C'est un problème assez courant.
B-Tree ordinaire les index ne sont pas bons pour les requêtes comme ceci :
SELECT measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
Un index est bon pour rechercher les valeurs dans les limites données, comme ceci :
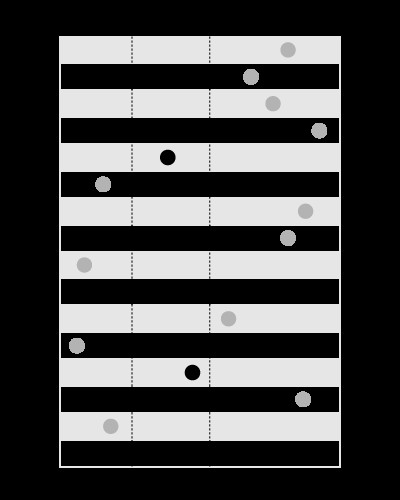
, mais pas pour rechercher les limites contenant la valeur donnée, comme ceci :
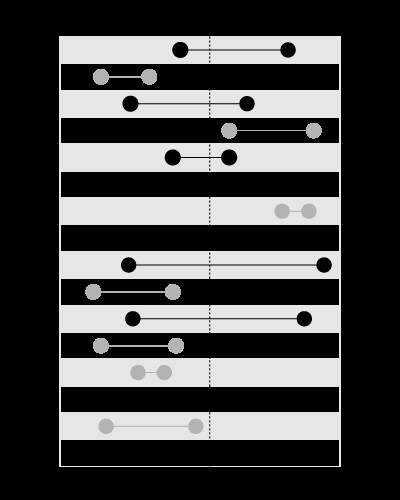
Cet article de mon blog explique le problème plus en détail :
(le modèle d'ensembles imbriqués traite le même type de prédicat).
Vous pouvez faire l'index sur time , ainsi les intervals sera en tête dans la jointure, le temps échelonné sera utilisé à l'intérieur des boucles imbriquées. Cela nécessitera un tri sur time .
Vous pouvez créer un index spatial sur intervals (disponible en MySQL en utilisant MyISAM stockage) qui inclurait start et end dans une colonne géométrique. De cette façon, measures peut mener dans la jointure et aucun tri ne sera nécessaire.
Les index spatiaux, cependant, sont plus lents, donc cela ne sera efficace que si vous avez peu de mesures mais beaucoup d'intervalles.
Puisque vous avez peu d'intervalles mais beaucoup de mesures, assurez-vous simplement d'avoir un index sur measures.time :
CREATE INDEX ix_measures_time ON measures (time)
Mise à jour :
Voici un exemple de script à tester :
BEGIN
DBMS_RANDOM.seed(20091223);
END;
/
CREATE TABLE intervals (
entry_time NOT NULL,
exit_time NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level,
TO_DATE('23.12.2009', 'dd.mm.yyyy') - level + DBMS_RANDOM.value
FROM dual
CONNECT BY
level <= 1500
/
CREATE UNIQUE INDEX ux_intervals_entry ON intervals (entry_time)
/
CREATE TABLE measures (
time NOT NULL,
measure NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level / 720,
CAST(DBMS_RANDOM.value * 10000 AS NUMBER(18, 2))
FROM dual
CONNECT BY
level <= 1080000
/
ALTER TABLE measures ADD CONSTRAINT pk_measures_time PRIMARY KEY (time)
/
CREATE INDEX ix_measures_time_measure ON measures (time, measure)
/
Cette requête :
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_NL(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
utilise des NESTED LOOPS et revient en 1.7 secondes.
Cette requête :
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_MERGE(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
utilise MERGE JOIN et j'ai dû l'arrêter après 5 minute.
Mise à jour 2 :
Vous devrez très probablement forcer le moteur à utiliser le bon ordre de table dans la jointure en utilisant un indice comme celui-ci :
SELECT /*+ LEADING (intervals) USE_NL(intervals, measures) */
measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
L'Oracle L'optimiseur de n'est pas assez intelligent pour voir que les intervalles ne se croisent pas. C'est pourquoi il utilisera très probablement des measures comme tableau principal (ce qui serait une sage décision si les intervalles se croisent).
Mise à jour 3 :
WITH splits AS
(
SELECT /*+ MATERIALIZE */
entry_range, exit_range,
exit_range - entry_range + 1 AS range_span,
entry_time, exit_time
FROM (
SELECT TRUNC((entry_time - TO_DATE(1, 'J')) * 2) AS entry_range,
TRUNC((exit_time - TO_DATE(1, 'J')) * 2) AS exit_range,
entry_time,
exit_time
FROM intervals
)
),
upper AS
(
SELECT /*+ MATERIALIZE */
MAX(range_span) AS max_range
FROM splits
),
ranges AS
(
SELECT /*+ MATERIALIZE */
level AS chunk
FROM upper
CONNECT BY
level <= max_range
),
tiles AS
(
SELECT /*+ MATERIALIZE USE_MERGE (r s) */
entry_range + chunk - 1 AS tile,
entry_time,
exit_time
FROM ranges r
JOIN splits s
ON chunk <= range_span
)
SELECT /*+ LEADING(t) USE_HASH(m t) */
SUM(LENGTH(stuffing))
FROM tiles t
JOIN measures m
ON TRUNC((m.time - TO_DATE(1, 'J')) * 2) = tile
AND m.time BETWEEN t.entry_time AND t.exit_time
Cette requête divise l'axe du temps en plages et utilise un HASH JOIN pour joindre les mesures et les horodatages sur les valeurs de plage, avec un filtrage fin plus tard.
Voir cet article sur mon blog pour des explications plus détaillées sur son fonctionnement :



