Cela pourrait être un moyen :
-- a test case
with test(id, str) as (
select 1, 'This is a EXAMPLE' from dual union all
select 2, 'This is a TEST' from dual union all
select 3, 'This is a VALUE' from dual union all
select 4, 'This IS aN EXAMPLE' from dual
)
-- concatenate the resulting words
select id, listagg(str, ' ') within group (order by pos)
from (
-- tokenize the strings by using the space as a word separator
SELECT id,
trim(regexp_substr(str, '[^ ]+', 1, level)) str,
level as pos
FROM test t
CONNECT BY instr(str, ' ', 1, level - 1) > 0
and prior id = id
and prior sys_guid() is not null
)
-- only get the uppercase words
where regexp_like(str, '^[A-Z]+$')
group by id
L'idée est de tokeniser chaque chaîne, puis de couper les mots qui ne sont pas constitués de caractères majuscules, puis de concaténer les mots restants.
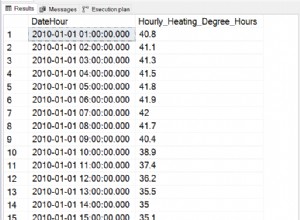
Le résultat :
1 EXAMPLE
2 TEST
3 VALUE
4 IS EXAMPLE
Si vous devez gérer un autre caractère en majuscule, vous pouvez modifier le where condition pour filtrer les mots correspondants ; par exemple, avec '_' :
with test(id, str) as (
select 1, 'This is a EXAMPLE' from dual union all
select 2, 'This is a TEST' from dual union all
select 3, 'This is a VALUE' from dual union all
select 4, 'This IS aN EXAMPLE' from dual union all
select 5, 'This IS AN_EXAMPLE' from dual
)
select id, listagg(str, ' ') within group (order by pos)
from (
SELECT id,
trim(regexp_substr(str, '[^ ]+', 1, level)) str,
level as pos
FROM test t
CONNECT BY instr(str, ' ', 1, level - 1) > 0
and prior id = id
and prior sys_guid() is not null
)
where regexp_like(str, '^[A-Z_]+$')
group by id
donne :
1 EXAMPLE
2 TEST
3 VALUE
4 IS EXAMPLE
5 IS AN_EXAMPLE