Dans cet article, je vais vous expliquer comment déplacer une table du groupe de fichiers principal vers le groupe de fichiers secondaire. Tout d'abord, comprenons ce que sont les fichiers de données, les groupes de fichiers et les types de groupes de fichiers.
Fichiers de base de données et groupes de fichiers
Lorsque SQL Server est installé sur n'importe quel serveur, il crée un fichier de données principal et un fichier journal pour stocker les données. Le fichier de données principal stocke les données et les objets de base de données tels que les tables, l'index, les procédures stockées, etc. Les fichiers journaux stockent les informations nécessaires pour récupérer les transactions. Les fichiers de données peuvent être regroupés dans des groupes de fichiers.
SQL Server a trois types de fichiers
- Fichier principal :Il est créé lors de l'installation du serveur SQL et contient les métadonnées et les informations de la base de données. Les données utilisateur, les objets peuvent être stockés sur les fichiers de données primaires. Le fichier principal porte l'extension .mdf.
- Fichier secondaire :Les fichiers secondaires sont définis par l'utilisateur. Ils stockent les données de l'utilisateur, les objets créés par un utilisateur. Ils ont l'extension .ndf.
- Fichier journal des transactions s :Les fichiers T-Logs consignent toutes les transactions effectuées pour récupérer la base de données. L'extension du fichier journal en .ldf.
Comme je l'ai mentionné ci-dessus, les fichiers de données peuvent être regroupés dans un groupe de fichiers. Lors de l'installation de SQL Server, il crée le groupe de fichiers principal contenant un fichier de données principal. Les groupes de fichiers secondaires sont définis par l'utilisateur. Ils ont des fichiers de données secondaires. Lorsque nous créons une nouvelle base de données, nous pouvons créer des fichiers de données secondaires et des groupes de fichiers. L'ajout de fichiers de données secondaires permet d'améliorer les performances. Il peut être créé sur différents lecteurs de disque ou sur des partitions de disque distinctes, ce qui réduit l'attente d'E/S et la latence de lecture-écriture.
Il est recommandé de conserver les tables et les index dans des groupes de fichiers séparés. De plus, conserver les grandes tables dans des fichiers séparés améliore les performances.
Il existe trois types de groupes de fichiers :
- Groupe de fichiers de lignes :Le groupe de fichiers de ligne, également appelé groupe de fichiers principal, contient un fichier de données principal. Objet SQL, données, tables système allouées au groupe de fichiers principal.
- Groupe de fichiers à mémoire optimisée :Le groupe de fichiers à mémoire optimisée contient des tables et des données à mémoire optimisée. Pour activer l'OLTP en mémoire, nous devons créer un groupe de fichiers à mémoire optimisée.
- FileStream :Le groupe de fichiers de flux de fichiers contient des données de flux de fichiers telles que des images, des documents, des fichiers exécutables, etc. Le groupe de fichiers principal ne peut pas contenir de données de flux de fichiers, nous devons créer un groupe de fichiers FileStream. Il contient les données FileStream.
Configuration de la démo
Dans cette démo, j'ai créé "DemoDatabase" sur l'instance SQL Server 2017. Les onglets « Dossiers » et « DonnéesPatient » ont été créés sur la base de données. La clé primaire "PK_CIDX_Records_ID" a été créée sur la table "Records" et l'index clusterisé "CIDX_PatientData_ID" a été créé sur la table "PatientData". Dans cette démo, je vais déplacer les tables "Records" et "PatientData" du groupe de fichiers principal vers le groupe de fichiers secondaire.
Pour cela, nous devons procéder comme suit :
- Créez un groupe de fichiers secondaire.
- Ajouter des fichiers de données au groupe de fichiers secondaire.
- Déplacez la table vers le groupe de fichiers secondaire en déplaçant l'index clusterisé avec la contrainte de clé primaire.
- Déplacez les tables vers le groupe de fichiers secondaire en déplaçant l'index clusterisé sans la clé primaire.
Créer un groupe de fichiers secondaire
Un groupe de fichiers secondaire peut être créé à l'aide de T-SQL OU à l'aide de l'assistant Ajouter un fichier de SQL Server Management Studio. Pour ajouter un groupe de fichiers à l'aide de SSMS, ouvrez SSMS et sélectionnez une base de données dans laquelle un groupe de fichiers doit être créé. Faites un clic droit sur la base de données sélectionnez "Propriétés ”>> sélectionnez “Groupes de fichiers " et cliquez sur " Ajouter un groupe de fichiers ” comme indiqué dans l'image suivante :
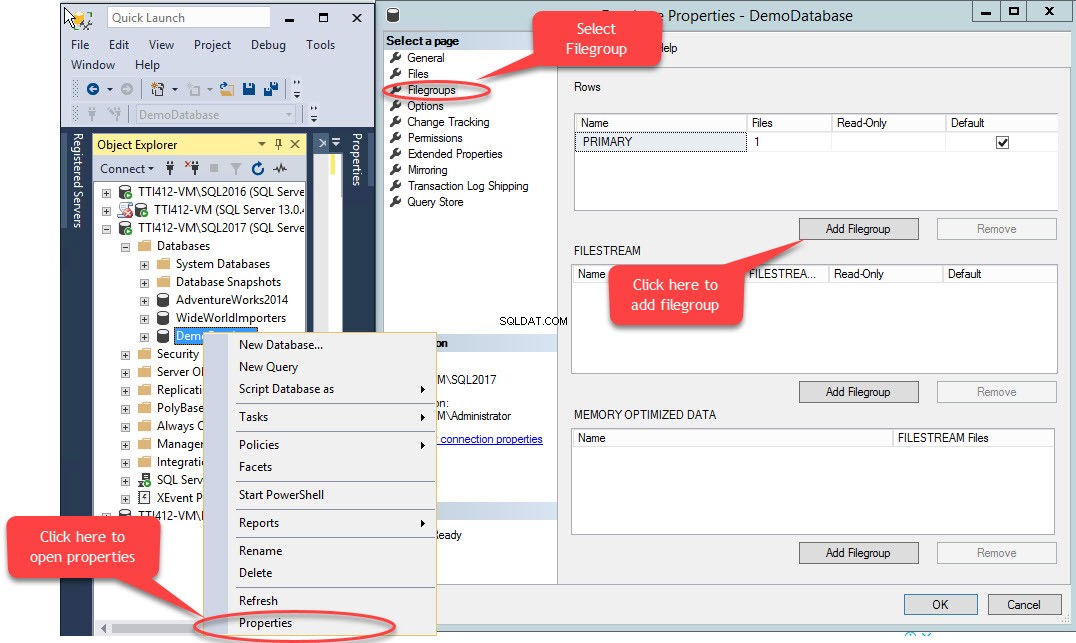
Lorsque nous cliquons sur "Ajouter un groupe de fichiers ", une ligne sera ajoutée dans le "Lignes " la grille. Dans les "Lignes ", indiquez le nom du groupe de fichiers approprié dans le champ "Name " colonne. Le groupe de fichiers n'est ni en lecture seule ni par défaut ; par conséquent, conservez le Lecture seule et Par défaut cases à cocher désactivées pour le nouveau groupe de fichiers. Voir l'image suivante :
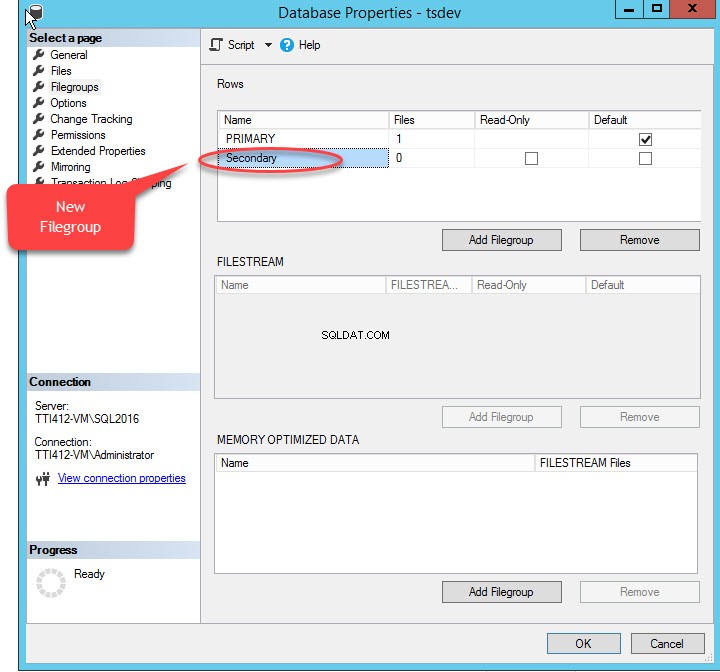
Cliquez sur OK pour fermer la boîte de dialogue.
Pour créer un groupe de fichiers à l'aide du script T-SQL, exécutez le script suivant.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILEGROUP [Secondary ] GO
Ajouter des fichiers au groupe de fichiers
Pour ajouter des fichiers dans un groupe de fichiers, ouvrez les propriétés de la base de données, sélectionnez "fichiers" et cliquez sur "Ajouter". Comme le montre l'image suivante :
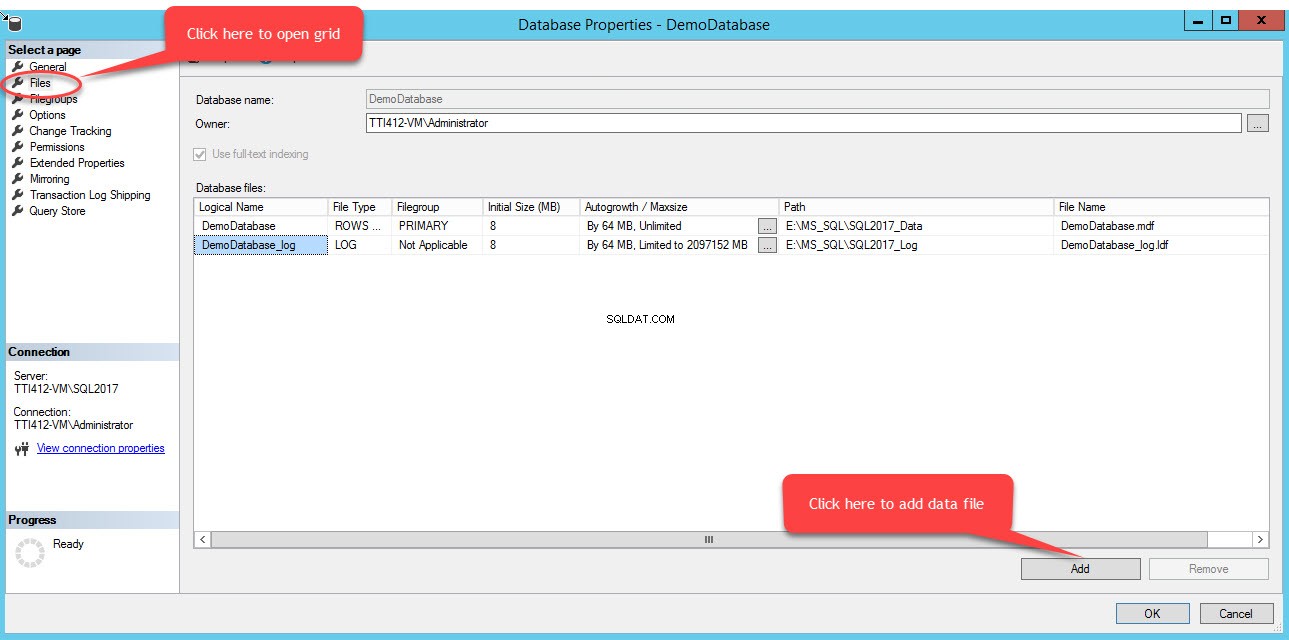
Une ligne vide sera ajoutée dans les Fichiers de la base de données vue grille. Dans la vue Grille, indiquez le nom logique approprié dans le champ Nom logique colonne, sélectionnez Données de lignes à partir du Type de fichier liste déroulante, sélectionnez secondaire du groupe de fichiers liste déroulante, définissez la taille initiale du fichier dans la taille initiale colonnes, définissez les paramètres de croissance automatique et de taille maximale dans Autogrowth/Maxsize colonne, indiquez l'emplacement physique du fichier de données secondaire dans le Chemin colonne et indiquez le nom de fichier approprié dans le champ Nom de fichier colonne. Voir l'image suivante :
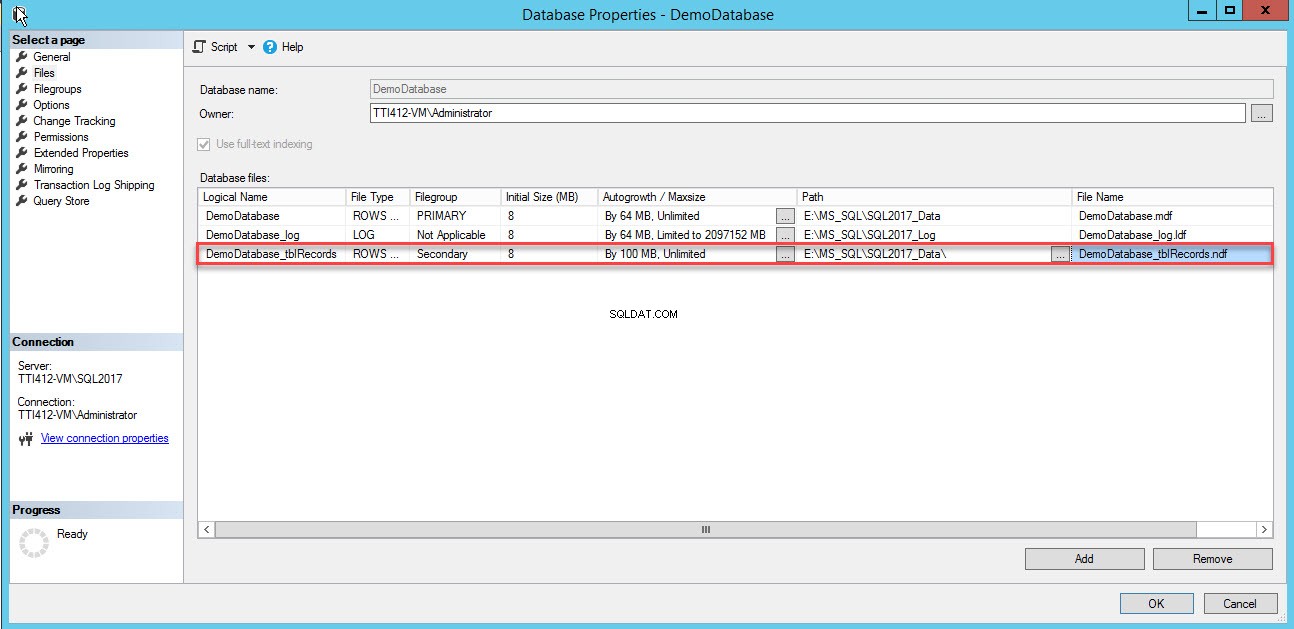
Utilisez le script T-SQL suivant pour créer un fichier de données secondaire.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILE ( NAME = N'DemoDatabase_tblRecords', FILENAME = N'E:\MS_SQL\SQL2017_Data\DemoDatabase_tblRecords.ndf' , SIZE = 8192KB , FILEGROWTH = 102400KB ) TO FILEGROUP [Secondary] GO
Le fichier de données secondaire a été créé. Voir l'image suivante :
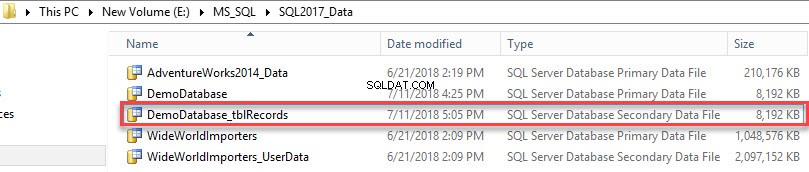
Pour afficher une liste des groupes de fichiers créés sur la base de données, exécutez la requête suivante.
use DemoDatabase go select a.Name as 'File group Name', type_desc as 'Filegroup Type', case when is_default=1 then 'Yes' else 'No' end as 'Is filegroup default?', b.filename as 'File Location', b.name 'Logical Name', Convert(numeric(10,3),Convert(numeric(10,3),(size/128))/1024) as 'File Size in MB' from sys.filegroups a inner join sys.sysfiles b on a.data_space_id=b.groupid
Vous trouverez ci-dessous un résultat de la requête.

Transfert d'une table existante du groupe de fichiers principal vers le groupe de fichiers secondaire
Nous pouvons déplacer une table existante vers un autre groupe de fichiers en déplaçant l'index clusterisé vers un autre groupe de fichiers. Comme nous le savons, un nœud feuille de l'index clusterisé contient des données réelles ; par conséquent, le déplacement de l'index clusterisé peut déplacer la table entière vers un autre groupe de fichiers. Le déplacement d'index a une limitation :si l'index est une clé primaire ou une contrainte unique, vous ne pouvez pas déplacer l'index à l'aide de SQL Server Management Studio. Pour déplacer ces index, nous devons utiliser le créer un index déclaration et avec DROP_Existing=ON option.
Déplacer l'index clusterisé avec une contrainte de clé primaire.
La clé primaire applique des valeurs uniques, créant ainsi l'index clusterisé unique. La colonne clé est PRN. Pour le créer dans le groupe de fichiers secondaire, définissez le DROP_EXISTING=ON option et le groupe de fichiers doivent être secondaires. Exécutez le script suivant.
USE [DemoDatabas] GO Create Unique Clustered index [PK_CIDX_Records_ID] ON [Records] (ID asc) WITH (DROP_EXISTING=ON) ON [Secondary]
Une fois la commande exécutée avec succès, vérifiez que l'index a été créé dans le groupe de fichiers secondaire. Pour cela, faites un clic droit sur le Stockage option dans les Propriétés de l'index boite de dialogue. Pour ouvrir les propriétés d'index, développez la DemoDatabase base de données>> développer Tableaux>> développer Index . Cliquez avec le bouton droit sur PK_CIDX_Records_ID , comme illustré dans l'image suivante :
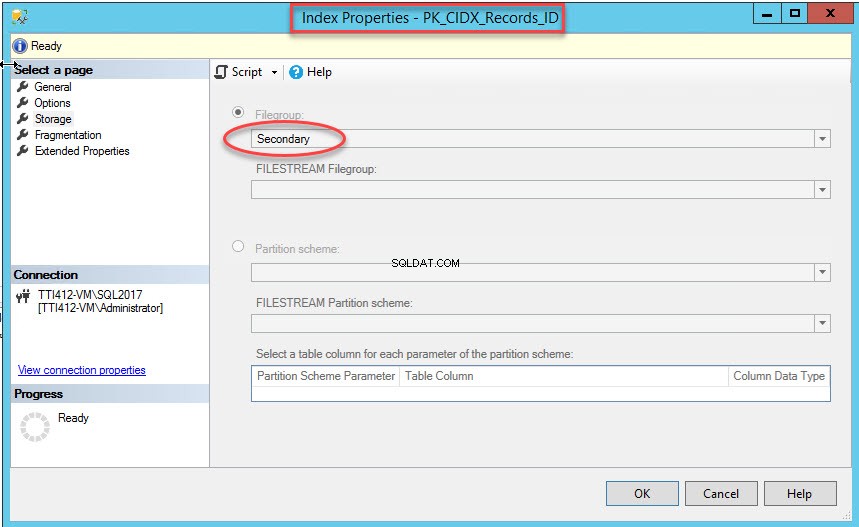
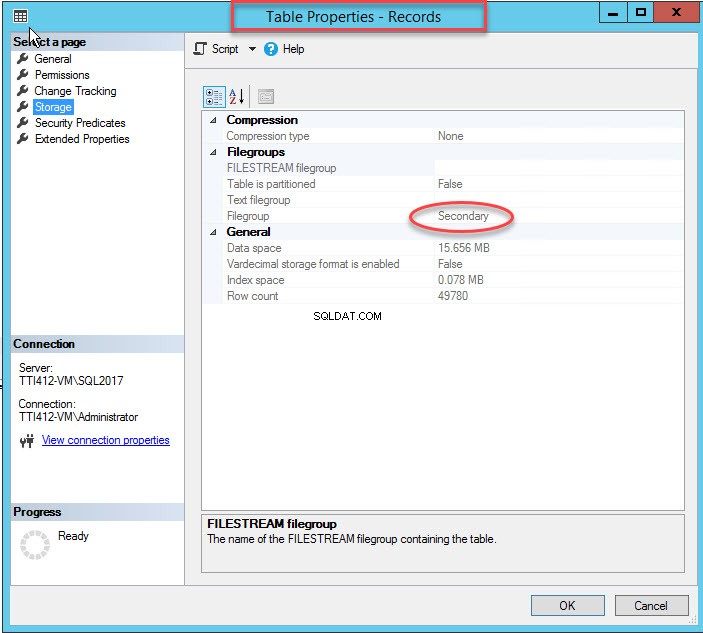
Comme je l'ai mentionné, une fois l'index clusterisé déplacé vers un groupe de fichiers secondaire, la table sera déplacée vers le groupe de fichiers secondaire. Pour le vérifier, faites un clic droit sur le Stockage option dans les Propriétés du tableau boite de dialogue. Pour ouvrir les propriétés d'index, développez la DemoDatabase base de données>> développer Table s>> clic droit Enregistrements, et sélectionnez stockage, comme indiqué dans l'image suivante :
Déplacer l'index clusterisé sans clé primaire
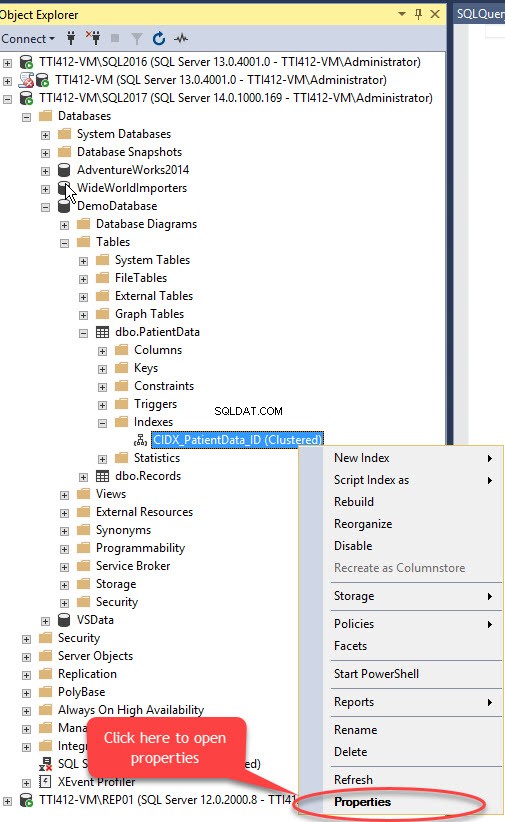
Nous pouvons déplacer l'index clusterisé sans clé primaire à l'aide de SQL Server Management Studio. Pour ce faire, développez la DemoDatabase base de données>> développer Tableaux>> développer Index s>> faites un clic droit sur CIDX_PatientData_ID index et sélectionnez Propriétés, comme indiqué dans l'image suivante :
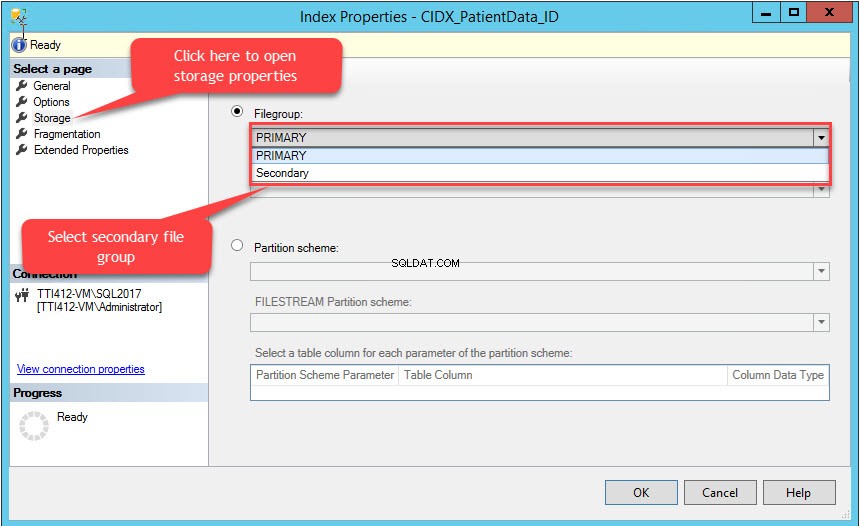
Les propriétés d'index boîte de dialogue s'ouvre. Dans la boîte de dialogue, sélectionnez Stockage, et dans la fenêtre Stockage, cliquez sur Groupe de fichiers dans la liste déroulante, sélectionnez Secondaire groupe de fichiers et cliquez sur OK, comme le montre l'image suivante :
La modification du groupe de fichiers d'index recréera l'intégralité de l'index. Une fois l'index recréé, ouvrez Propriétés de la table et sélectionnez un stockage.
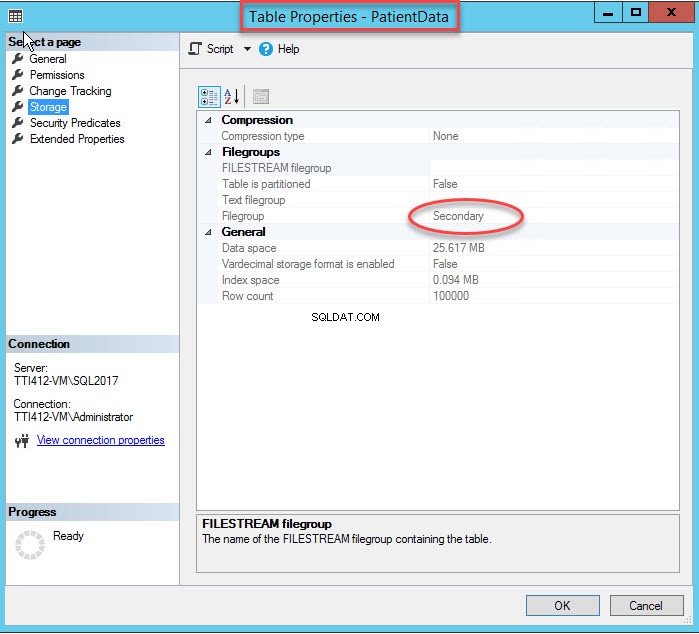
Comme vous pouvez le voir dans l'image ci-dessus, avec le déplacement du CIDX_PatientData_ID index clusterisé vers le groupe de fichiers secondaire, the PatientData la table est également déplacée vers le secondaire groupe de fichiers.
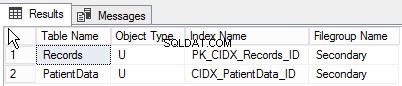
En exécutant la requête suivante, vous pouvez trouver la liste des objets créés dans différents groupes de fichiers :
SELECT obj.[name] as [Table Name],
obj.[type] as [Object Type],
Indx.[name] as [Index Name],
fG.[name] as [Filegroup Name]
FROM sys.indexes INDX
INNER JOIN sys.filegroups FG
ON INDX.data_space_id = fG.data_space_id
INNER JOIN sys.all_objects Obj
ON INDX.[object_id] = obj.[object_id]
WHERE INDX.data_space_id = fG.data_space_id
And obj.type='U'
go Ci-dessous le résultat de la requête :
Résumé
Dans cet article, j'ai expliqué
-
- Principes de base des fichiers de données et des groupes de fichiers
- Comment créer un groupe de fichiers secondaire et y ajouter un fichier de données secondaire.
- Déplacez la table vers le groupe de fichiers secondaire en déplaçant :
- Clé primaire.
- Index cluster.