Nous étudions la migration d'une base de données Oracle d'une instance EC2 vers un service géré RDS. Dans le premier des quatre articles, « Migration d'une base de données Oracle d'AWS EC2 vers AWS RDS, partie 1 », nous avons créé des instances de base de données sur EC2 et RDS. Dans le deuxième article, « Migration d'une base de données Oracle d'AWS EC2 vers AWS RDS, partie 2 », nous avons créé un utilisateur IAM pour la migration de la base de données et également créé une table de base de données à migrer. Dans le deuxième article uniquement, nous avons créé une instance de réplication et des points de terminaison de réplication. Dans le troisième article, « Migration d'une base de données Oracle d'AWS EC2 vers AWS RDS, partie 3 », nous avons créé une tâche de migration pour migrer les modifications existantes. Dans cet article de suite, nous allons migrer les modifications en cours des données. Cet article comporte les sections suivantes :
- Création et exécution d'une tâche de réplication pour migrer les modifications en cours
- Ajout d'une journalisation supplémentaire
- Ajout d'une table à une instance de base de données Oracle sur EC2
- Ajout de données de table
- Exploration de la table de base de données répliquée
- Suppression et rechargement de données
- Arrêter et démarrer une tâche
- Suppression de bases de données
- Conclusion
Création et exécution d'une tâche de réplication pour migrer les modifications en cours
Dans les sous-sections suivantes, nous allons créer une tâche pour répliquer les modifications en cours. Pour démontrer la réplication continue, nous allons d'abord démarrer la tâche, puis créer une table et ajouter des données. Supprimez la table DVOHRA.WLSLOG , comme le montre la figure 1 ; nous allons créer la même table pour démontrer la réplication en cours.

Figure 1 : Table de suppression DVOHRA.WLSLOG
Ajout d'une journalisation supplémentaire
Service de migration de bases de données nécessite que la journalisation supplémentaire soit activée pour activer la capture des données modifiées (CDC) qui est utilisée pour répliquer les modifications en cours. La journalisation supplémentaire est le processus de stockage des informations sur les lignes de données d'une table qui ont été modifiées. La journalisation supplémentaire ajoute des données de colonne supplémentaires ou supplémentaires dans les fichiers de journalisation chaque fois qu'une mise à jour d'une table est effectuée. Les colonnes qui ont changé sont enregistrées en tant que données supplémentaires dans les fichiers de journalisation avec une clé d'identification, qui peut être la clé primaire ou l'index unique. Si une table n'a pas de clé primaire ou d'index unique, toutes les colonnes scalaires sont enregistrées dans les fichiers de journalisation pour identifier de manière unique une ligne de données, ce qui peut augmenter la taille des fichiers de journalisation. Oracle Database prend en charge les types de journalisation supplémentaire suivants :
- Journalisation supplémentaire minimale : Seule la quantité minimale de données requise par LogMiner pour les modifications DML est enregistrée dans les fichiers de journalisation.
- Enregistrement des clés d'identification au niveau de la base de données : Différents types de journalisation des clés d'identification au niveau de la base de données sont pris en charge :ALL, PRIMARY KEY, UNIQUE et FOREIGN KEY. Avec le niveau ALL, toutes les colonnes (à l'exception des LOB, des Longs et des ADT) sont enregistrées dans des fichiers de journalisation. Pour PRIMARY KEY, seules les colonnes de clé primaire sont stockées dans les fichiers de journalisation lorsqu'une ligne contenant une clé primaire est mise à jour; il n'est pas nécessaire qu'une colonne de clé primaire soit mise à jour. Le genre FOREIGN KEY stocke uniquement les clés étrangères d'une ligne dans les fichiers de journalisation lorsque l'un des fichiers journaux rouges est mis à jour. Le genre UNIQUE stocke uniquement les colonnes dans une clé composite unique ou un index bitmap lorsqu'une colonne de la clé composite unique ou de l'index bitmap a changé.
- Journalisation supplémentaire au niveau de la table : Spécifie au niveau de la table quelles colonnes sont stockées dans les fichiers de journalisation. La journalisation des clés d'identification au niveau de la table prend en charge les mêmes niveaux que la journalisation des clés d'identification au niveau de la base de données ; ALL, PRIMARY KEY, UNIQUE et FOREIGN KEY. Au niveau de la table, les groupes de journaux supplémentaires définis par l'utilisateur sont également pris en charge, ce qui permet à un utilisateur de définir les colonnes à enregistrer en plus. Les groupes de journaux supplémentaires définis par l'utilisateur peuvent être conditionnels ou inconditionnels.
Pour une réplication continue, nous devons définir une journalisation supplémentaire minimale et une journalisation supplémentaire au niveau de la table pour TOUTES les colonnes.
Dans SQL*Plus, exécutez l'instruction suivante pour définir une journalisation supplémentaire minimale :
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
Le résultat est le suivant :
SQL> ALTER DATABASE ADD SUPPLEMENTAL LOG DATA; Database altered.
Pour connaître l'état de la journalisation supplémentaire minimale, exécutez l'instruction suivante. Et, si la sortie a une valeur de colonne SUPPLEME comme OUI, la journalisation supplémentaire minimale est activée.
SQL> SELECT supplemental_log_data_min FROM v$database; SUPPLEME -------- YES
La configuration de la journalisation supplémentaire minimale et la vérification de la sortie d'état sont illustrées à la figure 2.
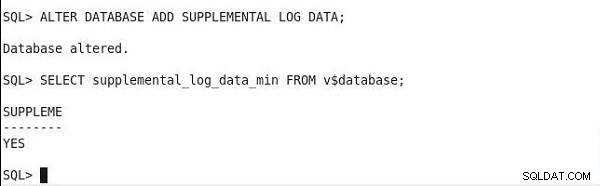
Figure 2 : Définition et vérification de la journalisation supplémentaire minimale
Nous définirons également la journalisation des clés d'identification au niveau de la table lorsque nous ajouterons des données de table et de table pour démontrer la réplication continue après le démarrage de la tâche. Si nous ajoutons une table et des données de table avant de créer et de démarrer une tâche, nous ne pourrons pas démontrer la réplication en cours.
Pour créer une tâche pour la réplication continue, cliquez sur Créer une tâche , comme illustré à la figure 3.

Figure 3 : Tâches>Créer une tâche
Dans Créer une tâche Assistant, spécifiez un nom de tâche et une description, puis sélectionnez l'instance de réplication, le point de terminaison source et le point de terminaison cible, comme illustré à la figure 4. Sélectionnez Type de migration comme Migrer les données existantes et répliquer les modifications en cours .
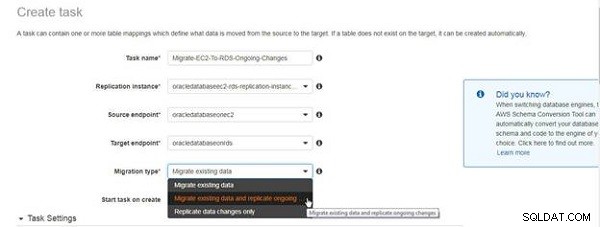
Figure 4 : Sélection du type de migration pour la réplication continue
Un message illustré à la figure 5 indique que la journalisation supplémentaire doit être activée pour la réplication en cours. Le message n'est pas destiné à indiquer que la journalisation supplémentaire n'a pas été activée, mais uniquement à titre de rappel. Nous avons déjà activé la journalisation supplémentaire. Cochez la case Commencer la tâche à la création .
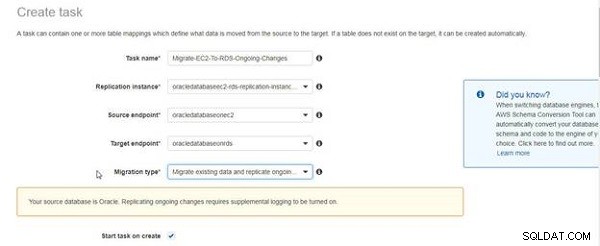
Figure 5 : Message concernant l'exigence de journalisation supplémentaire pour la réplication des modifications en cours
Les Paramètres de tâche sont les mêmes que pour la migration des données existantes uniquement (voir Figure 6).
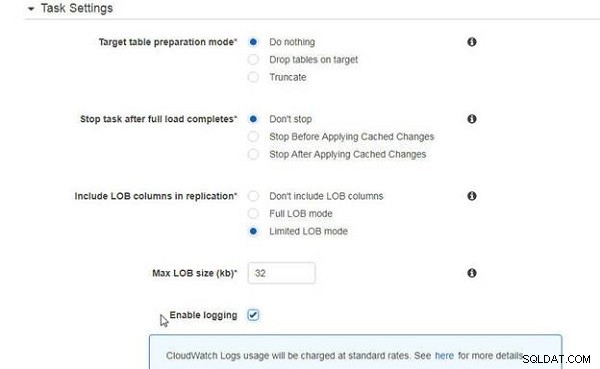
Figure 6 : Paramètres de tâche
Pour les mappages de table, au moins une règle de sélection est requise. Ajoutez une règle de sélection pour inclure toutes les tables dans le DVOHRA tableau, comme illustré à la figure 7.
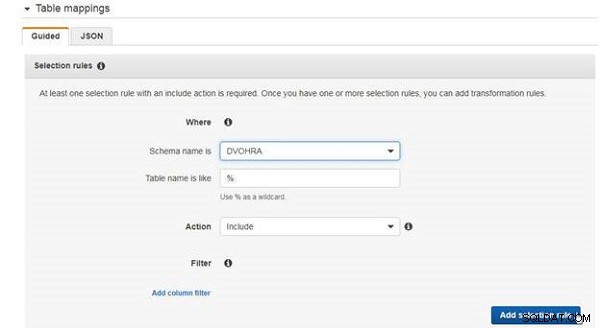
Figure 7 : Ajouter une règle de sélection
La règle de sélection ajoutée est illustrée à la figure 8.
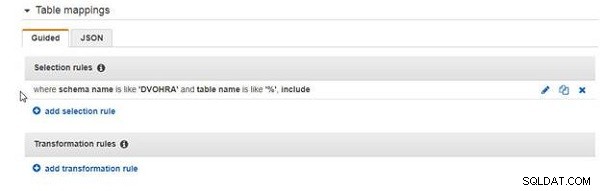
Figure 8 : Règle de sélection
Cliquez sur Créer une tâche pour créer la tâche, comme illustré à la figure 9.
Figure 9 : Créer une tâche
Une nouvelle tâche est ajoutée avec le statut Création , comme illustré à la Figure 10.

Figure 10 : Tâche ajoutée avec le statut Création
Lorsque les règles de sélection et de transformation de toutes les données existantes ont été appliquées et que les données ont été migrées, le statut de la tâche devient Chargement terminé, réplication en cours (voir Figure 11).

Figure 11 : Chargement terminé, réplication en cours
Les statistiques du tableau L'onglet ne répertorie aucune table comme ayant migré ou répliqué, comme illustré à la figure 12.
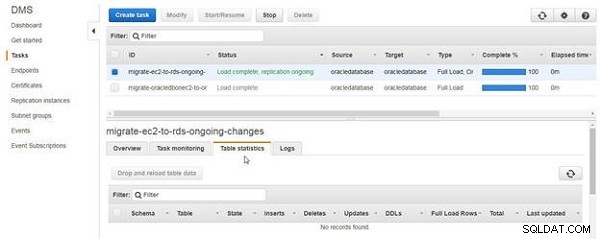
Figure 12 : Statistiques du tableau
Pour explorer les journaux CloudWatch, cliquez sur Journaux et cliquez sur le lien, comme illustré à la Figure 13.
Figure 13 : Journaux
Les journaux CloudWatch s'affichent, comme illustré à la figure 14. La dernière entrée des journaux concerne le démarrage de la réplication. La tâche en cours de réplication ne se termine pas après le chargement des données existantes, le cas échéant, mais continue de s'exécuter.
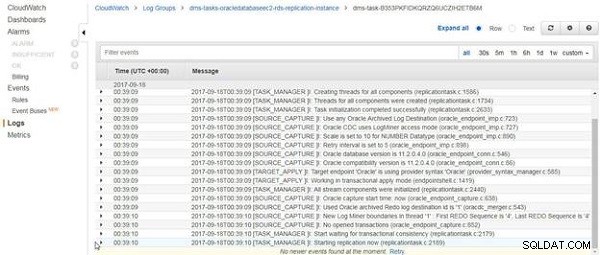
Figure 14 : Journaux CloudWatch
Ajout d'une table à une instance de base de données Oracle sur EC2
Ensuite, créez une table et ajoutez des données de table pour démontrer la réplication en cours. Exécutez les deux instructions suivantes ensemble afin que la journalisation supplémentaire au niveau de la table soit définie lors de la création de la table. Modifiez le script pour rendre le schéma différent.
CREATE TABLE DVOHRA.wlslog(time_stamp VARCHAR2(255) PRIMARY KEY, category VARCHAR2(255),type VARCHAR2(255),servername VARCHAR2(255),code VARCHAR2(255),msg VARCHAR2(255)); alter table DVOHRA.WLSLOG add supplemental log data (ALL) columns;
La journalisation supplémentaire au niveau de la table est définie lors de la création de la table.
SQL> CREATE TABLE DVOHRA.wlslog(time_stamp VARCHAR2(255) PRIMARY KEY,category VARCHAR2(255),type VARCHAR2(255),servername VARCHAR2(255),code VARCHAR2(255),msg VARCHAR2(255)); alter table DVOHRA.WLSLOG add supplemental log data (ALL) columns; Table created. SQL> Table altered.
La sortie est affichée dans SQL*Plus dans la figure 15.
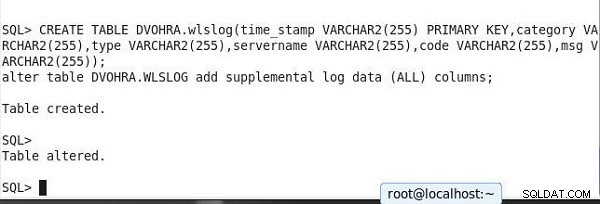
Figure 15 : Création d'un tableau et configuration de la journalisation supplémentaire
Pour l'instant, nous n'avons créé que la table, et nous n'avons ajouté aucune donnée de table. Le DDL de la table est migré, comme indiqué par les statistiques de la table dans la figure 16.
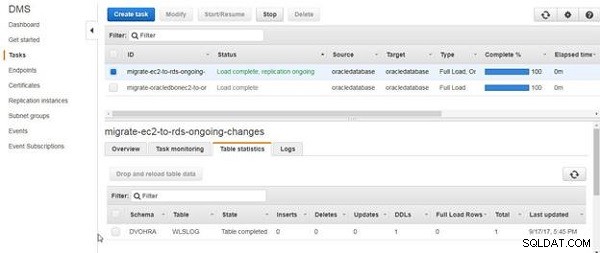
Figure 16 : DDL pour la table migrée
Ajout de données de tableau
Ensuite, exécutez le script SQL suivant pour ajouter des données à la table créée. Modifiez le script pour rendre le schéma différent.
SQL> INSERT INTO DVOHRA.wlslog(time_stamp,category,type,
servername,code,msg) VALUES('Apr-8-2014-7:06:16-PM-PDT',
'Notice','WebLogicServer','AdminServer','BEA-000365','Server
state changed to STANDBY');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,
code,msg) VALUES('Apr-8-2014-7:06:17-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to STARTING');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,
code,msg) VALUES('Apr-8-2014-7:06:18-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to ADMIN');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,code,
msg) VALUES('Apr-8-2014-7:06:19-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to RESUMING');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,code,
msg) VALUES('Apr-8-2014-7:06:20-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000361','Started WebLogic
AdminServer');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,code,
msg) VALUES('Apr-8-2014-7:06:21-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to RUNNING');
1 row created.
SQL>
1 row created.
SQL>
1 row created.
SQL>
1 row created.
SQL>
1 row created.
SQL>
1 row created.
Ensuite, exécutez l'instruction Commit.
SQL> COMMIT; Commit complete.
Exploration de la table de base de données répliquée
Les statistiques du tableau répertorient les insertions en tant que nombre de lignes de données ajoutées, comme illustré à la figure 17.
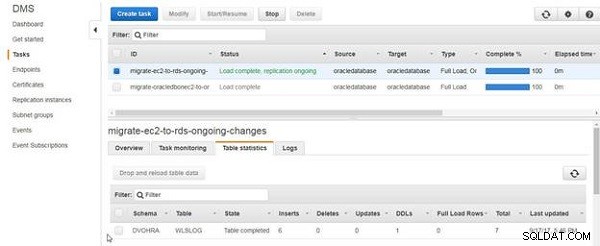
Figure 17 : Liste des statistiques du tableau 6 Inserts
La tâche continue de s'exécuter après la réplication des modifications en cours. Ajoutez une autre ligne de données.
SQL> INSERT INTO DVOHRA.wlslog(time_stamp,category,type,
servername,code,msg) VALUES('Apr-8-2014-7:06:22-PM-PDT',
'Notice','WebLogicServer','AdminServer','BEA-000360','Server
started in RUNNING mode');
1 row created.
SQL> COMMIT;
Commit complete.
SQL>
Cliquez sur Actualiser les données du serveur, comme illustré à la Figure 18.
Figure 18 : Actualiser les données du serveur
Le nombre total d'insertions dans les statistiques du tableau devient 7, comme illustré à la figure 19.
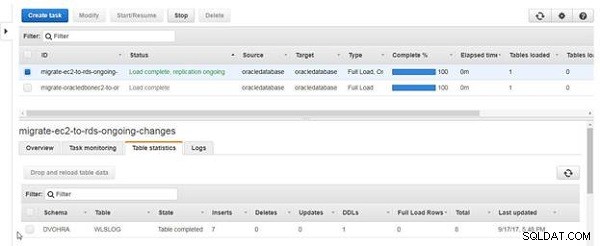
Figure 19 : Statistiques de table avec Inserts comme 7
Suppression et rechargement de données
Pour supprimer et recharger les données du tableau, cliquez sur Supprimer et recharger les données du tableau , comme illustré à la Figure 20.
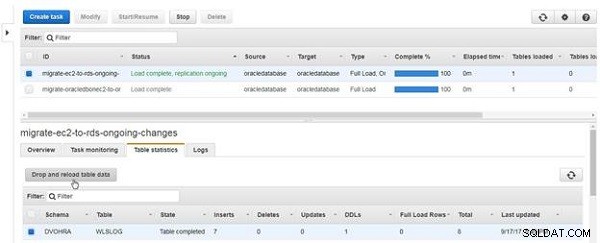
Figure 20 : Supprimer et recharger les données de table
Cliquez sur Actualiser les données du serveur (voir Figure 21).
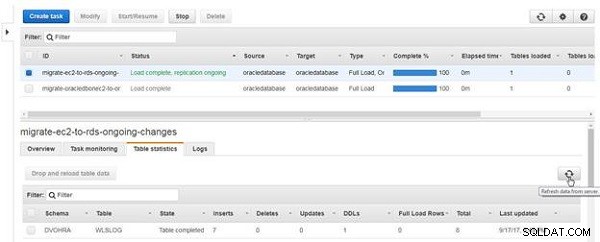
Figure 21 : Actualiser les données du serveur
L'icône et l'État colonne de la table indique que la table est en cours de rechargement, comme illustré à la Figure 22.
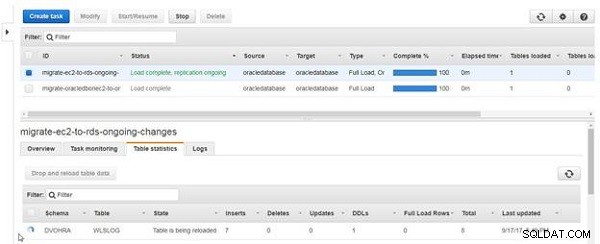
Figure 22 : Le tableau est en cours de rechargement
Lorsque le rechargement de la table est terminé, la colonne État de la table devient Table terminée , comme illustré à la Figure 23. Après le rechargement des données de la table, les Lignes de chargement complet affiche une valeur de 7 et Inserts est de 0 car un rechargement n'est pas une réplication en cours, mais un chargement complet.
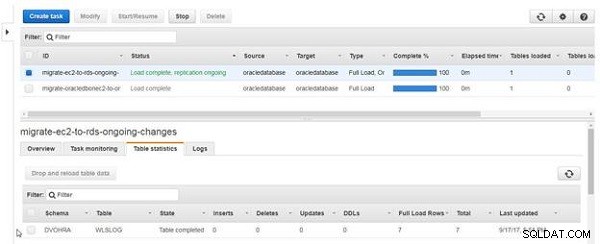
Figure 23 : Rechargement de la table terminé
Étant donné que les données de la table sont supprimées et rechargées et que les données de la table source n'ont pas changé, les journaux CloudWatch incluent un message "Certaines modifications de la base de données source n'ont eu aucun impact lorsqu'elles sont appliquées à la base de données cible.", comme illustré à la Figure 24.
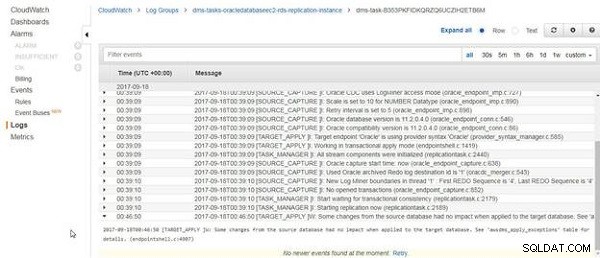
Figure 24 : Certaines modifications de la base de données source n'ont eu aucun impact lorsqu'elles ont été appliquées à la base de données cible
Lorsque le rechargement du DVOHRA.wlslog table est terminée, le message "Chargement terminé pour la table DVOHRA.wlslog. 7 lignes reçues" s'affiche, comme illustré à la Figure 25.
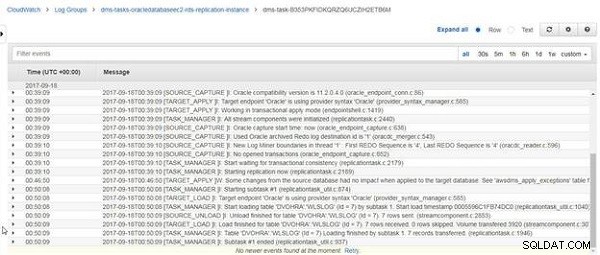
Figure 25 : Message du journal CloudWatch indiquant que le chargement est terminé
Arrêter et démarrer une tâche
Une tâche du type qui inclut la réplication en cours ne s'arrête pas d'elle-même à moins qu'une erreur ne se produise. Pour arrêter la tâche, cliquez sur Arrêter (voir Figure 26).
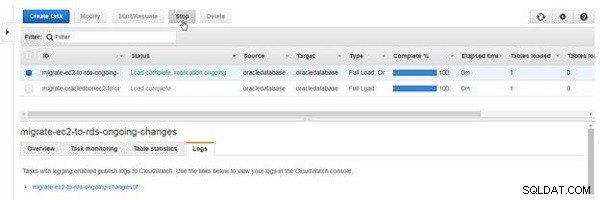
Figure 26 : Arrêter une tâche
Dans Arrêter la tâche boîte de dialogue, cliquez sur Arrêter , comme illustré à la Figure 27.
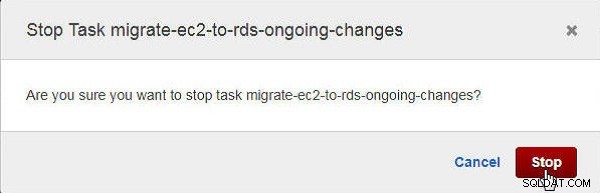
Figure 27 : Boîte de dialogue de confirmation pour arrêter une tâche
L'état de la tâche devient Arrêt , comme illustré à la Figure 28.
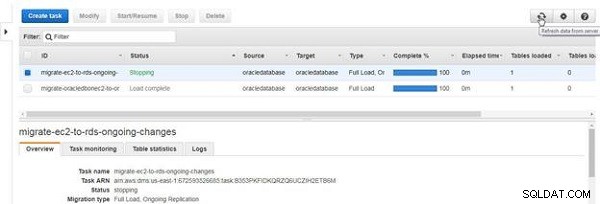
Figure 28 : Arrêter une tâche
Lorsqu'une tâche s'arrête, le statut devient Arrêté , comme illustré à la Figure 29.
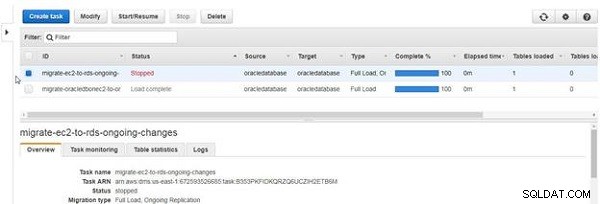
Figure 29 : Tâche arrêtée
Pour démarrer une tâche arrêtée, cliquez sur Démarrer/Reprendre , comme illustré à la Figure 30.
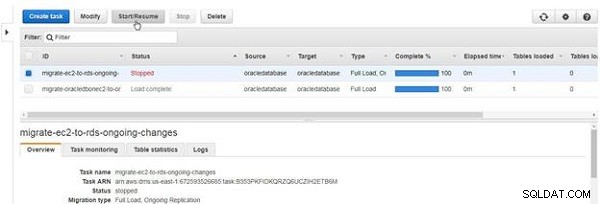
Figure 30 : Démarrer ou reprendre une tâche
Dans le Démarrer la tâche boîte de dialogue, cliquez sur Démarrer pour démarrer la tâche à partir du point d'arrêt (voir Figure 31). L'autre option consiste à redémarrer la tâche.
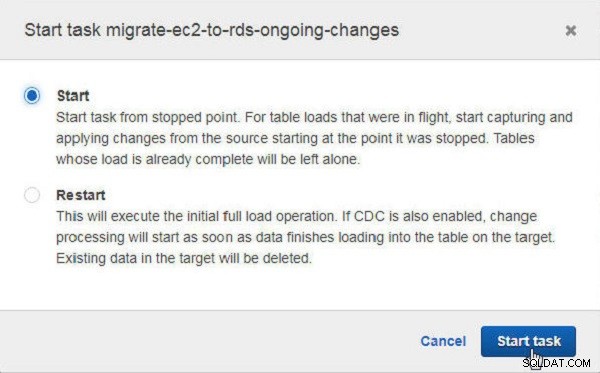
Figure 31 : Démarrage de la tâche après l'arrêt
Le statut de la tâche devient Démarrage , comme illustré à la Figure 32.

Figure 32 : Démarrer une tâche
Lorsque la migration des données existantes est terminée, la tâche continue de s'exécuter avec le statut Chargement terminé, réplication en cours , comme illustré à la Figure 33.

Figure 33 : Chargement terminé, réplication en cours
Supprimer des bases de données
L'instance de base de données RDS peut être supprimée avec les Actions d'instance>Supprimer commande. La base de données Oracle sur l'instance EC2 peut être arrêtée avec Actions>Etat de l'instance>Arrêter , comme illustré à la Figure 34.

Figure 34 : Arrêt de l'instance EC2
Conclusion
Dans quatre articles, nous avons discuté de la migration d'une base de données Oracle d'AWS EC2 vers AWS RDS.