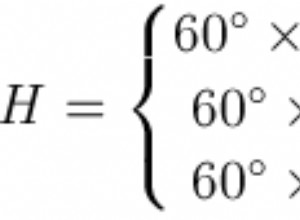Pour commencer, certaines fonctionnalités standard d'Oracle utilisent des types, par exemple XMLDB et Spatial (qui inclut la déclaration de colonnes de types de données Nested Table).
De plus, de nombreux développeurs PL/SQL utilisent des types tout le temps, pour déclarer des collections PL/SQL ou des fonctions en pipeline.
Mais je suis d'accord que peu d'endroits utilisent intensivement les types et en construisent des API PL/SQL. Il y a plusieurs raisons à cela.
- Oracle a implémenté les objets très lentement. Bien qu'ils aient été introduits dans la version 8.0, ce n'est qu'à partir de la version 9.2 qu'ils ont entièrement pris en charge l'héritage, le polymorphisme et les constructeurs définis par l'utilisateur. Une bonne programmation orientée objet est impossible sans ces fonctionnalités. Nous n'avons pas obtenu
SUPER()jusqu'à la version 11g. Même maintenant, il manque des fonctionnalités, notamment les déclarations privées dans le TYPE BODY. - La syntaxe est souvent maladroite ou désespérément obscure. La documentation n'aide pas.
- La plupart des personnes travaillant avec Oracle sont issues de l'école de programmation relationnelle/procédurale. Cela signifie qu'ils ont tendance à ne pas comprendre la POO ou qu'ils ne comprennent pas où cela peut être utile dans la programmation de bases de données. Même lorsque les gens ont une bonne idée, ils trouvent qu'il est difficile, voire impossible, de la mettre en œuvre en utilisant la syntaxe d'Oracle.
Ce dernier point est le plus important. Nous pouvons apprendre une nouvelle syntaxe, nous pouvons persuader Oracle de compléter l'ensemble de fonctionnalités, mais cela ne vaut la peine que si nous pouvons trouver une utilisation pour les types. Cela signifie que nous avons besoin de problèmes qui peuvent être résolus en utilisant l'héritage et le polymorphisme.
J'ai travaillé sur un système qui utilisait beaucoup les types. Il s'agissait d'un système d'entrepôt de données et le sous-système de chargement des données était construit à partir de types. La logique sous-jacente était simple :
- nous devons appliquer le même modèle de règle métier pour chaque table que nous chargeons, le processus est donc générique ;
- chaque table a sa propre projection, donc les instructions SQL sont uniques pour chacune.
L'implémentation de Type est propre :le processus générique est défini dans un Type; l'implémentation de chaque table est définie dans un Type qui hérite de ce Type générique. Les types spécifiques peuvent être générés à partir des métadonnées. J'ai présenté ce sujet à l'UKOUG il y a quelques années, et je l'ai écrit plus en détail sur mon blog.En savoir plus.
Soit dit en passant, la théorie relationnelle inclut le concept de domaines, qui sont des types de données définis par l'utilisateur, y compris des contraintes, etc.