Aperçu
Oracle Data Mining (ODM) est un composant de l'option de base de données Oracle Advanced Analytics. ODM contient une suite d'algorithmes avancés d'exploration de données intégrés dans la base de données qui vous permet d'effectuer des analyses avancées sur vos données.
Oracle Data Miner est une extension d'Oracle SQL Developer, un environnement de développement graphique pour Oracle SQL. Oracle Data Miner utilise la technologie d'exploration de données intégrée à Oracle Database pour créer, exécuter et gérer des workflows qui encapsulent les opérations d'exploration de données. L'architecture d'ODM est illustrée à la figure 1.
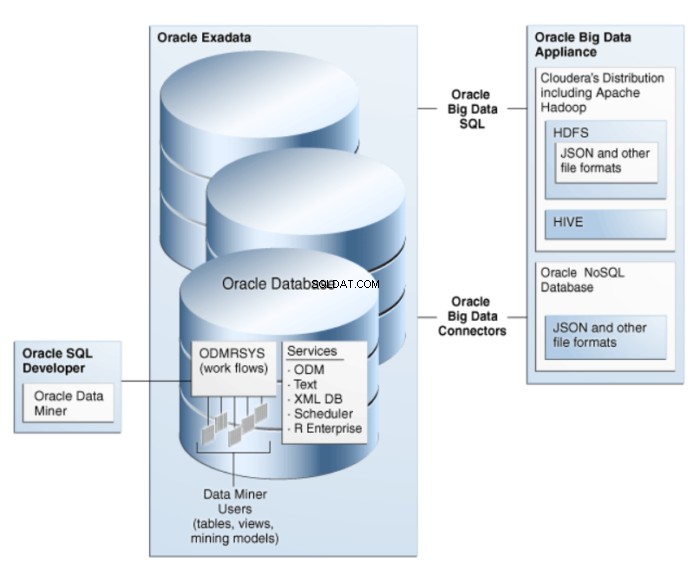
Figure 1 :Architecture d'exploration de données Oracle pour le Big Data
Les algorithmes sont implémentés en tant que fonctions SQL et exploitent les atouts de la base de données Oracle. Les fonctions d'exploration de données SQL peuvent extraire des données transactionnelles, des agrégations, des données non structurées, c'est-à-dire des données de type CLOB (à l'aide d'Oracle Text) et des données spatiales.
Chaque fonction d'exploration de données spécifie une classe de problèmes qui peuvent être modélisés et résolus. Les fonctions d'exploration de données se répartissent généralement en deux catégories :supervisées et non supervisées.
Les notions d'apprentissage supervisé et non supervisé sont dérivées de la science de l'apprentissage automatique, qui a été qualifiée de sous-domaine de l'intelligence artificielle.
L'apprentissage supervisé est également appelé apprentissage dirigé. Le processus d'apprentissage est dirigé par un attribut ou une cible dépendante précédemment connue. L'exploration de données dirigée tente d'expliquer le comportement de la cible en fonction d'un ensemble d'attributs ou de prédicteurs indépendants.
L'apprentissage non supervisé est non dirigé. Il n'y a pas de distinction entre les attributs dépendants et indépendants. Il n'y a pas de résultat connu pour guider l'algorithme dans la construction du modèle. L'apprentissage non supervisé peut être utilisé à des fins descriptives.
Algorithmes supervisés d'exploration de données Oracle
| Technique | Applicabilité | Algorithmes (brève description) |
|---|---|---|
Classification | Technique la plus couramment utilisée pour prédire un résultat spécifique, par exemple l'identification des cellules tumorales cancéreuses, l'analyse des sentiments, la classification des médicaments, la détection des spams. | Régression logistique des modèles linéaires généralisés - technique statistique classique disponible dans la base de données Oracle dans une implémentation hautement performante, évolutive et parallélisée (s'applique à tous les algorithmes OAA ML). Prend en charge le texte et les données transactionnelles (s'applique à presque tous les algorithmes OAA ML) Naive Bayes - Rapide, simple, couramment applicable. Support Vector Machine - Algorithme d'apprentissage automatique, prend en charge le texte et des données étendues. Arbre de décision - Algorithme ML populaire pour l'interprétabilité. Fournit des "règles" lisibles par l'homme |
Régression | Technique de prédiction d'un résultat numérique continu tel que l'analyse de données astronomiques, la génération d'informations sur le comportement des consommateurs, la rentabilité et d'autres facteurs commerciaux, le calcul des relations causales entre les paramètres des systèmes biologiques. | Modèles linéaires généralisés Régression multiple - technique statistique classique mais désormais disponible dans la base de données Oracle en tant qu'implémentation hautement performante, évolutive et parallélisée. Prend en charge la régression de crête, la création de fonctionnalités et la sélection de fonctionnalités. Prend en charge le texte et les données transactionnelles. Support Vector Machine - Algorithme d'apprentissage automatique, prend en charge le texte et les données étendues. |
Importance des attributs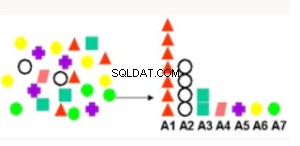 | Classe les attributs en fonction de la force de la relation avec l'attribut cible. Les cas d'utilisation incluent la recherche des facteurs les plus associés aux clients qui répondent à une offre, les facteurs les plus associés aux patients en bonne santé. | Longueur minimale de la description :considère chaque attribut comme un modèle prédictif simple de la classe cible et fournit une influence relative. |
Algorithmes non supervisés d'Oracle Data Mining
| Technique | Applicabilité | Algorithmes |
|---|---|---|
Clustering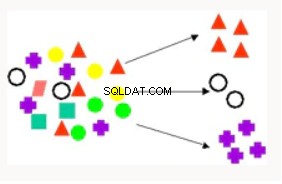 | Le clustering est utilisé pour partitionner les enregistrements d'une base de données en sous-ensembles ou clusters où les éléments d'un cluster partagent un ensemble de propriétés communes. Les exemples incluent la recherche de nouveaux segments de clientèle et les recommandations de films. | K-Means :prend en charge l'exploration de texte, le regroupement hiérarchique, basé sur la distance. Groupement de partitionnement orthogonal :regroupement hiérarchique, basé sur la densité. Maximisation des attentes :technique de clustering qui fonctionne bien dans les problèmes d'exploration de données mixtes (denses et clairsemées). |
Détection d'anomalies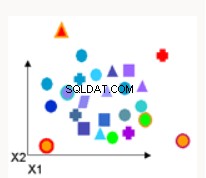 | La détection d'anomalies identifie les points de données, les événements et/ou les observations qui s'écartent du comportement normal d'un ensemble de données. Les exemples courants incluent la fraude bancaire, un défaut structurel, des problèmes médicaux ou des erreurs dans un texte | Machine à vecteurs de support à classe unique - entraîne des données non étiquetées et tente de déterminer si un point de test appartient à la distribution des données d'entraînement. |
Sélection et extraction de caractéristiques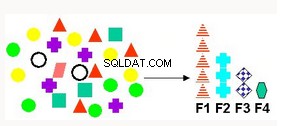 | Produit de nouveaux attributs sous forme de combinaison linéaire d'attributs existants. Applicable pour les données textuelles, l'analyse sémantique latente (LSA), la compression de données, la décomposition et la projection de données et la reconnaissance de formes. | Facturisation matricielle non négative :mappe les données d'origine dans le nouvel ensemble d'attributs Analyse en composantes principales (ACP) :crée de nouveaux attributs composites moins nombreux qui représentent tous les attributs. Décomposition vectorielle singulière - méthode d'extraction de caractéristiques établie qui a un large éventail d'applications. |
Association | Trouve les règles associées aux articles fréquemment co-occurrents, utilisées pour l'analyse du panier d'achat, la vente croisée, l'analyse des causes profondes. Utile pour le regroupement de produits et l'analyse des défauts. | Apriori - Hachage d'un arbre pour collecter des informations dans une base de données |
Activation de l'option d'exploration de données Oracle
À partir de la version 2 de la version 12c, Oracle Advanced Analytics L'option inclut la fonctionnalité Data Mining et Oracle R.
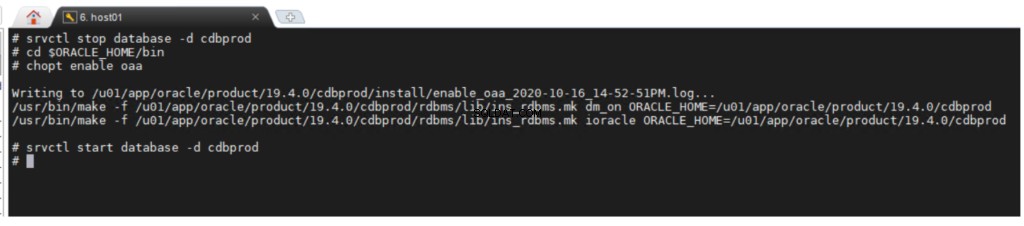
L'option Oracle Advanced Analytics est activée par défaut lors de l'installation d'Oracle Database Enterprise Edition. Si vous souhaitez activer ou désactiver une option de base de données, vous pouvez utiliser l'utilitaire de ligne de commande chopt .
chopt [ enable | disable ] oaa
Pour activer l'option Oracle Advanced Analytics :
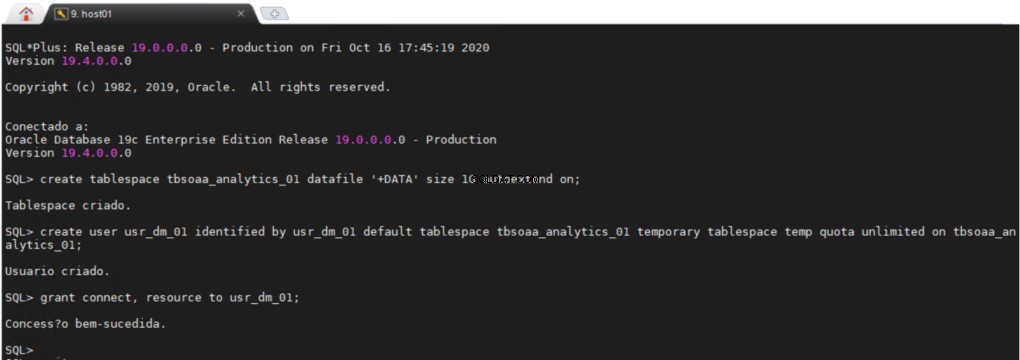
Création d'un tablespace avec un schéma ODM
Tous les utilisateurs ont besoin d'un espace de table permanent et d'un espace de table temporaire dans lequel faire leur travail, il peut être très utile d'avoir une zone séparée dans votre base de données où vous pouvez créer tous vos objets d'exploration de données.
Le usr_dm_01 schéma contiendra tous vos travaux d'exploration de données.
Création du référentiel ODM
Vous devez créer un référentiel d'exploration de données Oracle dans la base de données. Accédez au navigateur Data Miner dans SQL Developer.
Sélectionnez Affichage -> Data Miner -> Connexions Data Miner :
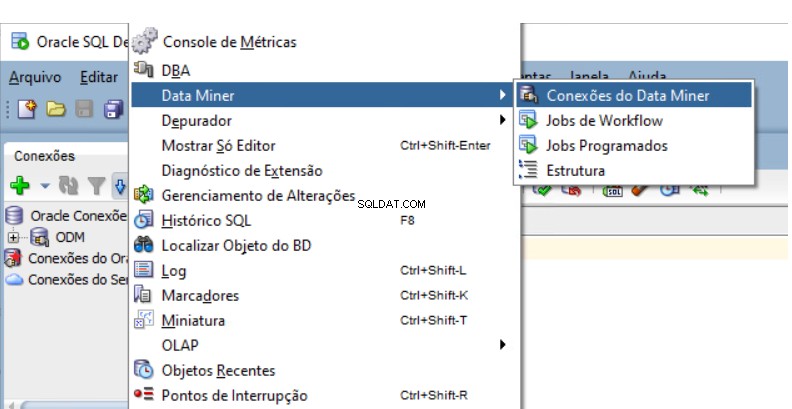
Un nouvel onglet s'ouvre à côté de votre onglet Connexions existant :
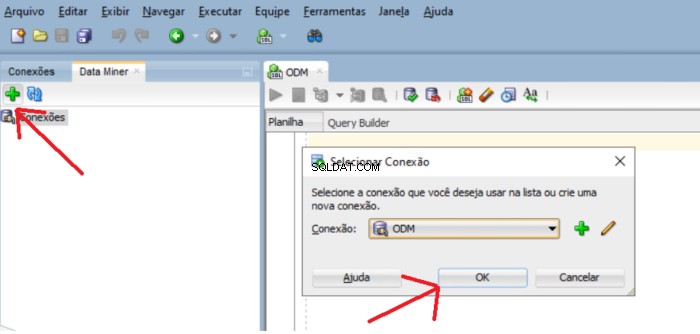
Pour ajouter usr_dm_01 schéma à cette liste, cliquez sur les fenêtres plus vertes et OK
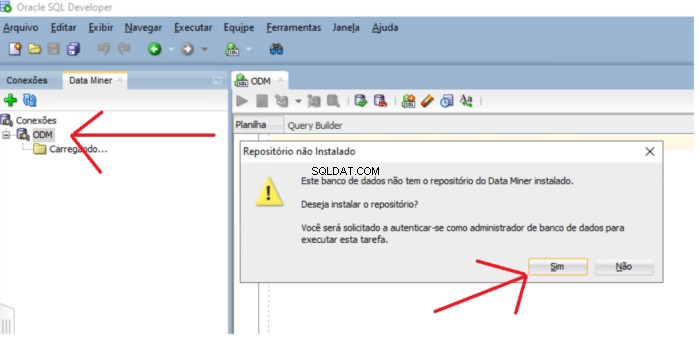
Si le référentiel n'existe pas, un message s'affiche vous demandant si vous souhaitez installer le référentiel. Cliquez sur Oui bouton pour poursuivre l'installation.
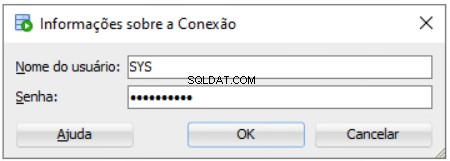
Vous devez entrer le mot de passe SYS
Paramètre d'installation du référentiel
Fenêtre de progression de l'installation du référentiel Data Miner
Tâche terminée avec succès
Fichier journal
Composants d'exploration de données Oracle
Le workflow vous permet de créer une série de nœuds qui effectuent tous les traitements requis sur vos données.
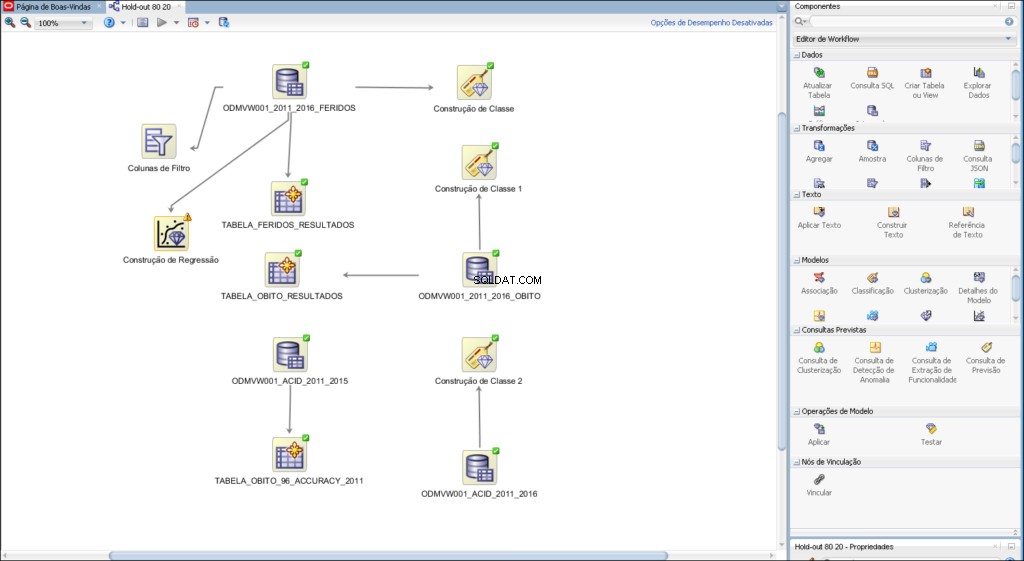
Exemple de workflow développé pour l'analyse prédictive
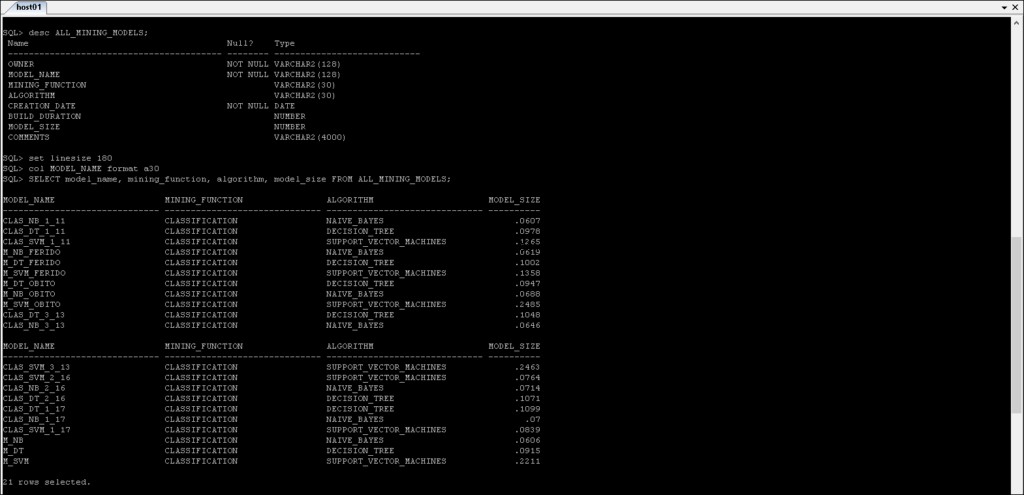
Vues du dictionnaire de données ODM
Vous pouvez obtenir des informations sur les modèles d'exploration de données à partir du dictionnaire de données.
Les vues du dictionnaire de données Data Mining sont résumées comme suit :
Remarque :* peut être remplacé par ALL_, USER_, DBA_ et CDB_
*_MINING_MODELS :Informations sur les modèles de minage qui ont été créés.
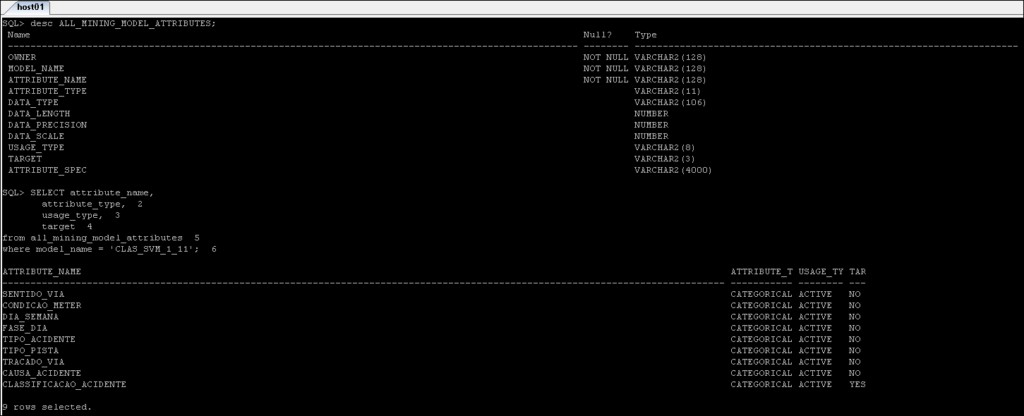
*_MINING_MODEL_ATTRIBUTES :Contient les détails des attributs qui ont été utilisés pour créer le modèle Oracle Data Mining.
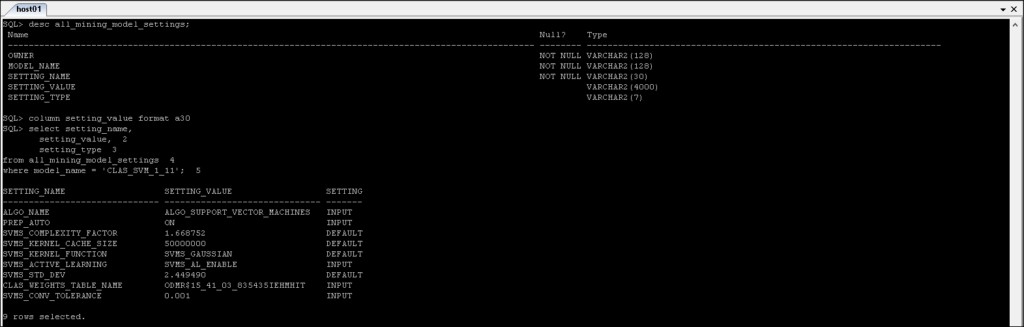
*_MINING_MODEL_SETTINGS :renvoie des informations sur les paramètres des modèles d'exploration de données auxquels vous avez accès.
Références
Guide de l'utilisateur d'Oracle Data Mining. Disponible sur :https://docs.oracle.com/en/database/oracle/oracle-database/19/dmprg/lot.html
Oracle Data Mining – Analyse prédictive évolutive dans la base de données. Disponible sur :https://www.oracle.com/database/technologies/advanced-analytics/odm.html
Présentation du système Oracle Data Miner. Disponible sur :https://docs.oracle.com/database/sql-developer-17.4/DMRIG/oracle-data-miner-overview.htm#DMRIG124