La charge de travail de la base de données MySQL est déterminée par le nombre de requêtes qu'elle traite. Il existe plusieurs situations dans lesquelles la lenteur de MySQL peut provenir. La première possibilité est s'il y a des requêtes qui n'utilisent pas l'indexation appropriée. Lorsqu'une requête ne peut pas utiliser d'index, le serveur MySQL doit utiliser plus de ressources et de temps pour traiter cette requête. En surveillant les requêtes, vous avez la possibilité d'identifier le code SQL qui est à l'origine d'un ralentissement et de le corriger avant que les performances globales ne se dégradent.
Dans cet article de blog, nous allons mettre en évidence la fonctionnalité Query Outlier disponible dans ClusterControl et voir comment elle peut nous aider à améliorer les performances de la base de données. En général, ClusterControl effectue l'échantillonnage des requêtes MySQL de deux manières :
- Récupérer les requêtes à partir du schéma de performance (recommandé ).
- Analyser le contenu de MySQL Slow Query.
Si le schéma de performances est désactivé, ClusterControl utilisera alors par défaut le journal des requêtes lentes. Pour en savoir plus sur la façon dont ClusterControl effectue cela, consultez cet article de blog, Comment utiliser le moniteur de requêtes ClusterControl pour MySQL, MariaDB et Percona Server.
Qu'est-ce qu'une requête aberrante ?
Une valeur aberrante est une requête qui prend plus de temps que le temps de requête normal de ce type. Ne considérez pas littéralement cela comme des requêtes "mal écrites". Il doit être traité comme des requêtes courantes sous-optimales potentielles qui pourraient être améliorées. Après un certain nombre d'échantillons et lorsque ClusterControl a eu suffisamment de statistiques, il peut déterminer si la latence est supérieure à la normale (2 sigmas + average_query_time), il s'agit alors d'une valeur aberrante et sera ajouté à la valeur aberrante de la requête.
Cette fonctionnalité dépend de la fonctionnalité Principales requêtes. Si la surveillance des requêtes est activée et que les principales requêtes sont capturées et renseignées, les valeurs aberrantes des requêtes les résumeront et fourniront un filtre basé sur l'horodatage. Pour voir la liste des requêtes qui nécessitent une attention particulière, accédez à ClusterControl -> Query Monitor -> Query Outliers et vous devriez voir certaines requêtes répertoriées (le cas échéant) :
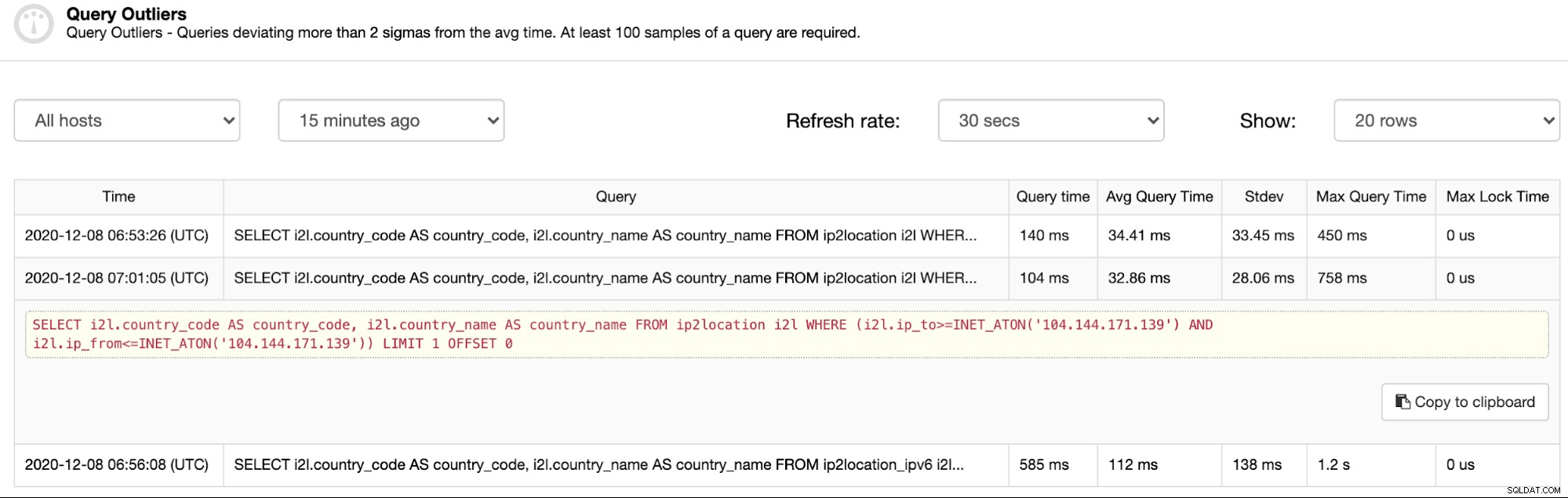
Comme vous pouvez le voir sur la capture d'écran ci-dessus, les valeurs aberrantes sont essentiellement des requêtes qui a pris au moins 2 fois plus de temps que le temps de requête moyen. D'abord la première entrée, le temps moyen est de 34,41 ms tandis que le temps d'interrogation de la valeur aberrante est de 140 ms (plus de 2 fois supérieur au temps moyen). De même, pour les entrées suivantes, les colonnes Query Time et Avg Query Time sont deux éléments importants pour justifier les encours d'une requête particulière.
Il est relativement facile de trouver un modèle d'une valeur aberrante de requête particulière en examinant une période plus longue, comme il y a une semaine, comme le montre la capture d'écran suivante :
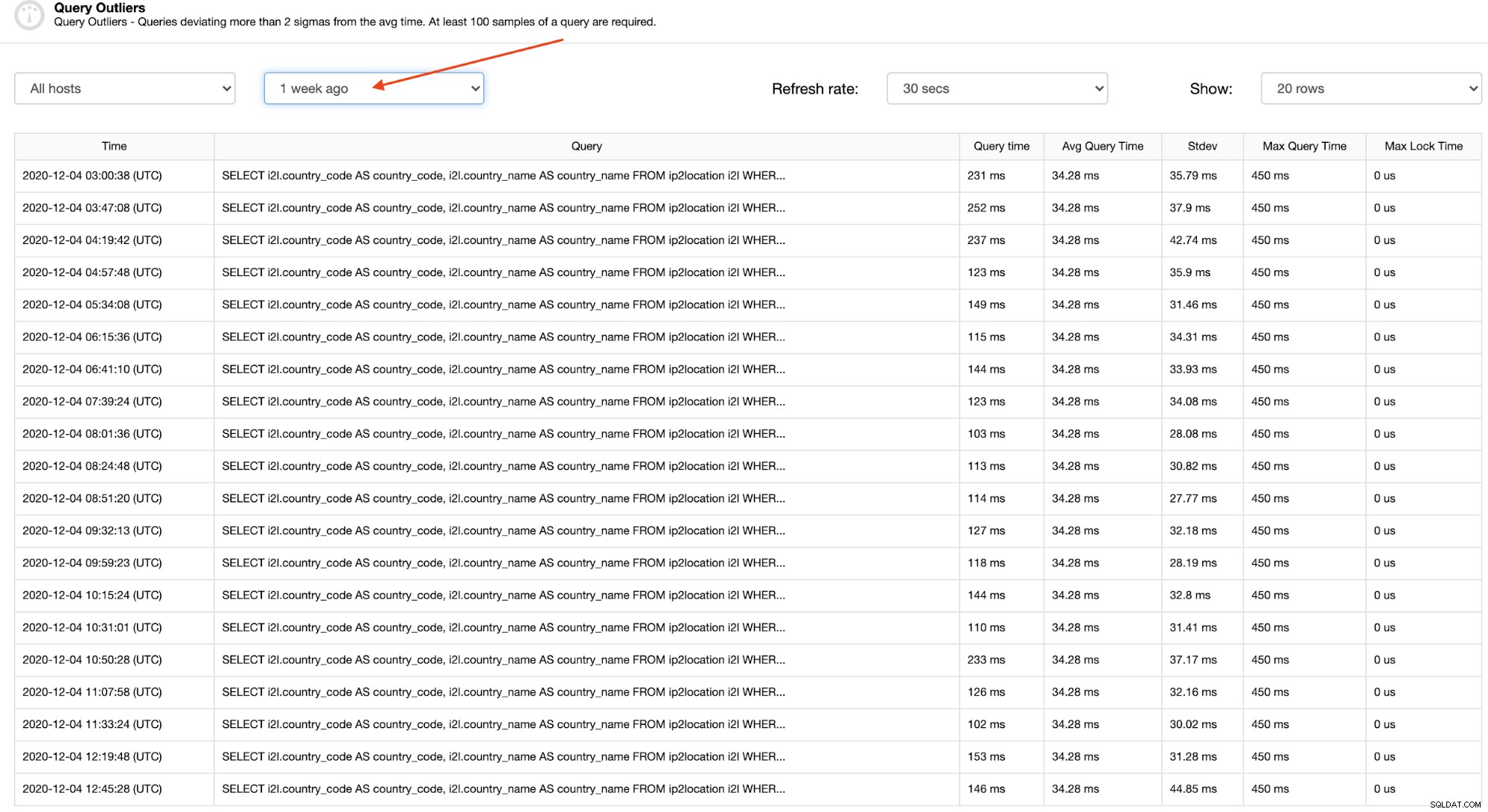
En cliquant sur chaque ligne, vous pouvez voir la requête complète qui est vraiment utile pour identifier et comprendre le problème, comme indiqué dans la section suivante.
Correction des valeurs aberrantes de la requête
Pour corriger les valeurs aberrantes, nous devons comprendre la nature de la requête, le moteur de stockage des tables, la version de la base de données, le type de clustering et l'impact de la requête. Dans certains cas, la requête aberrante ne dégrade pas vraiment les performances globales de la base de données. Comme dans cet exemple, nous avons vu que la requête s'est démarquée pendant toute la semaine et que c'était le seul type de requête capturé, c'est donc probablement une bonne idée de corriger ou d'améliorer cette requête si possible.
Comme dans notre cas, la requête aberrante est :
SELECT i2l.country_code AS country_code, i2l.country_name AS country_name
FROM ip2location i2l
WHERE (i2l.ip_to >= INET_ATON('104.144.171.139')
AND i2l.ip_from <= INET_ATON('104.144.171.139'))
LIMIT 1
OFFSET 0;Et le résultat de la requête est :
+--------------+---------------+
| country_code | country_name |
+--------------+---------------+
| US | United States |
+--------------+---------------+Utiliser EXPLAIN
La requête est une requête de sélection de plage en lecture seule pour déterminer les informations de localisation géographique de l'utilisateur (code de pays et nom de pays) pour une adresse IP sur la table ip2location. L'utilisation de l'instruction EXPLAIN peut nous aider à comprendre le plan d'exécution de la requête :
mysql> EXPLAIN SELECT i2l.country_code AS country_code, i2l.country_name AS country_name
FROM ip2location i2l
WHERE (i2l.ip_to>=INET_ATON('104.144.171.139')
AND i2l.ip_from<=INET_ATON('104.144.171.139'))
LIMIT 1 OFFSET 0;
+----+-------------+-------+------------+-------+--------------------------------------+-------------+---------+------+-------+----------+------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+--------------------------------------+-------------+---------+------+-------+----------+------------------------------------+
| 1 | SIMPLE | i2l | NULL | range | idx_ip_from,idx_ip_to,idx_ip_from_to | idx_ip_from | 5 | NULL | 66043 | 50.00 | Using index condition; Using where |
+----+-------------+-------+------------+-------+--------------------------------------+-------------+---------+------+-------+----------+------------------------------------+La requête est exécutée avec un balayage de plage sur la table en utilisant l'index idx_ip_from avec 50 % de lignes potentielles (filtrées).
Moteur de stockage approprié
En regardant la structure de la table d'ip2location :
mysql> SHOW CREATE TABLE ip2location\G
*************************** 1. row ***************************
Table: ip2location
Create Table: CREATE TABLE `ip2location` (
`ip_from` int(10) unsigned DEFAULT NULL,
`ip_to` int(10) unsigned DEFAULT NULL,
`country_code` char(2) COLLATE utf8_bin DEFAULT NULL,
`country_name` varchar(64) COLLATE utf8_bin DEFAULT NULL,
KEY `idx_ip_from` (`ip_from`),
KEY `idx_ip_to` (`ip_to`),
KEY `idx_ip_from_to` (`ip_from`,`ip_to`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_binCe tableau est basé sur la base de données IP2location et il est rarement mis à jour/écrit, généralement uniquement le premier jour du mois civil (recommandé par le fournisseur). Une option consiste donc à convertir la table en moteur de stockage MyISAM (MySQL) ou Aria (MariaDB) avec un format de ligne fixe pour obtenir de meilleures performances en lecture seule. Notez que cela ne s'applique que si vous exécutez MySQL ou MariaDB en mode autonome ou en réplication. Sur Galera Cluster et Group Replication, veuillez vous en tenir au moteur de stockage InnoDB (sauf si vous savez ce que vous faites).
Quoi qu'il en soit, pour convertir la table d'InnoDB en MyISAM avec un format de ligne fixe, exécutez simplement la commande suivante :
ALTER TABLE ip2location ENGINE=MyISAM ROW_FORMAT=FIXED;Dans notre mesure, avec 1 000 tests de recherche d'adresse IP aléatoires, les performances des requêtes se sont améliorées d'environ 20 % avec MyISAM et le format de ligne fixe :
- Durée moyenne (InnoDB) :21,467823 ms
- Durée moyenne (MyISAM fixe) :17,175942 ms
- Amélioration :19,992157565301 %
Vous pouvez vous attendre à ce que ce résultat soit immédiat après la modification de la table. Aucune modification sur le niveau supérieur (application/load balancer) n'est nécessaire.
Réglage de la requête
Une autre façon consiste à inspecter le plan de requête et à utiliser une approche plus efficace pour un meilleur plan d'exécution de la requête. La même requête peut également être écrite en utilisant une sous-requête comme ci-dessous :
SELECT `country_code`, `country_name` FROM
(SELECT `country_code`, `country_name`, `ip_from`
FROM `ip2location`
WHERE ip_to >= INET_ATON('104.144.171.139')
LIMIT 1)
AS temptable
WHERE ip_from <= INET_ATON('104.144.171.139');La requête optimisée a le plan d'exécution de requête suivant :
mysql> EXPLAIN SELECT `country_code`,`country_name` FROM
(SELECT `country_code`, `country_name`, `ip_from`
FROM `ip2location`
WHERE ip_to >= INET_ATON('104.144.171.139')
LIMIT 1)
AS temptable
WHERE ip_from <= INET_ATON('104.144.171.139');
+----+-------------+--------------+------------+--------+---------------+-----------+---------+------+-------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+--------+---------------+-----------+---------+------+-------+----------+-----------------------+
| 1 | PRIMARY | <derived2> | NULL | system | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
| 2 | DERIVED | ip2location | NULL | range | idx_ip_to | idx_ip_to | 5 | NULL | 66380 | 100.00 | Using index condition |
+----+-------------+--------------+------------+--------+---------------+-----------+---------+------+-------+----------+-----------------------+En utilisant la sous-requête, nous pouvons optimiser la requête en utilisant une table dérivée qui se concentre sur un index. La requête ne doit renvoyer qu'un seul enregistrement où la valeur ip_to est supérieure ou égale à la valeur de l'adresse IP. Cela permet aux lignes potentielles (filtrées) d'atteindre 100% ce qui est le plus efficace. Ensuite, vérifiez que ip_from est inférieur ou égal à la valeur de l'adresse IP. Si c'est le cas, alors nous devrions trouver l'enregistrement. Sinon, l'adresse IP n'existe pas dans la table ip2location.
Dans notre mesure, les performances de la requête se sont améliorées d'environ 99 % en utilisant une sous-requête :
- Durée moyenne (InnoDB + analyse de plage) :22,87112 ms
- Durée moyenne (InnoDB + sous-requête) :0,14744 ms
- Amélioration :99,355344207017 %
Avec l'optimisation ci-dessus, nous pouvons voir un temps d'exécution de requête inférieur à la milliseconde de ce type de requête, ce qui est une amélioration massive étant donné que le temps moyen précédent est de 22 ms. Cependant, nous devons apporter quelques modifications au niveau supérieur (application/équilibreur de charge) afin de bénéficier de cette requête optimisée.
Correction ou réécriture de requête
Corrigez vos applications pour utiliser la requête optimisée ou réécrivez la requête aberrante avant qu'elle n'atteigne le serveur de base de données. Nous pouvons y parvenir en utilisant un équilibreur de charge MySQL comme ProxySQL (règles de requête) ou MariaDB MaxScale (filtre de réécriture d'instructions), ou en utilisant le plugin MySQL Query Rewriter. Dans l'exemple suivant, nous utilisons ProxySQL devant notre cluster de base de données et nous pouvons simplement créer une règle pour réécrire la requête la plus lente dans la plus rapide, par exemple :
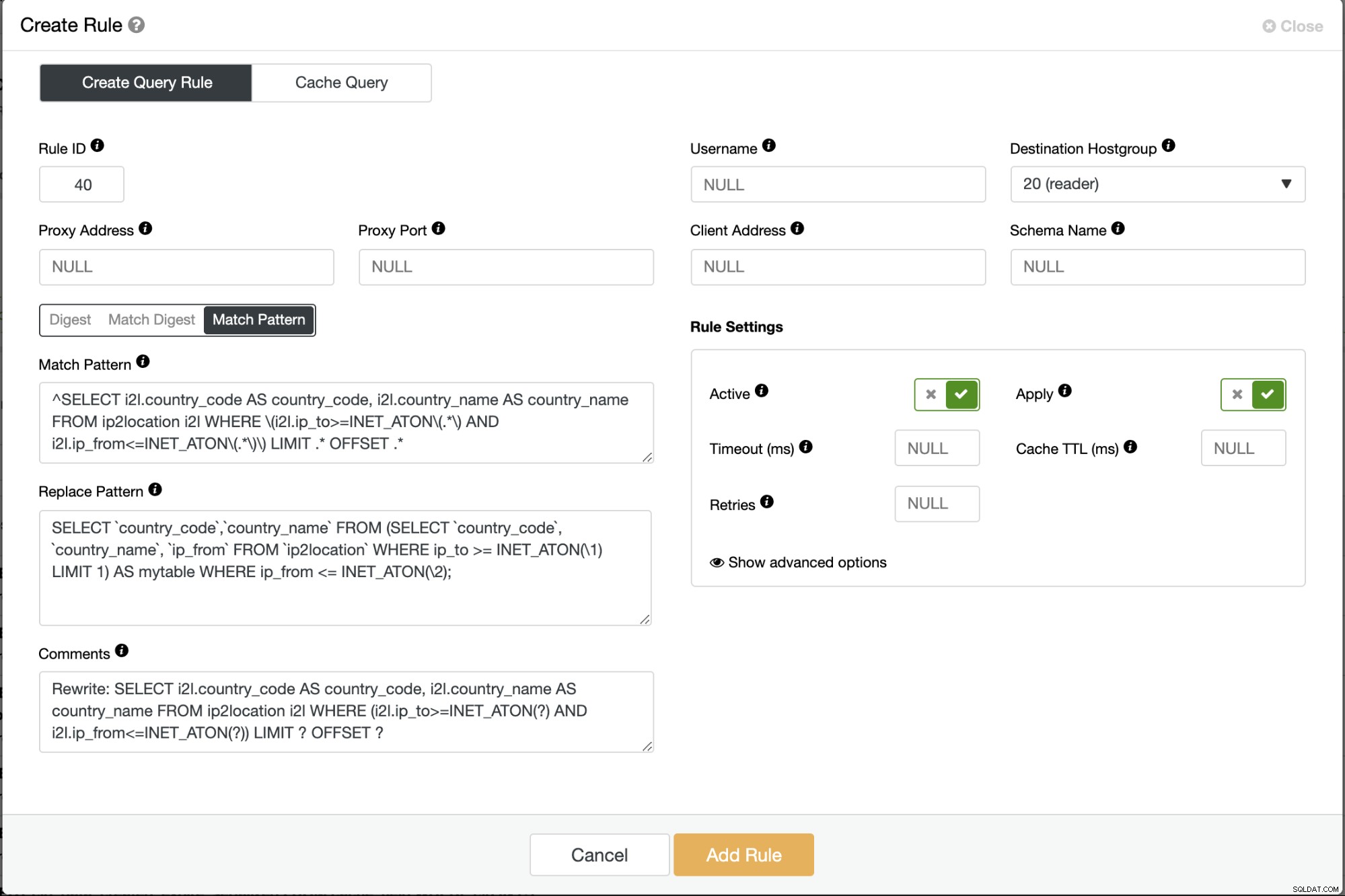
Enregistrez la règle de requête et surveillez la page Query Outliers dans ClusterControl. Ce correctif supprimera évidemment les requêtes aberrantes de la liste après l'activation de la règle de requête.
Conclusion
Query outliers est un outil de surveillance proactive des requêtes qui peut nous aider à comprendre et à résoudre le problème de performances avant qu'il ne devienne incontrôlable. Au fur et à mesure que votre application se développe et devient plus exigeante, cet outil peut vous aider à maintenir des performances de base de données décentes tout au long du chemin.