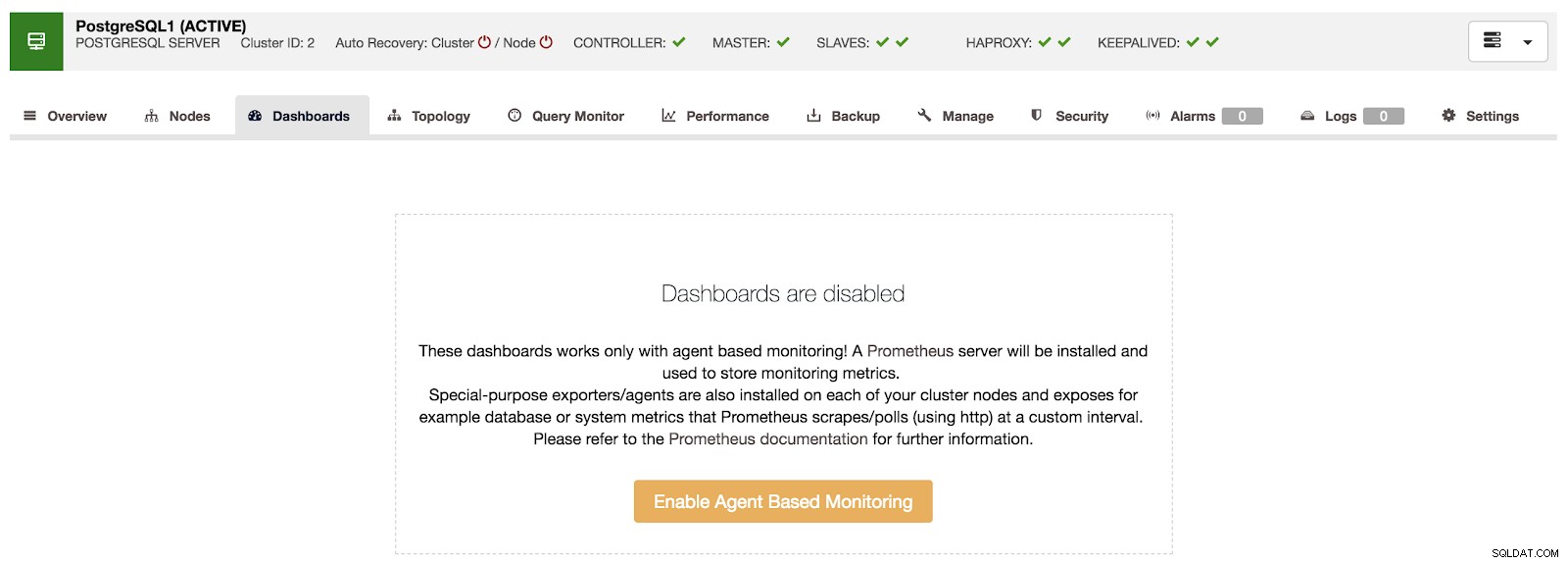 Tableaux de bord ClusterControl désactivés
Tableaux de bord ClusterControl désactivés Pour utiliser cette fonctionnalité, nous devons activer l'agent mentionné ci-dessus. Pour cela, nous n'avons qu'à appuyer sur le bouton "Activer la surveillance basée sur l'agent" dans cette section.
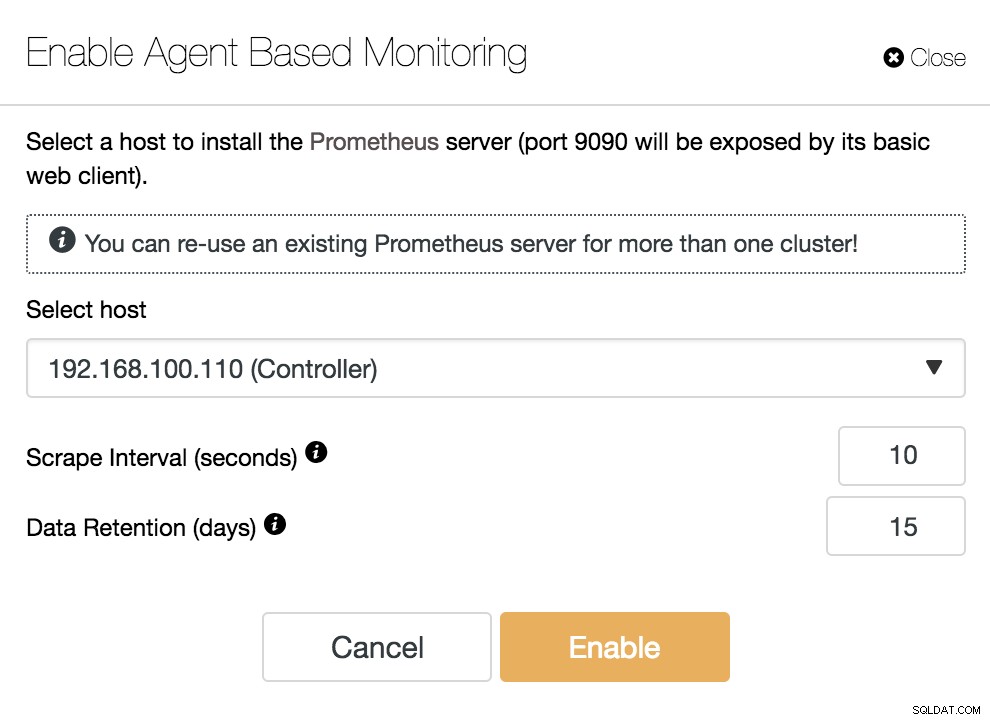 ClusterControl Activer la surveillance basée sur l'agent
ClusterControl Activer la surveillance basée sur l'agent Pour activer notre agent, nous devons spécifier l'hôte sur lequel nous installerons notre serveur Prometheus, qui, comme nous pouvons le voir dans l'exemple, peut être notre serveur ClusterControl.
Nous devons également préciser :
- Scrape Interval (seconds) :définissez la fréquence à laquelle les nœuds sont récupérés pour les métriques. La valeur par défaut est de 10 secondes.
- Conservation des données (jours) :définissez la durée pendant laquelle les statistiques sont conservées avant d'être supprimées. La valeur par défaut est de 15 jours.
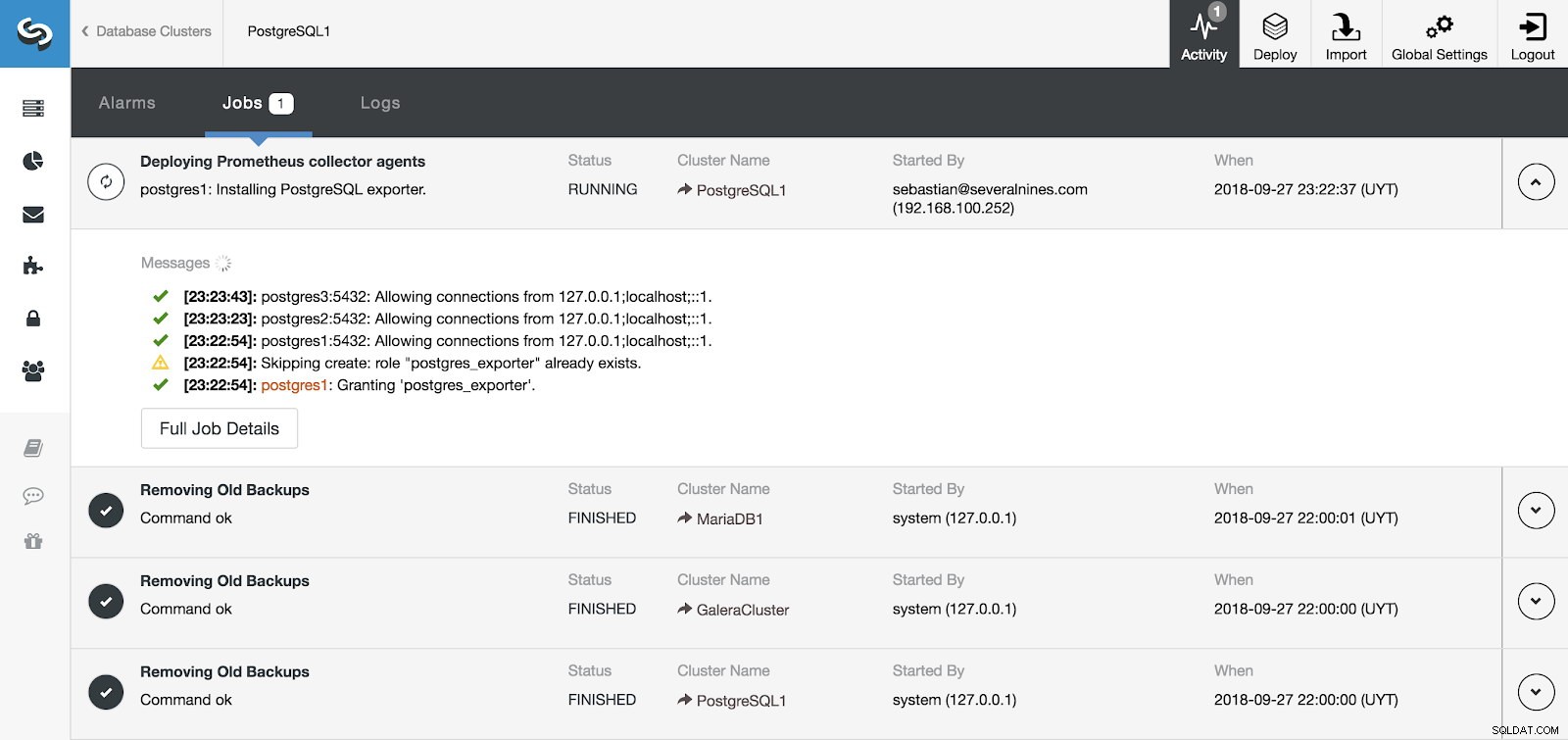 Section d'activité de contrôle de cluster
Section d'activité de contrôle de cluster Nous pouvons surveiller l'installation de notre serveur et de nos agents depuis la section Activité de ClusterControl et, une fois terminée, nous pouvons voir notre cluster avec les agents activés depuis l'écran principal de ClusterControl.
 Agents ClusterControl activés
Agents ClusterControl activés Tableaux de bord
Une fois nos agents activés, si nous allons dans la section Tableaux de bord, nous verrons quelque chose comme ceci :
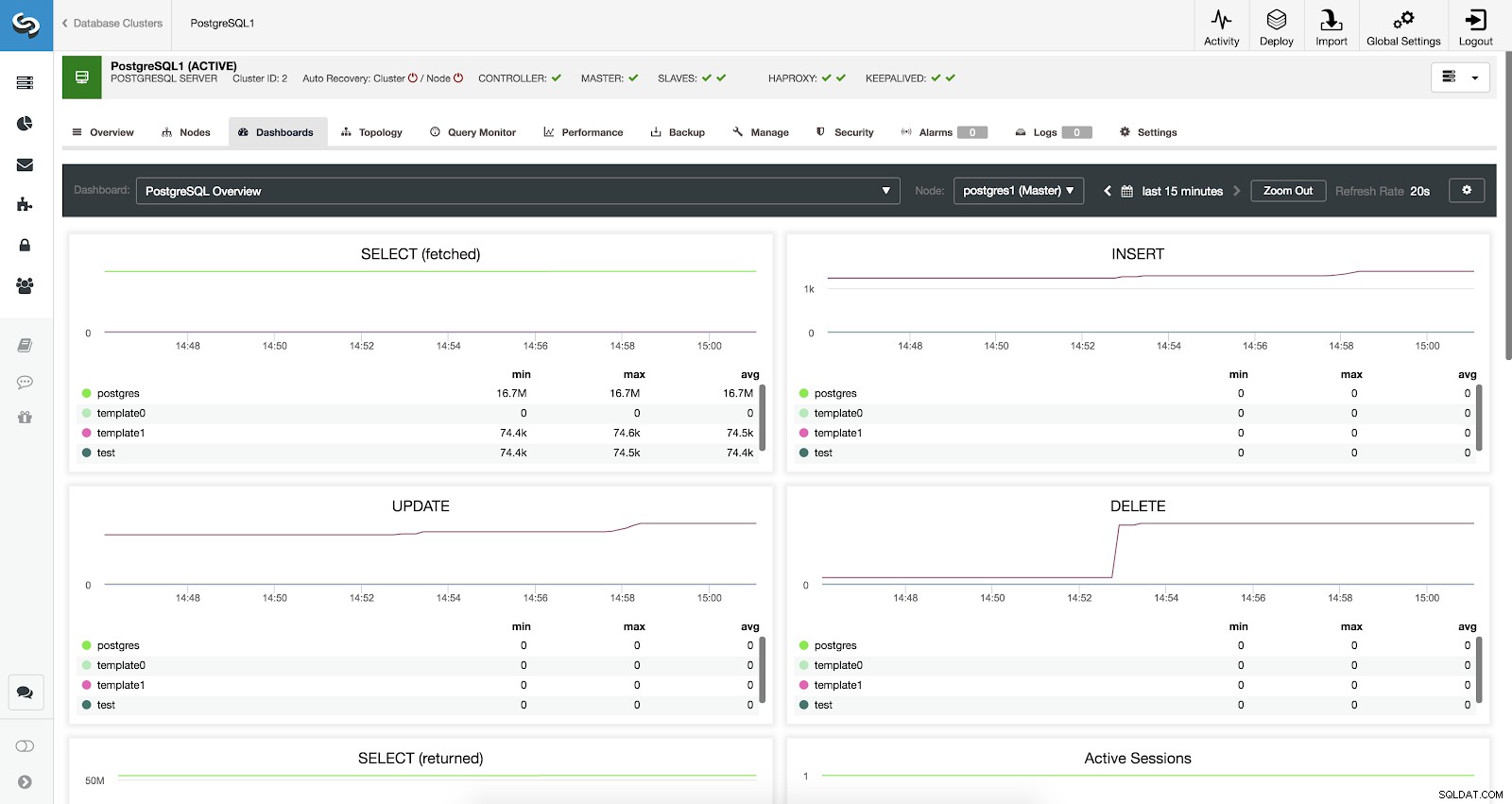 Tableaux de bord ClusterControl activés
Tableaux de bord ClusterControl activés Nous avons trois différents types de tableaux de bord disponibles, la vue d'ensemble du système, les graphiques inter-serveurs et la vue d'ensemble de PostgreSQL. Le dernier est ce que nous voyons par défaut en entrant dans cette section.
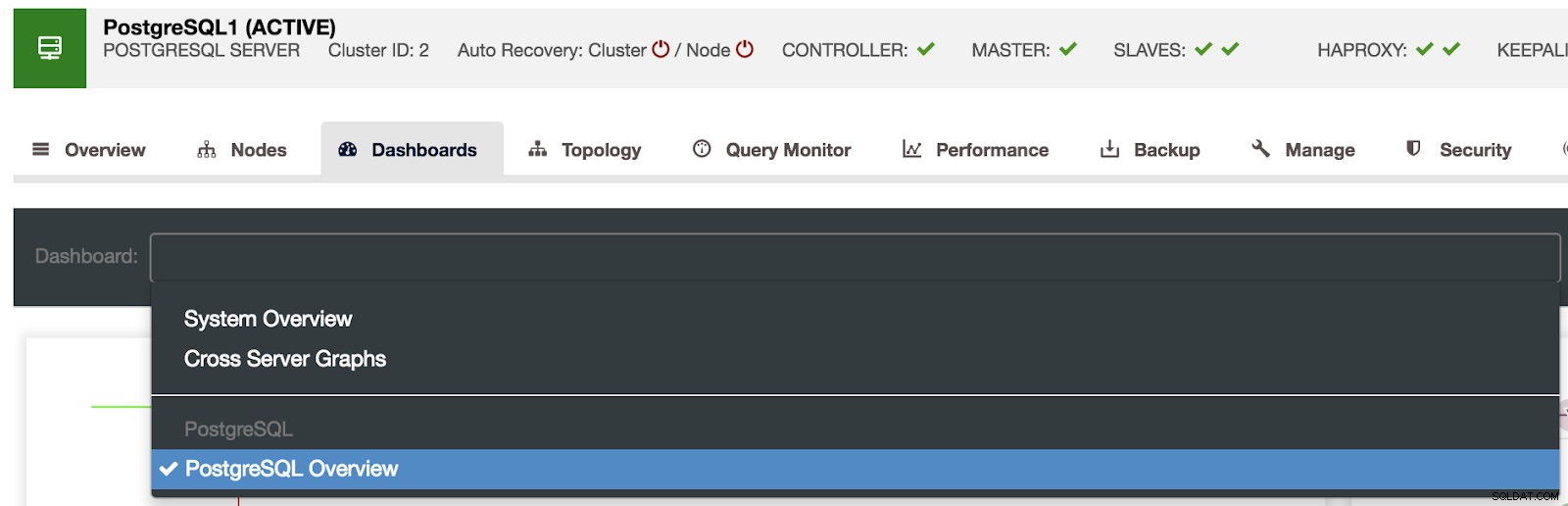 Sélection des tableaux de bord ClusterControl
Sélection des tableaux de bord ClusterControl Ici, nous pouvons également spécifier le nœud à surveiller, la plage de temps et le taux de rafraîchissement.
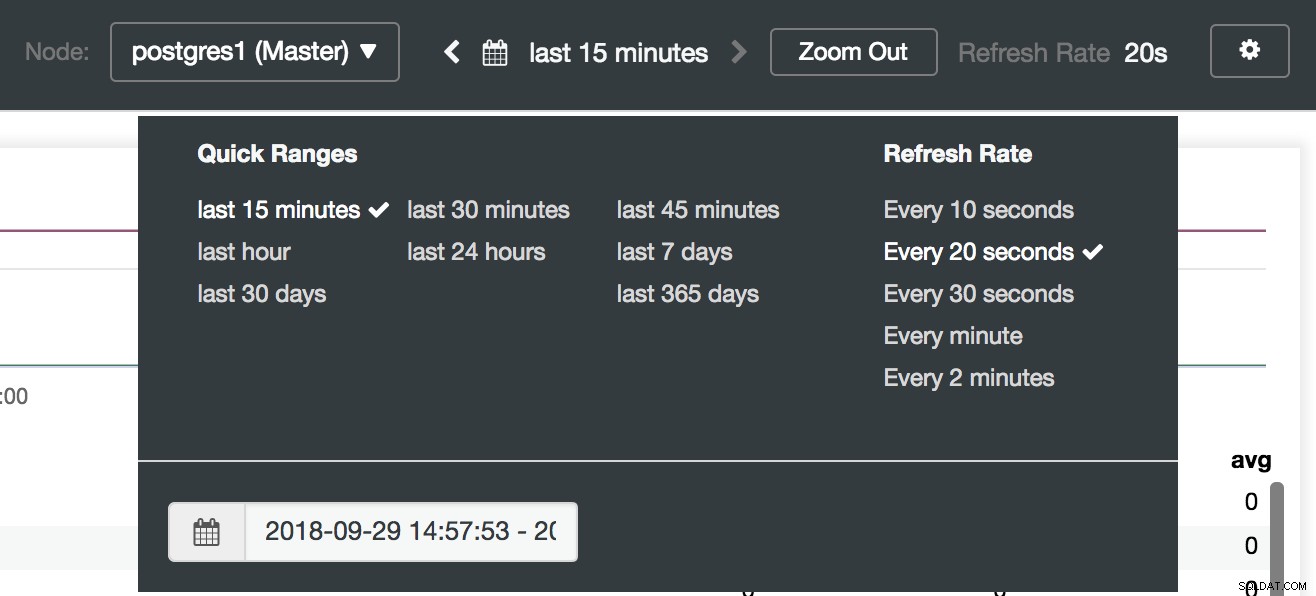 Options du tableau de bord ClusterControl
Options du tableau de bord ClusterControl Dans la section de configuration, nous pouvons activer ou désactiver nos agents (exportateurs), vérifier l'état des agents et vérifier la version de notre serveur Prometheus.
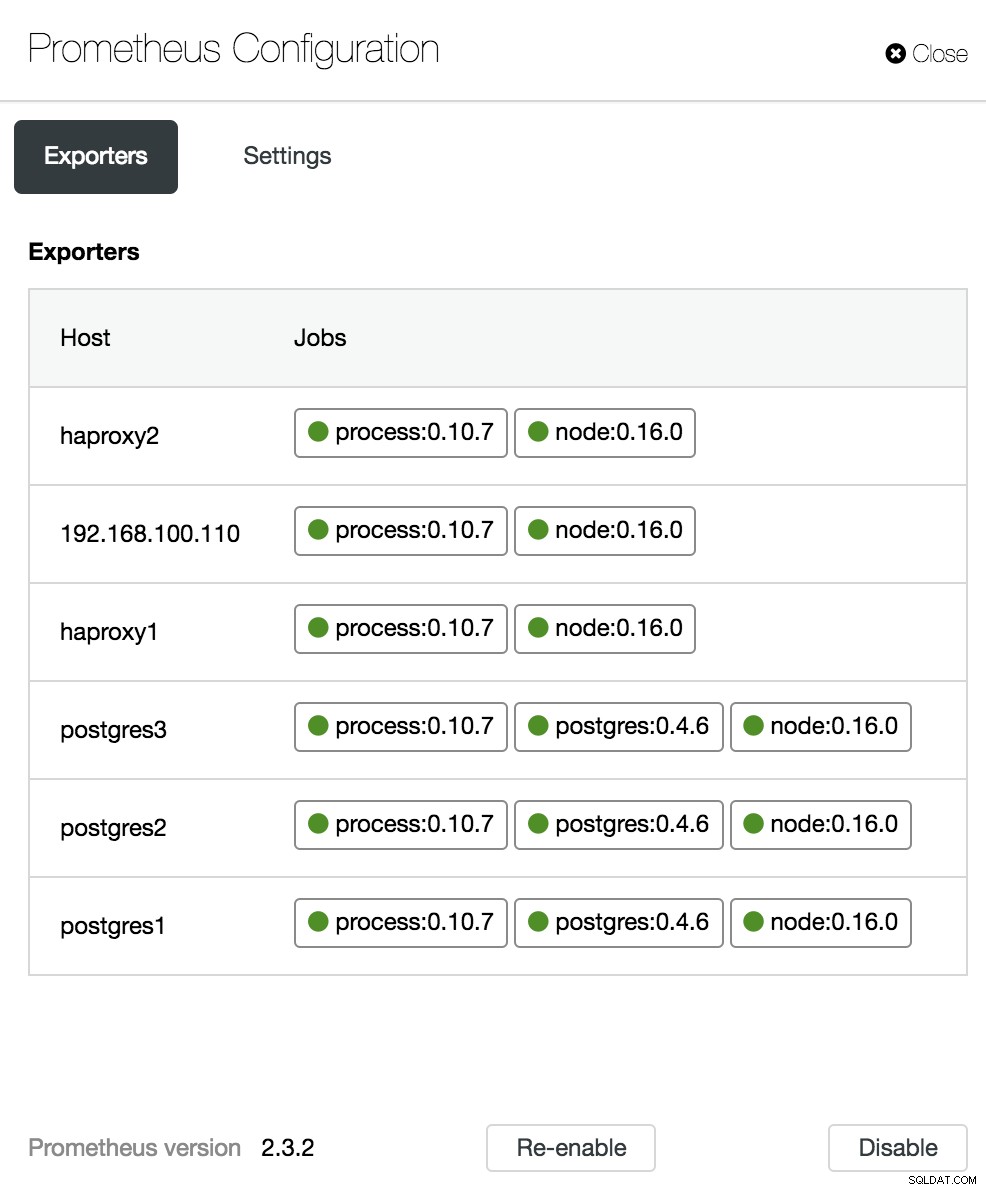 Configuration du tableau de bord ClusterControl
Configuration du tableau de bord ClusterControl Métriques de présentation de PostgreSQL
Voyons maintenant quelles métriques nous avons disponibles pour chacune de nos bases de données PostgreSQL (toutes pour le nœud sélectionné).
- SELECT (récupéré) :quantité de lignes sélectionnées (récupérées) pour chaque base de données. Les lignes extraites font référence aux lignes actives extraites de la table.
- SELECT (renvoyé) :nombre de lignes sélectionnées (renvoyées) pour chaque base de données. Les lignes renvoyées font référence à toutes les lignes lues à partir de la table, ce qui inclut les lignes mortes et les lignes pas encore validées (contrairement aux lignes extraites qui ne comptent que les tuples actifs).
- INSERT :nombre de lignes insérées pour chaque base de données.
- UPDATE :nombre de lignes mises à jour pour chaque base de données.
- DELETE :nombre de lignes supprimées pour chaque base de données.
- Sessions actives :nombre de sessions actives (min, max et moyenne) pour chaque base de données.
- Sessions inactives :nombre de sessions inactives (min, max et moyenne) pour chaque base de données.
- Tables de verrous :nombre de verrous (min, max et moyen) séparés par type pour chaque base de données.
- Utilisation des E/S du disque :utilisation des E/S du disque du serveur.
- Utilisation du disque :pourcentage d'utilisation du disque du serveur (min, max et moyenne).
- Latence du disque :latence du disque du serveur.
Métriques de présentation de ClusterControl PostgreSQL Métriques de présentation du système
Pour surveiller notre système, nous disposons pour chaque serveur des métriques suivantes (toutes pour le nœud sélectionné) :
- Temps de fonctionnement du système :temps écoulé depuis que le serveur est opérationnel.
- CPU :nombre de processeurs.
- RAM :quantité de mémoire RAM.
- Mémoire disponible :pourcentage de mémoire RAM disponible.
- Moyenne de charge :charge minimale, maximale et moyenne du serveur.
- Mémoire :mémoire serveur disponible, totale et utilisée.
- Utilisation du processeur :informations sur l'utilisation minimale, maximale et moyenne du processeur du serveur.
- Répartition de la mémoire :répartition de la mémoire (tampon, cache, libre et utilisée) sur le nœud sélectionné.
- Métriques de saturation :min, max et moyenne de la charge d'E/S et de la charge du processeur sur le nœud sélectionné.
- Détails avancés de la mémoire :détails de l'utilisation de la mémoire, tels que les pages, le tampon, etc., sur le nœud sélectionné.
- Forks :quantité de processus de forks. Fork est une opération par laquelle un processus crée une copie de lui-même. Il s'agit généralement d'un appel système, implémenté dans le noyau.
- Processus :nombre de processus en cours d'exécution ou en attente sur le système d'exploitation.
- Changements de contexte :un changement de contexte est l'action de stocker l'état d'un processus ou d'un thread.
- Interruptions :quantité d'interruptions. Une interruption est un événement qui altère le flux d'exécution normal d'un programme et peut être généré par des périphériques matériels ou même par le CPU lui-même.
- Trafic réseau :trafic réseau entrant et sortant en Ko par seconde sur le nœud sélectionné.
- Utilisation du réseau par heure :trafic envoyé et reçu au cours du dernier jour.
- Échange :échangez l'utilisation (libre et utilisée) sur le nœud sélectionné.
- Activité d'échange :lit et écrit des données sur l'échange.
- Activité d'E/S :entrée et sortie de page sur IO.
- Descripteurs de fichiers :attribuez et limitez les descripteurs de fichiers.
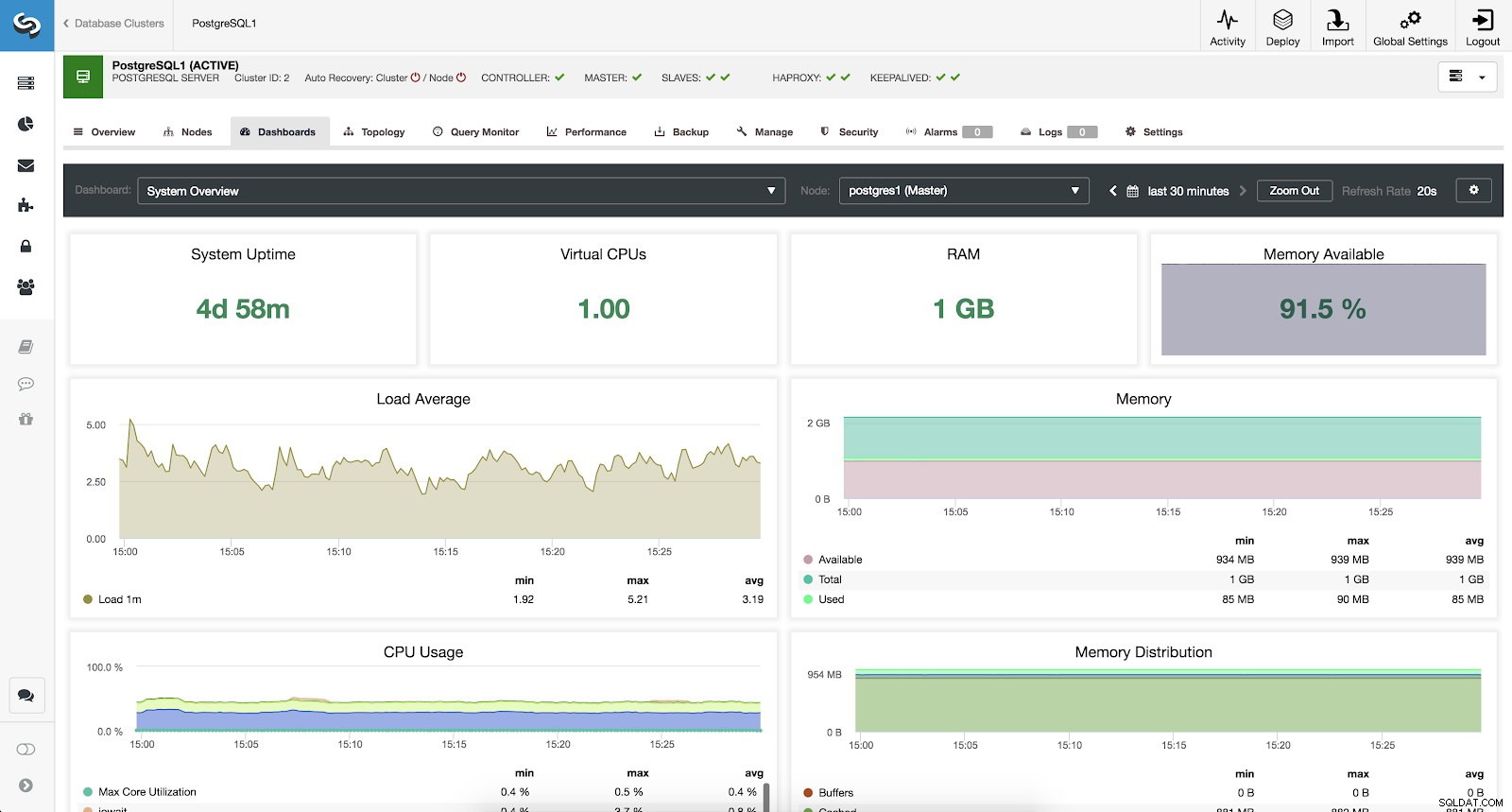 Métriques de présentation du système ClusterControl
Métriques de présentation du système ClusterControl Métriques des graphiques inter-serveurs
Si nous voulons voir l'état général de tous nos serveurs, nous pouvons utiliser ce tableau de bord avec les métriques suivantes :
- Moyenne de charge :charge moyenne des serveurs pour chaque serveur.
- Utilisation de la mémoire :pourcentage d'utilisation de la mémoire pour chaque serveur.
- Trafic réseau :nombre minimal, maximal et moyen de Ko de trafic réseau par seconde.
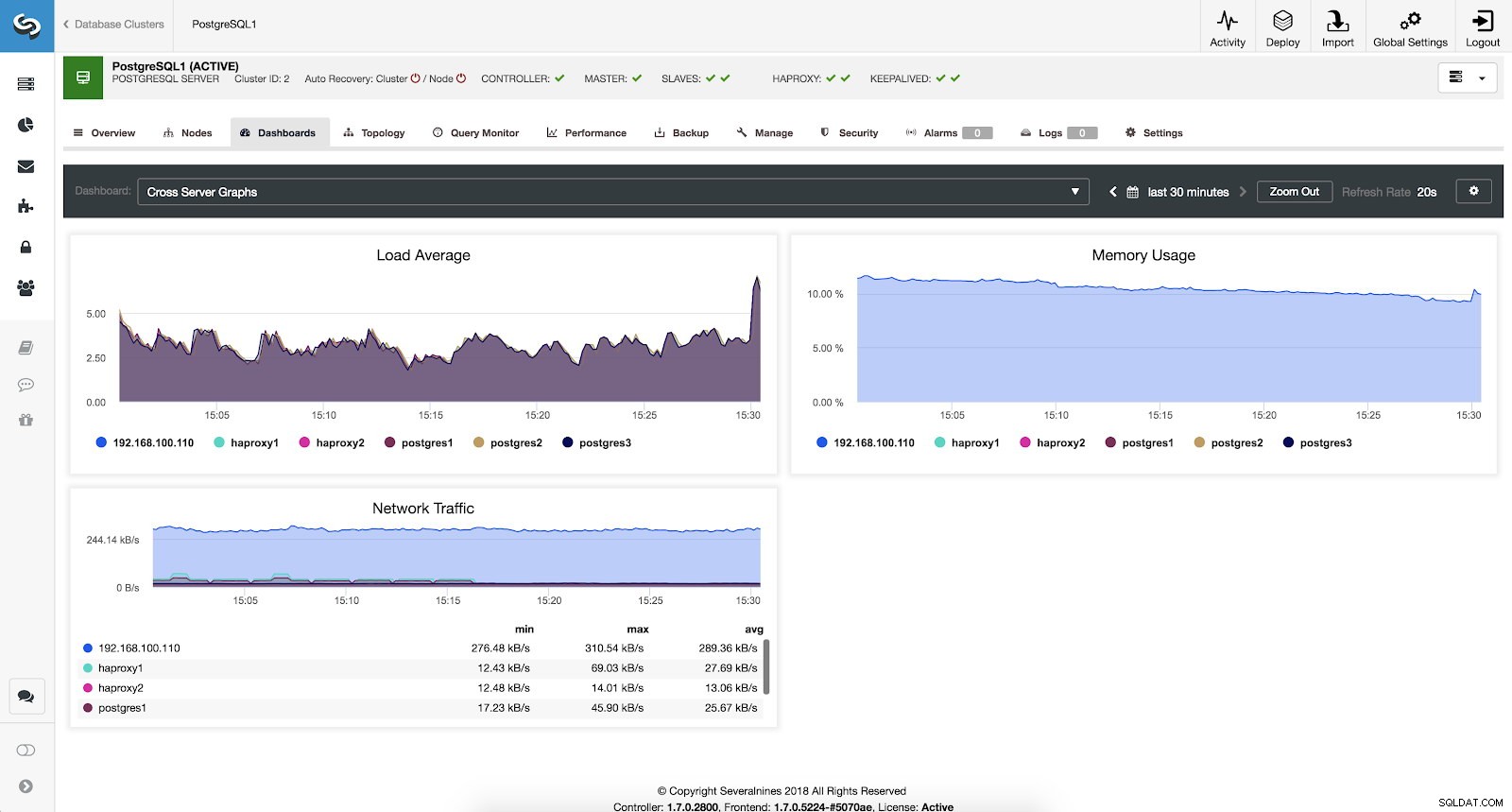 ClusterControl Cross Server Graphs Metrics
ClusterControl Cross Server Graphs Metrics Conclusion
Il existe plusieurs façons de surveiller PostgreSQL. ClusterControl fournit à la fois une surveillance sans agent et désormais basée sur un agent via Prometheus. Il fournit des données de surveillance à plus haute résolution, ainsi que différents tableaux de bord pour comprendre les performances de la base de données. ClusterControl peut également s'intégrer à des outils externes tels que Slack ou PagerDuty pour les alertes.