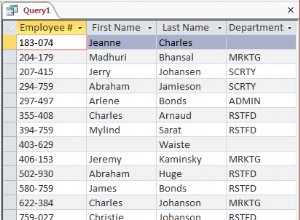
C'est facile à faire avec une technique appelée Tabibitosan.
Cette technique compare les positions des lignes de chaque groupe à l'ensemble des lignes, afin de déterminer si les lignes d'un même groupe sont côte à côte ou non.
Par exemple, avec vos données d'exemple, cela ressemble à :
WITH your_table AS (SELECT 1 ID, 'Michael' NAME, 'Marketing' department FROM dual UNION ALL
SELECT 2 ID, 'Alex' NAME, 'Marketing' department FROM dual UNION ALL
SELECT 3 ID, 'Tom' NAME, 'Marketing' department FROM dual UNION ALL
SELECT 4 ID, 'John' NAME, 'Sales' department FROM dual UNION ALL
SELECT 5 ID, 'Brad' NAME, 'Marketing' department FROM dual UNION ALL
SELECT 6 ID, 'Leo' NAME, 'Marketing' department FROM dual UNION ALL
SELECT 7 ID, 'Kevin' NAME, 'Production' department FROM dual)
-- end of mimicking your table with data in it. See the SQL below:
SELECT ID,
NAME,
department,
row_number() OVER (ORDER BY ID) overall_rn,
row_number() OVER (PARTITION BY department ORDER BY ID) department_rn,
row_number() OVER (ORDER BY ID) - row_number() OVER (PARTITION BY department ORDER BY ID) grp
FROM your_table;
ID NAME DEPARTMENT OVERALL_RN DEPARTMENT_RN GRP
---------- ------- ---------- ---------- ------------- ----------
1 Michael Marketing 1 1 0
2 Alex Marketing 2 2 0
3 Tom Marketing 3 3 0
4 John Sales 4 1 3
5 Brad Marketing 5 4 1
6 Leo Marketing 6 5 1
7 Kevin Production 7 1 6
Ici, j'ai donné à toutes les lignes de l'ensemble des données un numéro de ligne dans l'ordre croissant des identifiants (le overall_rn colonne), et j'ai donné aux lignes de chaque département un numéro de ligne (le department_rn colonne), toujours dans l'ordre croissant des identifiants.
Maintenant que j'ai fait cela, nous pouvons soustraire l'un de l'autre (le grp colonne).
Remarquez comment le nombre dans la colonne grp reste le même pour les lignes de département qui sont côte à côte, mais il change à chaque fois qu'il y a un espace.
Par exemple. pour le service Marketing, les lignes 1 à 3 sont côte à côte et ont grp =0, mais la 4e ligne Marketing se trouve en fait sur la 5e ligne de l'ensemble de résultats global, elle a donc maintenant un numéro de grp différent. Étant donné que la 5e ligne marketing se trouve sur la 6e ligne de l'ensemble global, elle a le même numéro de groupe que la 4e ligne marketing, nous savons donc qu'elles sont côte à côte.
Une fois que nous avons ces informations grp, il suffit de faire une requête agrégée regroupant à la fois le service et notre nouvelle colonne grp, en utilisant min et max pour trouver les identifiants de début et de fin :
WITH your_table AS (SELECT 1 ID, 'Michael' NAME, 'Marketing' department FROM dual UNION ALL
SELECT 2 ID, 'Alex' NAME, 'Marketing' department FROM dual UNION ALL
SELECT 3 ID, 'Tom' NAME, 'Marketing' department FROM dual UNION ALL
SELECT 4 ID, 'John' NAME, 'Sales' department FROM dual UNION ALL
SELECT 5 ID, 'Brad' NAME, 'Marketing' department FROM dual UNION ALL
SELECT 6 ID, 'Leo' NAME, 'Marketing' department FROM dual UNION ALL
SELECT 7 ID, 'Kevin' NAME, 'Production' department FROM dual)
-- end of mimicking your table with data in it. See the SQL below:
SELECT department,
MIN(ID) start_id,
MAX(ID) end_id
FROM (SELECT ID,
NAME,
department,
row_number() OVER (ORDER BY ID) - row_number() OVER (PARTITION BY department ORDER BY ID) grp
FROM your_table)
GROUP BY department, grp;
DEPARTMENT START_ID END_ID
---------- ---------- ----------
Marketing 1 3
Marketing 5 6
Sales 4 4
Production 7 7
N.B., j'ai supposé que les lacunes dans les colonnes d'id ne sont pas importantes (c'est-à-dire s'il n'y avait pas de ligne pour id =6 (donc les identifiants de Leo et Kevin étaient respectivement de 7 et 8), alors Leo et Brad apparaîtraient toujours dans le même groupe, avec un identifiant de début =5 et un identifiant de fin =7.
Si les espaces dans les colonnes id comptent comme indiquant un nouveau groupe, vous pouvez simplement utiliser l'id pour étiqueter l'ensemble global de lignes (c'est-à-dire qu'il n'est pas nécessaire de calculer le overall_rn ; utilisez simplement la colonne id à la place).
Cela signifie que votre requête deviendrait :
WITH your_table AS (SELECT 1 ID, 'Michael' NAME, 'Marketing' department FROM dual UNION ALL
SELECT 2 ID, 'Alex' NAME, 'Marketing' department FROM dual UNION ALL
SELECT 3 ID, 'Tom' NAME, 'Marketing' department FROM dual UNION ALL
SELECT 4 ID, 'John' NAME, 'Sales' department FROM dual UNION ALL
SELECT 5 ID, 'Brad' NAME, 'Marketing' department FROM dual UNION ALL
SELECT 7 ID, 'Leo' NAME, 'Marketing' department FROM dual UNION ALL
SELECT 8 ID, 'Kevin' NAME, 'Production' department FROM dual)
-- end of mimicking your table with data in it. See the SQL below:
SELECT department,
MIN(ID) start_id,
MAX(ID) end_id
FROM (SELECT ID,
NAME,
department,
ID - row_number() OVER (PARTITION BY department ORDER BY ID) grp
FROM your_table)
GROUP BY department, grp;
DEPARTMENT START_ID END_ID
---------- ---------- ----------
Marketing 1 3
Sales 4 4
Marketing 5 5
Marketing 7 7
Production 8 8