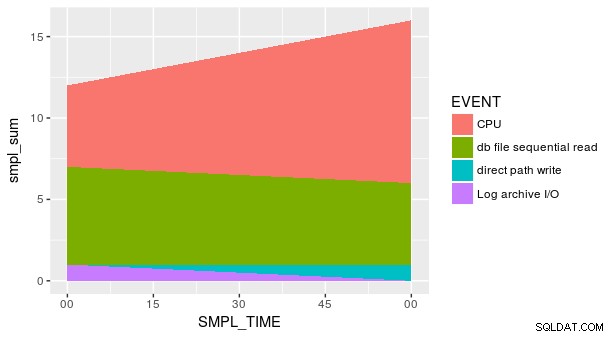
Je vais commencer par la deuxième question, qui est plus facile. Utiliser le dplyr package, vous pouvez utiliser top_n pour obtenir les n plus grandes lignes d'une colonne donnée. Par exemple :
> top_n(p_ash_r_100a, 3, SMPL_CNT) %>% arrange(desc(SMPL_CNT))
# A tibble: 3 × 5
SMPL_TIME SQL_ID MODULE EVENT SMPL_CNT
<dttm> <chr> <chr> <chr> <int>
1 2017-04-11 09:01:00 NO_SQL GoldenGate CPU 7
2 2017-04-11 09:00:00 dgzp3at57cagd GoldenGate db file sequential read 2
3 2017-04-11 09:01:00 37cspa0acgqxp GoldenGate db file sequential read 2
Notez que vous obtiendrez plus de n rangées s'il y a des égalités pour la nième place. Ainsi top_n(p_ash_r_100, 10, SMPL_CNT) renverra l'intégralité de l'ensemble de données d'échantillon en raison de l'égalité à 17 voies pour le 4ème.
Comme pour la première question, la documentation de geom_area donne un indice :
Cela suggère que geom_area s'attend à ce que la colonne mappée à x soit numérique. Basé sur la liste pour p_ash_r_100 , SMPL_TIME semble être un vecteur de caractères. Avec le lubridate package, nous pouvons convertir SMPL_TIME à une date-heure avec dmy_hm :
p_ash_r_100a <- p_ash_r_100 %>%
mutate_at(vars(SMPL_TIME), dmy_hm)
Cependant, cela ne suffit pas pour obtenir le tracé souhaité car il existe plusieurs valeurs de y pour chaque combinaison de x et fill (qui est l'esthétique correcte pour geom_area , et non "col "). Nous devons résumer les données avant de tracer :
p_ash_r_100a %>%
group_by(SMPL_TIME, EVENT) %>%
summarise(total = sum(SMPL_CNT)) %>%
ggplot(aes(SMPL_TIME, total, fill = EVENT)) +
geom_area()
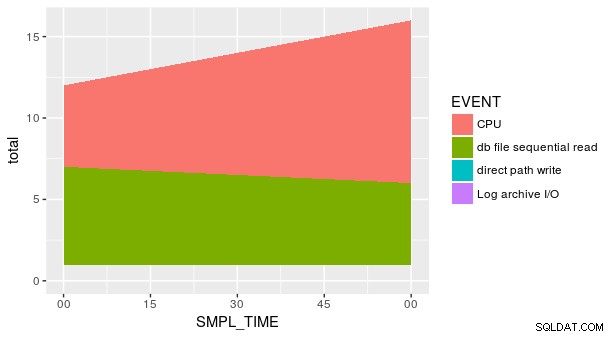
Pourtant, l'intrigue n'est toujours pas correcte. En effet, chaque combinaison de SMPL_TIME et EVENT n'est pas représenté dans le jeu de données. Nous devons indiquer explicitement geom_area que y est égal à zéro pour les lignes manquantes. Une façon consiste à utiliser le pratique fill argument dans tidyr::spread .
group_by(p_ash_r_100a, SMPL_TIME, EVENT) %>%
summarise(smpl_sum = sum(SMPL_CNT)) %>%
spread(EVENT, smpl_sum, fill = 0) %>%
gather(EVENT, smpl_sum, CPU, `db file sequential read`,
`direct path write`,
`Log archive I/O`) %>%
ggplot(aes(x = SMPL_TIME, y = smpl_sum, fill = EVENT)) +
geom_area()