PostgreSQL est un projet génial et il évolue à une vitesse incroyable. Nous nous concentrerons sur l'évolution des capacités de tolérance aux pannes dans PostgreSQL à travers ses versions avec une série d'articles de blog. Ceci est le quatrième article de la série et nous parlerons de la validation synchrone et de ses effets sur la tolérance aux pannes et la fiabilité de PostgreSQL.
Si vous souhaitez assister à la progression de l'évolution depuis le début, veuillez consulter les trois premiers articles de blog de la série ci-dessous. Chaque article est indépendant, vous n'avez donc pas besoin d'en lire un pour en comprendre un autre.
- Évolution de la tolérance aux pannes dans PostgreSQL
- Évolution de la tolérance aux pannes dans PostgreSQL :phase de réplication
- Évolution de la tolérance aux pannes dans PostgreSQL :voyage dans le temps
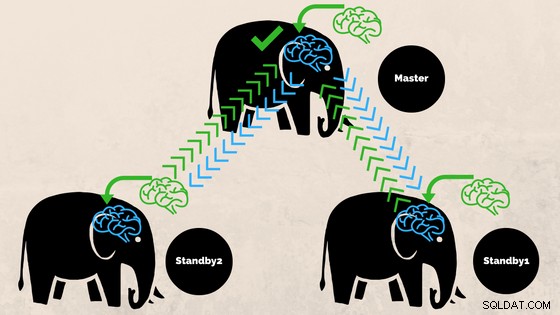
Engagement synchrone
Par défaut, PostgreSQL implémente la réplication asynchrone, où les données sont diffusées chaque fois que cela convient au serveur. Cela peut signifier une perte de données en cas de basculement. Il est possible de demander à Postgres d'exiger qu'un (ou plusieurs) standbys accuse réception de la réplication des données avant le commit, c'est ce qu'on appelle la réplication synchrone (commit synchrone ) .
Avec la réplication synchrone, la réplication retarde directement affecte le temps écoulé des transactions sur le maître. Avec la réplication asynchrone, le maître peut continuer à pleine vitesse.
La réplication synchrone garantit que les données sont écrites dans au moins deux nœuds avant que l'utilisateur ou l'application ne soit informé qu'une transaction a été validée.
L'utilisateur peut sélectionner le mode de validation de chaque transaction , de sorte qu'il est possible d'exécuter simultanément des transactions de validation synchrones et asynchrones.
Cela permet des compromis flexibles entre les performances et la certitude de la durabilité des transactions.
Configuration de la validation synchrone
Pour configurer la réplication synchrone dans Postgres, nous devons configurer synchronous_commit paramètre dans postgresql.conf.
Le paramètre spécifie si la validation de la transaction attendra que les enregistrements WAL soient écrits sur le disque avant que la commande ne renvoie un succès indications au client. Les valeurs valides sont on , remote_apply , remote_write , local , et désactivé . Nous verrons comment les choses fonctionnent en termes de réplication synchrone lorsque nous configurons synchronous_commit paramètre avec chacune des valeurs définies.
Commençons par la documentation Postgres (9.6) :
Ici, nous comprenons le concept de validation synchrone, comme nous l'avons décrit dans la partie introduction de l'article, vous êtes libre de configurer la réplication synchrone mais si vous ne le faites pas, il y a toujours un risque de perdre des données. Mais sans risque de créer une incohérence dans la base de données, contrairement à la désactivation de fsync off – mais c'est un sujet pour un autre post -. Enfin, nous concluons que si nous ne voulons pas perdre de données entre les délais de réplication et que nous voulons être sûrs que les données sont écrites sur au moins deux nœuds avant que l'utilisateur/l'application ne soit informée que la transaction a été validée , nous devons accepter de perdre des performances.
Voyons comment différents paramètres fonctionnent pour différents niveaux de synchronisation. Avant de commencer, parlons de la façon dont la validation est traitée par la réplication PostgreSQL. Le client exécute des requêtes sur le nœud maître, les modifications sont écrites dans un journal des transactions (WAL) et copiées sur le réseau vers le WAL sur le nœud de secours. Le processus de récupération sur le nœud de secours lit ensuite les modifications de WAL et les applique aux fichiers de données comme lors de la récupération après un crash. Si le standby est en hot standby mode, les clients peuvent émettre des requêtes en lecture seule sur le nœud pendant que cela se produit. Pour plus de détails sur le fonctionnement de la réplication, vous pouvez consulter le billet de blog sur la réplication de cette série.
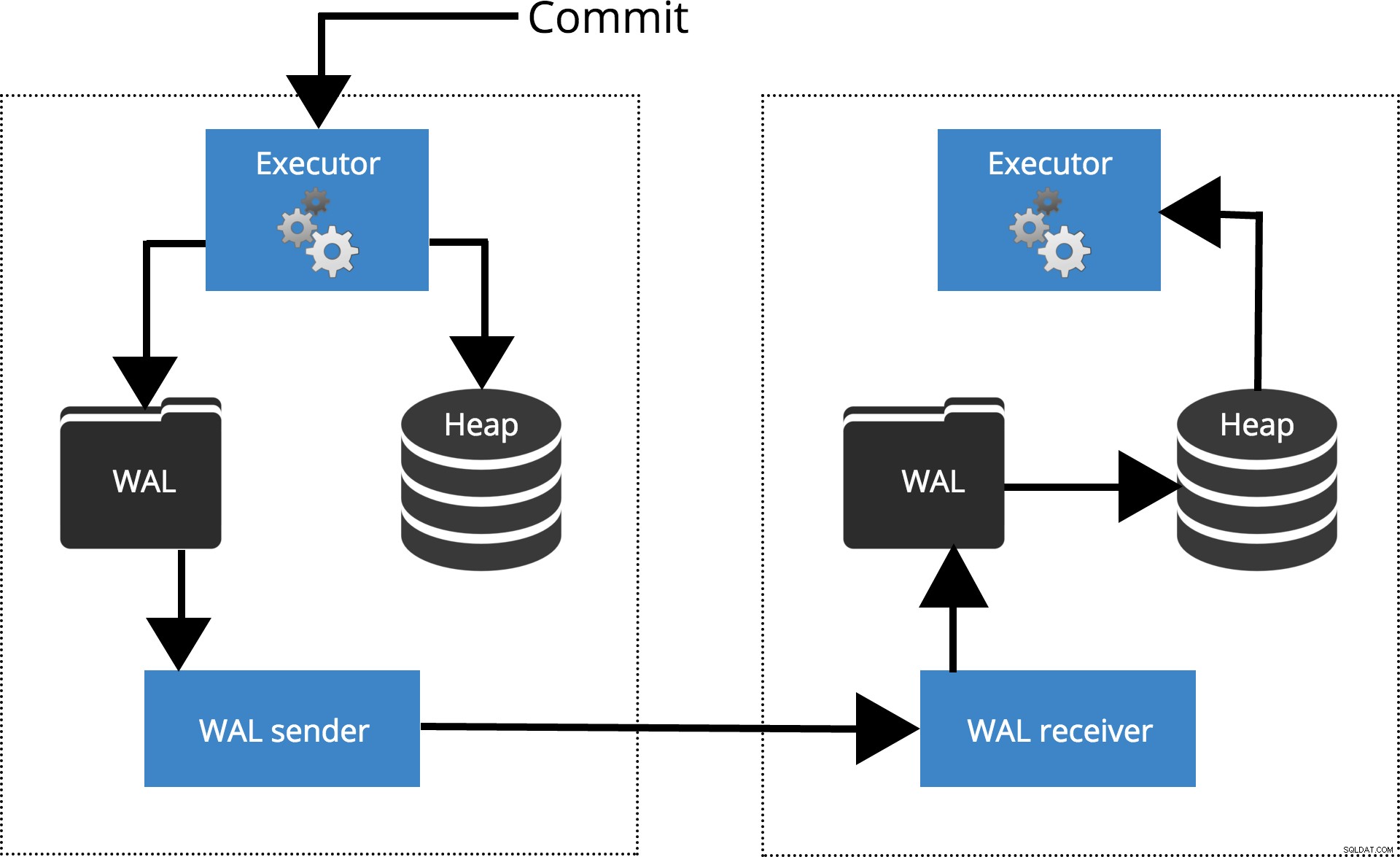
Fig.1 Comment fonctionne la réplication
synchronous_commit =désactivé
Lorsque nous définissons sychronous_commit = off, le COMMIT n'attend pas que l'enregistrement de la transaction soit vidé sur le disque. Ceci est mis en évidence dans la Fig.2 ci-dessous.
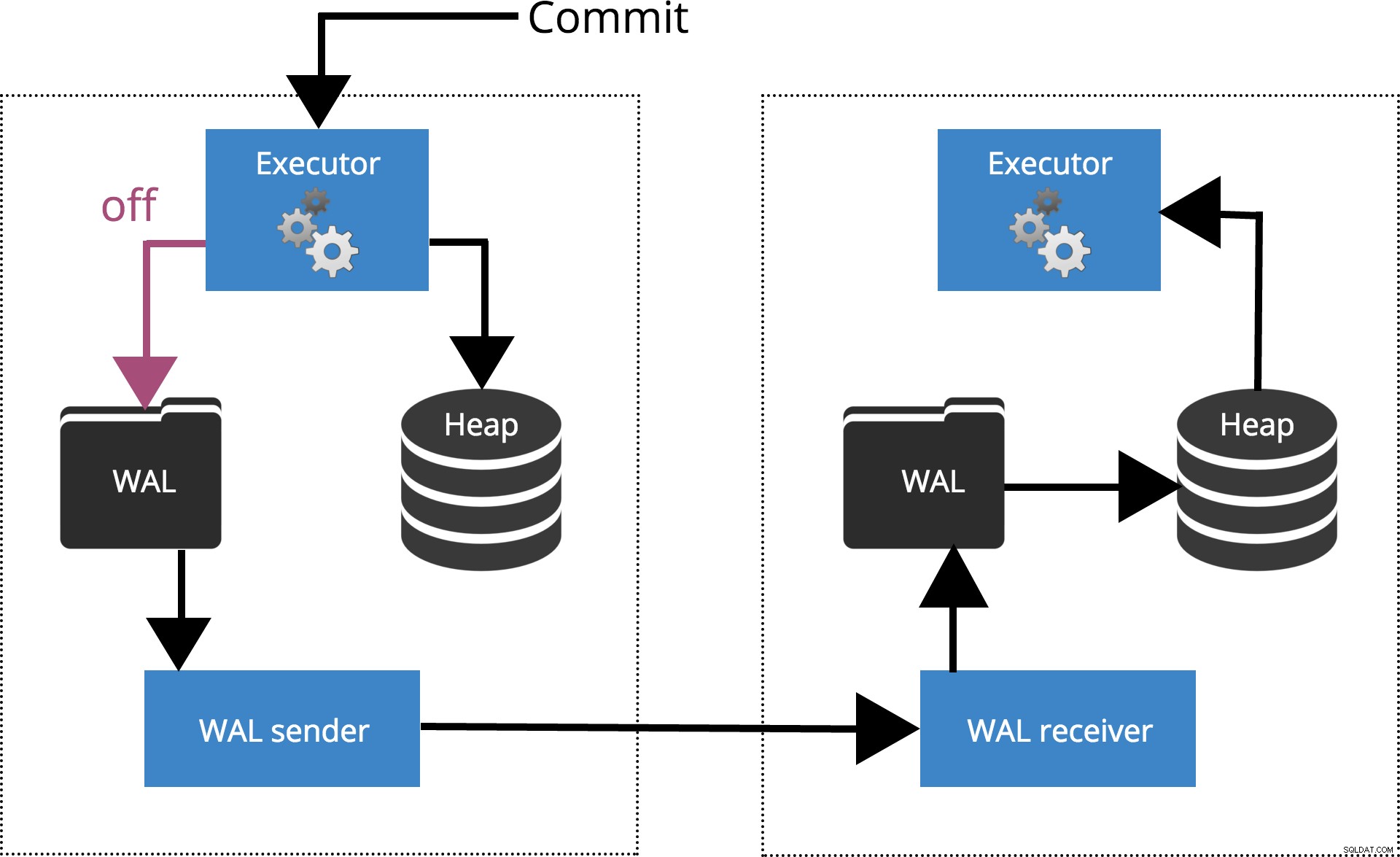
Fig.2 synchronous_commit =off
synchronous_commit =local
Lorsque nous définissons synchronous_commit = local, le COMMIT attend que l'enregistrement de la transaction soit vidé sur le disque local. Ceci est mis en évidence dans la Fig.3 ci-dessous.
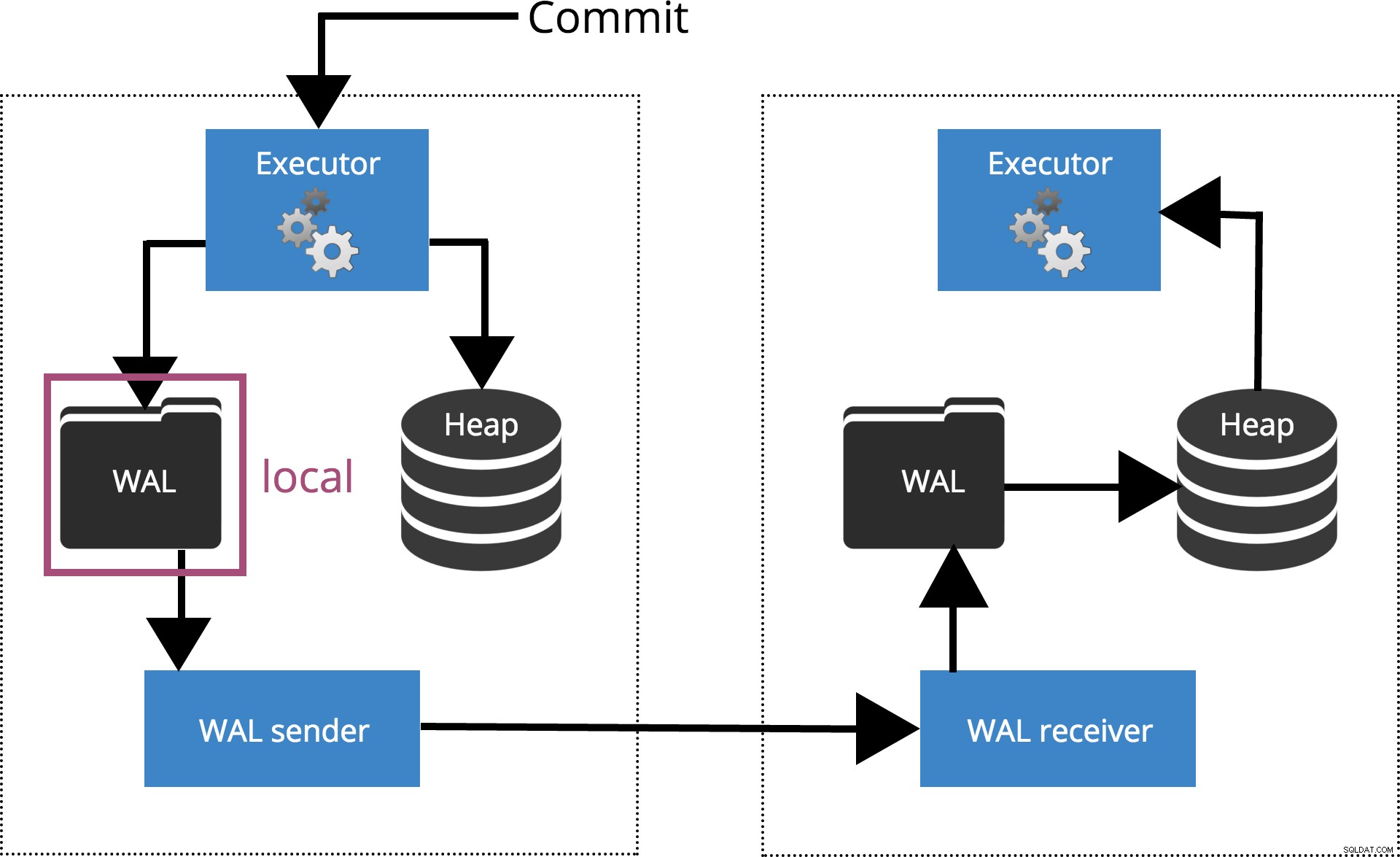
Fig.3 synchronous_commit =local
synchronous_commit =activé (par défaut)
Lorsque nous définissons synchronous_commit = on, le COMMIT attendra le(s) serveur(s) spécifié(s) par synchronous_standby_names confirmez que l'enregistrement de la transaction a été écrit en toute sécurité sur le disque. Ceci est mis en évidence dans la Fig.4 ci-dessous.
Remarque : Lorsque synchronous_standby_names est vide, ce paramètre se comporte comme synchronous_commit = local .
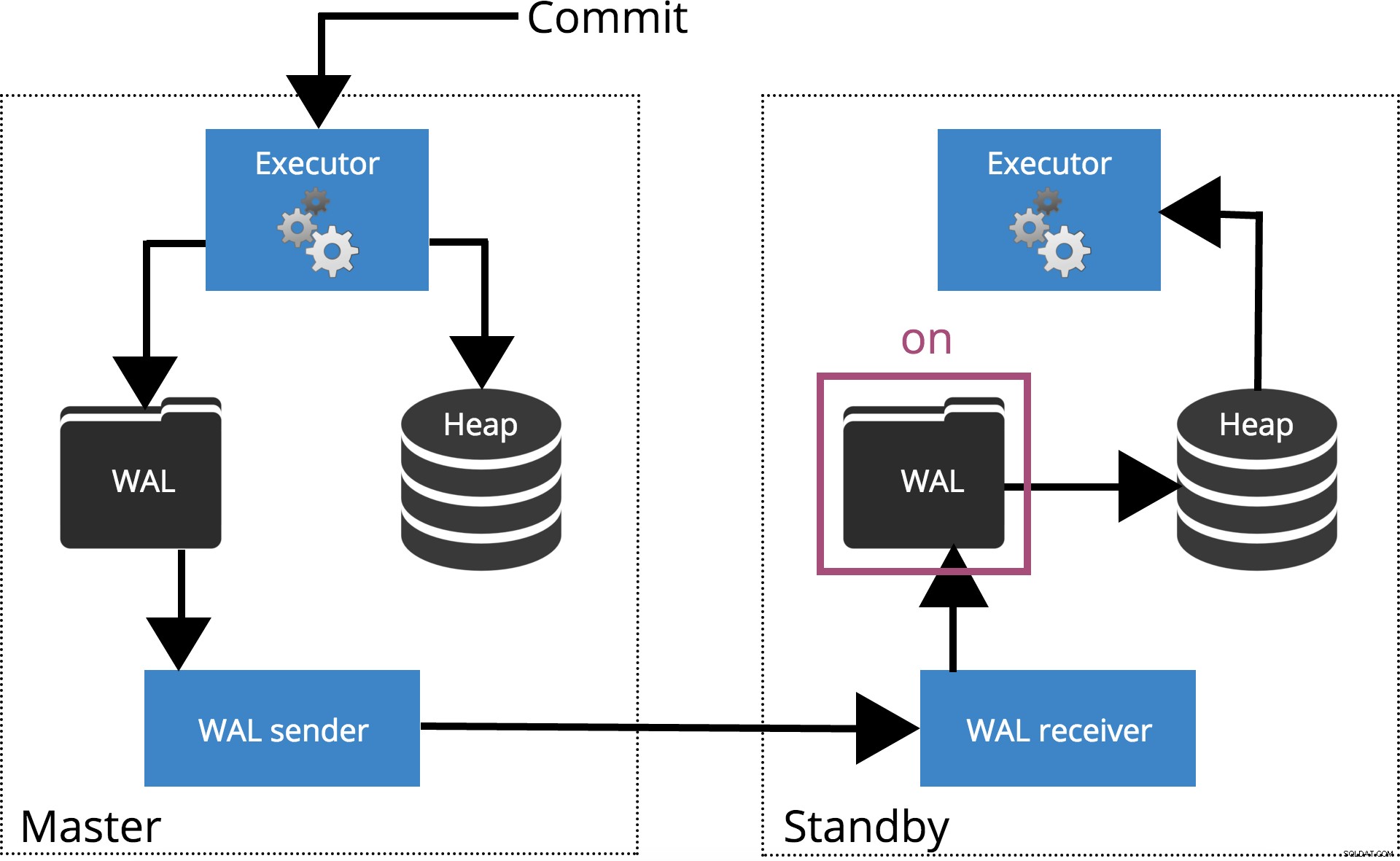
Fig.4 synchronous_commit =on
synchronous_commit =remote_write
Lorsque nous définissons synchronous_commit = remote_write, le COMMIT attendra le(s) serveur(s) spécifié(s) par synchronous_standby_names confirmer l'écriture de l'enregistrement de transaction dans le système d'exploitation mais n'a pas nécessairement atteint le disque. Ceci est mis en évidence dans la Fig.5 ci-dessous.
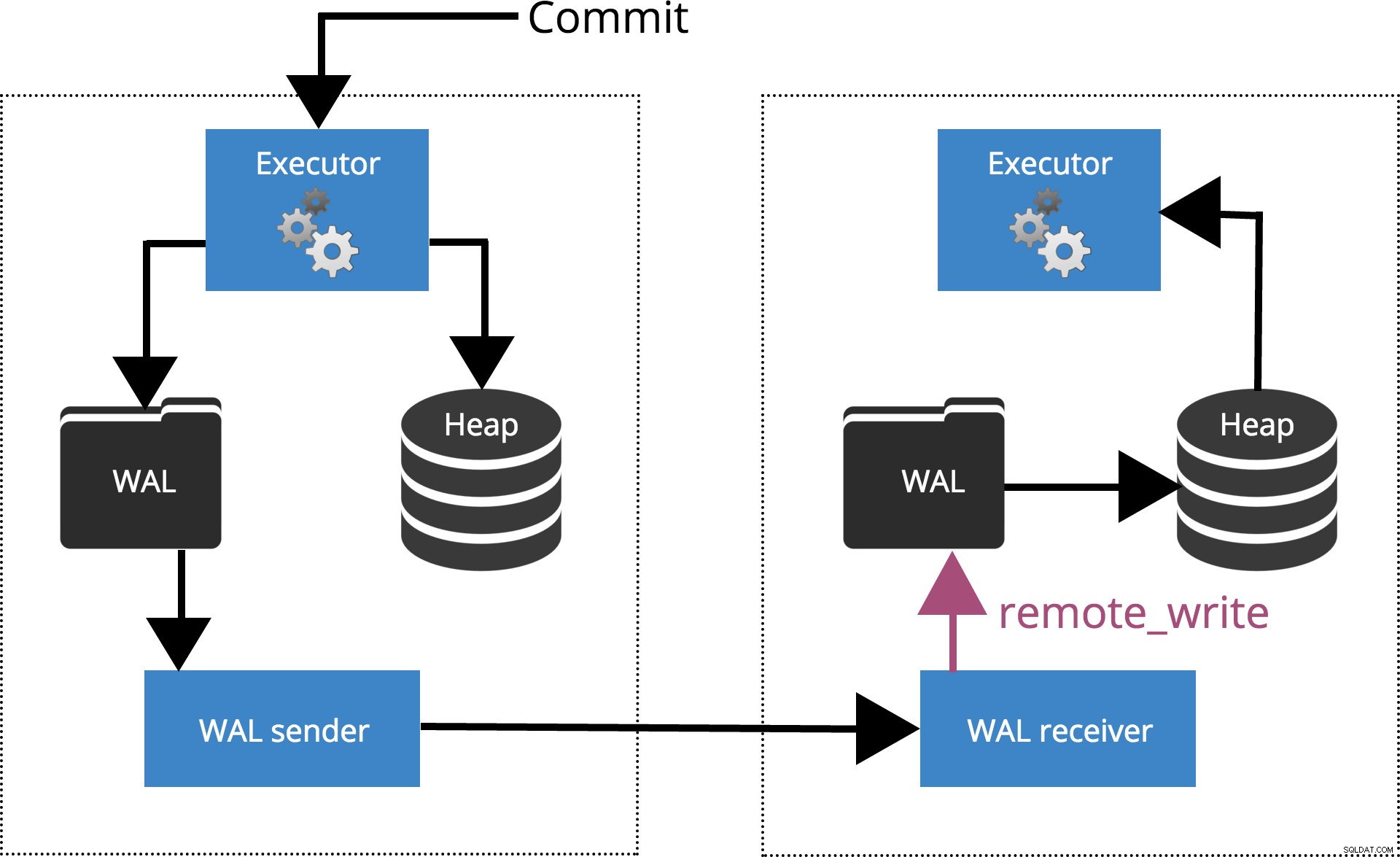
Fig.5 synchronous_commit =remote_write
synchronous_commit =remote_apply
Lorsque nous définissons synchronous_commit = remote_apply, le COMMIT attendra le(s) serveur(s) spécifié(s) par synchronous_standby_names confirmer que l'enregistrement de transaction a été appliqué à la base de données. Ceci est mis en évidence dans la Fig.6 ci-dessous.
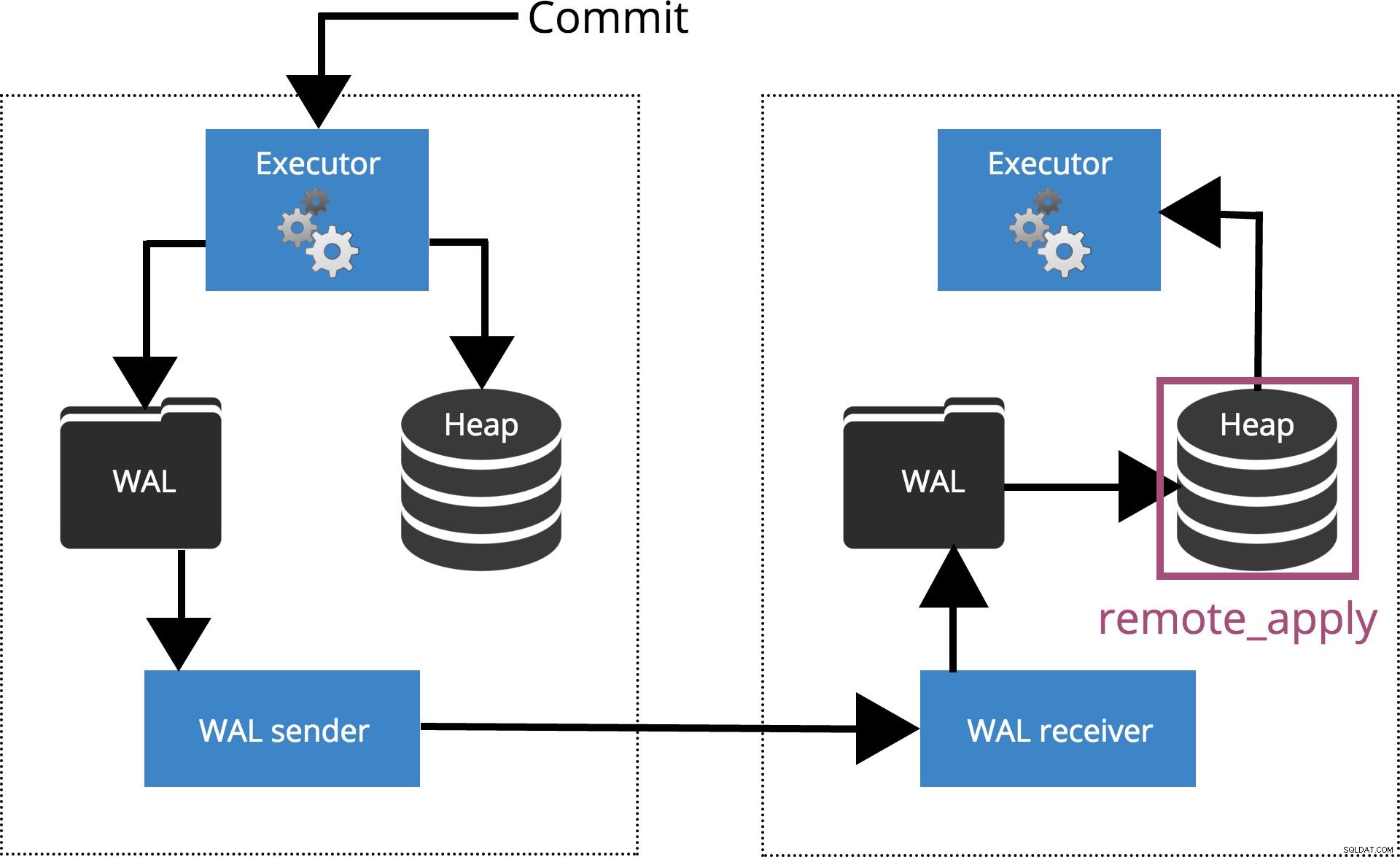
Fig.6 synchronous_commit =remote_apply
Maintenant, regardons sychronous_standby_names paramètre dans les détails, qui est mentionné ci-dessus lors de la définition de synchronous_commit comme on , remote_apply ou remote_write .
synchronous_standby_names ='standby_name [, …]'
Le commit synchrone attendra une réponse de l'un des standbys listés dans l'ordre de priorité. Cela signifie que si le premier standby est connecté et en streaming, le commit synchrone attendra toujours sa réponse même si le second standby a déjà répondu. La valeur spéciale de * peut être utilisé comme stanby_name qui correspondra à n'importe quelle veille connectée.
synchronous_standby_names ='num (standby_name [, …])'
Le commit synchrone attendra une réponse d'au moins num nombre de veilles répertoriées dans l'ordre de priorité. Les mêmes règles que ci-dessus s'appliquent. Ainsi, par exemple en définissant synchronous_standby_names = '2 (*)' fera en sorte que la validation synchrone attende la réponse de 2 serveurs de secours.
synchronous_standby_names est vide
Si ce paramètre est vide, comme indiqué, il modifie le comportement du paramètre synchronous_commit à on , remote_write ou remote_apply se comporter comme local (c'est-à-dire, le COMMIT n'attendra que le vidage sur le disque local).
Conclusion
Dans cet article de blog, nous avons discuté de la réplication synchrone et décrit les différents niveaux de protection disponibles dans Postgres. Nous continuerons avec la réplication logique dans le prochain article de blog.
Références
Un merci spécial à mon collègue Petr Jelinek pour m'avoir donné l'idée des illustrations.
Documentation PostgreSQL
Livre de recettes d'administration PostgreSQL 9 – Deuxième édition



