L'administrateur de base de données MySQL type peut être familier avec le travail et la gestion d'une base de données OLTP (traitement des transactions en ligne) dans le cadre de sa routine quotidienne. Vous savez peut-être comment cela fonctionne et comment gérer des opérations complexes. Bien que le moteur de stockage par défaut fourni par MySQL soit assez bon pour OLAP (traitement analytique en ligne), il est assez simpliste, en particulier pour ceux qui souhaitent apprendre l'intelligence artificielle ou qui traitent de la prévision, de l'exploration de données, de l'analyse de données.
Dans ce blog, nous allons discuter de MariaDB ColumnStore. Le contenu sera adapté pour le bénéfice du DBA MySQL qui pourrait avoir moins de compréhension avec le ColumnStore et comment il pourrait être applicable aux applications OLAP (Online Analytical Processing).
OLTP contre OLAP
OLTP
Ressources associées Analytics with MariaDB AX - the Open Source Columnar Datastore Introduction aux bases de données de séries chronologiques Charges de travail de base de données OLTP/Analytics hybrides dans le cluster Galera à l'aide d'esclaves asynchronesL'activité typique du DBA MySQL pour traiter ce type de données consiste à utiliser OLTP (traitement des transactions en ligne). OLTP se caractérise par de grandes transactions de base de données effectuant des insertions, des mises à jour ou des suppressions. Les bases de données de type OLTP sont spécialisées dans le traitement rapide des requêtes et le maintien de l'intégrité des données tout en étant accessibles dans plusieurs environnements. Son efficacité est mesurée par le nombre de transactions par seconde (tps). Il est assez fréquent que les tables de relations parent-enfant (après implémentation du formulaire de normalisation) réduisent les données redondantes dans une table.
Les enregistrements d'une table sont généralement traités et stockés séquentiellement de manière orientée ligne et sont fortement indexés avec des clés uniques pour optimiser la récupération ou les écritures de données. Ceci est également courant pour MySQL, en particulier lorsqu'il s'agit d'insertions volumineuses ou d'écritures simultanées élevées ou d'insertions en bloc. La plupart des moteurs de stockage pris en charge par MariaDB s'appliquent aux applications OLTP :InnoDB (le moteur de stockage par défaut depuis la version 10.2), XtraDB, TokuDB, MyRocks ou MyISAM/Aria.
Des applications telles que CMS, FinTech, Web Apps traitent souvent de lourdes écritures et lectures et nécessitent souvent un débit élevé. Pour faire fonctionner ces applications, il faut souvent une expertise approfondie en matière de haute disponibilité, de redondance, de résilience et de récupération.
OLAP
OLAP traite les mêmes défis que OLTP, mais utilise une approche différente (en particulier lorsqu'il s'agit de la récupération de données.) OLAP traite des ensembles de données plus volumineux et est courant pour l'entreposage de données, souvent utilisé pour les applications de type business intelligence. Il est couramment utilisé pour la gestion des performances de l'entreprise, la planification, la budgétisation, les prévisions, les rapports financiers, l'analyse, les modèles de simulation, la découverte des connaissances et les rapports d'entrepôt de données.
Les données stockées dans OLAP ne sont généralement pas aussi critiques que celles stockées dans OLTP. En effet, la plupart des données peuvent être simulées à partir d'OLTP et peuvent ensuite être introduites dans votre base de données OLAP. Ces données sont généralement utilisées pour le chargement en masse, souvent nécessaire pour l'analyse commerciale qui est finalement rendue sous forme de graphiques visuels. OLAP effectue également une analyse multidimensionnelle des données d'entreprise et fournit des résultats qui peuvent être utilisés pour des calculs complexes, une analyse des tendances ou une modélisation de données sophistiquée.
OLAP stocke généralement les données de manière persistante en utilisant un format en colonnes. Dans MariaDB ColumnStore, cependant, les enregistrements sont répartis en fonction de leurs colonnes et sont stockés séparément dans un fichier. De cette façon, la récupération des données est très efficace, car elle analyse uniquement la colonne pertinente référencée dans votre requête d'instruction SELECT.
Pensez-y comme ceci, le traitement OLTP gère vos transactions de données quotidiennes et cruciales qui exécutent votre application métier, tandis qu'OLAP vous aide à gérer, prévoir, analyser et mieux commercialiser votre produit - les éléments constitutifs d'une application métier.
Qu'est-ce que MariaDB ColumnStore ?
MariaDB ColumnStore est un moteur de stockage en colonne enfichable qui s'exécute sur MariaDB Server. Il utilise une architecture de données distribuée parallèle tout en conservant la même interface SQL ANSI que celle utilisée dans l'ensemble du portefeuille de serveurs MariaDB. Ce moteur de stockage existe depuis un certain temps, car il a été porté à l'origine à partir d'InfiniDB (un code désormais disparu qui est toujours disponible sur github.) Il est conçu pour la mise à l'échelle du Big Data (pour traiter des pétaoctets de données), l'évolutivité linéaire et la vraie -temps de réponse aux requêtes d'analyse. Il exploite les avantages d'E/S du stockage en colonne; compression, projection juste-à-temps et partitionnement horizontal et vertical pour offrir des performances exceptionnelles lors de l'analyse de grands ensembles de données.
Enfin, MariaDB ColumnStore est l'épine dorsale de leur produit MariaDB AX en tant que principal moteur de stockage utilisé par cette technologie.
En quoi MariaDB ColumnStore est-il différent d'InnoDB ?
InnoDB est applicable pour le traitement OLTP qui nécessite que votre application réponde le plus rapidement possible. C'est utile si votre application traite de cette nature. D'autre part, MariaDB ColumnStore est un choix approprié pour gérer les transactions de Big Data ou les grands ensembles de données qui impliquent des jointures complexes, l'agrégation à différents niveaux de la hiérarchie des dimensions, projeter un total financier pour un large éventail d'années ou utiliser des sélections d'égalité et de plage. . Ces approches utilisant ColumnStore ne vous obligent pas à indexer ces champs, car elles peuvent s'exécuter suffisamment plus rapidement. InnoDB ne peut pas vraiment gérer ce type de performances, même si rien ne vous empêche d'essayer comme c'est faisable avec InnoDB, mais à un coût. Cela vous oblige à ajouter des index, ce qui ajoute de grandes quantités de données à votre stockage sur disque. Cela signifie que la fin de votre requête peut prendre plus de temps et qu'elle peut ne pas se terminer du tout si elle est piégée dans une boucle temporelle.
Architecture MariaDB ColumnStore
Regardons l'architecture MariaDB ColumStore ci-dessous :
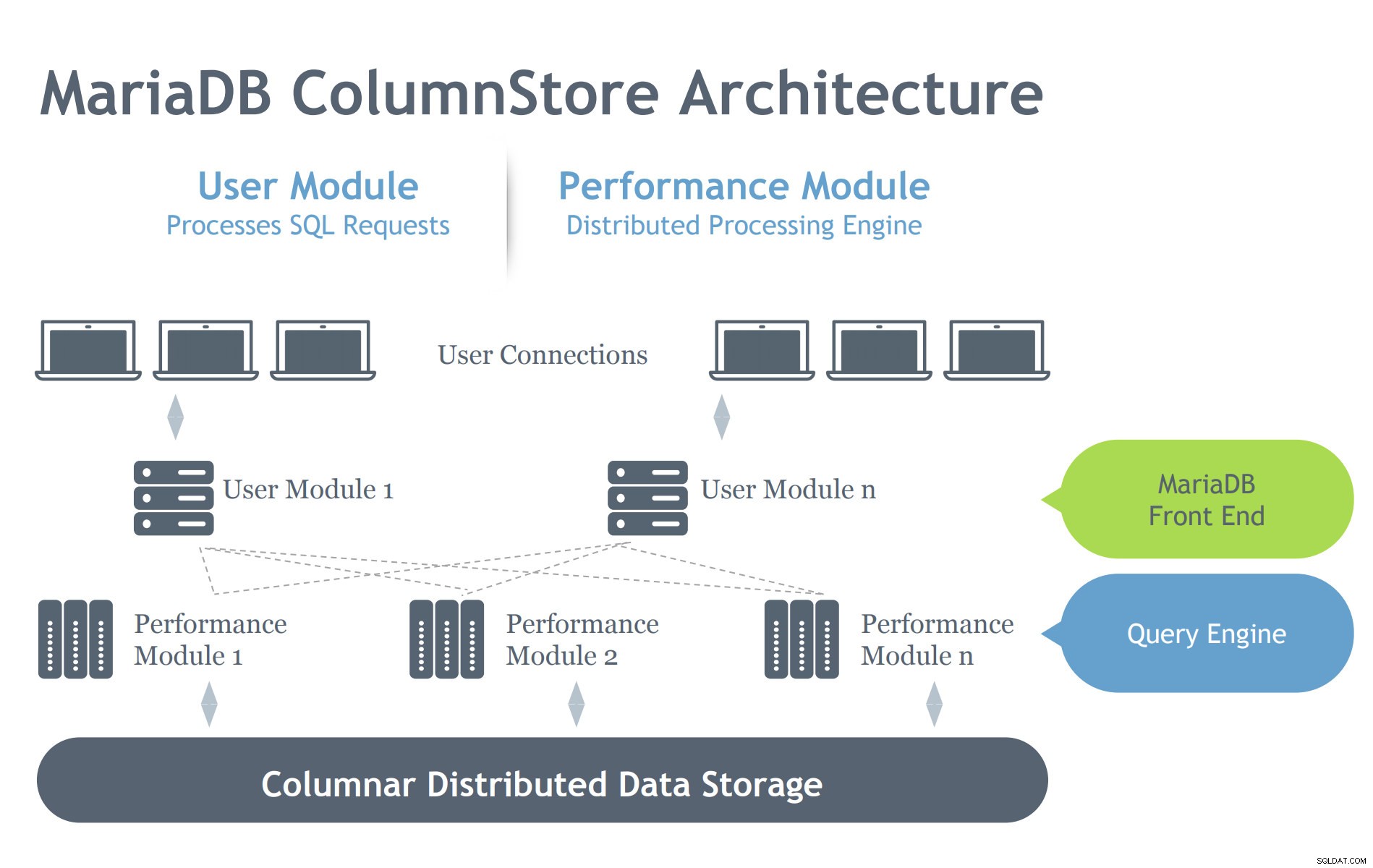 Image reproduite avec l'aimable autorisation de la présentation MariaDB ColumnStore
Image reproduite avec l'aimable autorisation de la présentation MariaDB ColumnStore Contrairement à l'architecture InnoDB, le ColumnStore contient deux modules qui indiquent que son intention est de travailler efficacement sur un environnement architectural distribué. InnoDB est destiné à évoluer sur un serveur, mais s'étend sur plusieurs nœuds interconnectés en fonction d'une configuration de cluster. Par conséquent, ColumnStore a plusieurs niveaux de composants qui prennent en charge les processus demandés au serveur MariaDB. Découvrons ces composants ci-dessous :
- Module utilisateur (UM) :l'UM est responsable de l'analyse des requêtes SQL dans un ensemble optimisé d'étapes de travail primitives exécutées par un ou plusieurs serveurs PM. L'UM est ainsi responsable de l'optimisation des requêtes et de l'orchestration de l'exécution des requêtes par les serveurs PM. Alors que plusieurs instances de MU peuvent être déployées dans un déploiement multiserveur, une seule MU est responsable de chaque requête individuelle. Un équilibreur de charge de base de données, tel que MariaDB MaxScale, peut être déployé pour équilibrer de manière appropriée les requêtes externes par rapport aux serveurs de messagerie unifiée individuels.
- Module de performance (PM) :le PM exécute des étapes de travail granulaires reçues d'un UM de manière multithread. ColumnStore permet la distribution du travail sur de nombreux modules de performance. La MU est composée du processus MariaDB mysqld et du processus ExeMgr.
- Cartes d'étendue :ColumnStore conserve les métadonnées de chaque colonne dans un objet distribué partagé connu sous le nom de carte d'étendue. Le serveur de messagerie unifiée fait référence à la carte d'étendue pour aider à générer les étapes de travail primitives correctes. Le serveur PM fait référence à la carte d'étendue pour identifier les blocs de disque corrects à lire. Chaque colonne est composée d'un ou plusieurs fichiers et chaque fichier peut contenir plusieurs étendues. Dans la mesure du possible, le système tente d'allouer un espace de stockage physique contigu pour améliorer les performances de lecture.
- Stockage :ColumnStore peut utiliser le stockage local ou le stockage partagé (par exemple, SAN ou EBS) pour stocker les données. L'utilisation du stockage partagé permet au traitement des données de basculer automatiquement vers un autre nœud en cas de défaillance d'un serveur PM.
Voici comment MariaDB ColumnStore traite la requête,
- Les clients envoient une requête au serveur MariaDB exécuté sur le module utilisateur. Le serveur effectue une opération de table pour toutes les tables nécessaires pour répondre à la requête et obtient le plan d'exécution de requête initial.
- À l'aide de l'interface du moteur de stockage MariaDB, ColumnStore convertit l'objet de la table du serveur en objets ColumnStore. Ces objets sont ensuite envoyés aux processus du module utilisateur.
- Le module utilisateur convertit le plan d'exécution MariaDB et optimise les objets donnés en un plan d'exécution ColumnStore. Il détermine ensuite les étapes nécessaires pour exécuter la requête et l'ordre dans lequel elles doivent être exécutées.
- Le module utilisateur consulte ensuite la carte d'étendue pour déterminer les modules de performance à consulter pour les données dont il a besoin, il effectue ensuite l'élimination de l'étendue, en éliminant tous les modules de performance de la liste qui ne contiennent que des données en dehors de la plage requise par la requête.
- Le module utilisateur envoie ensuite des commandes à un ou plusieurs modules de performance pour effectuer des opérations d'E/S de bloc.
- Le ou les modules de performance effectuent le filtrage des prédicats, le traitement des jointures, l'agrégation initiale des données à partir du stockage local ou externe, puis renvoient les données au module utilisateur.
- Le module utilisateur effectue l'agrégation finale de l'ensemble de résultats et compose l'ensemble de résultats pour la requête.
- Le module utilisateur / ExeMgr implémente tous les calculs de fonction de fenêtre, ainsi que tout tri nécessaire sur l'ensemble de résultats. Il renvoie ensuite le jeu de résultats au serveur.
- Le serveur MariaDB exécute toutes les fonctions de liste de sélection, les opérations ORDER BY et LIMIT sur l'ensemble de résultats.
- Le serveur MariaDB renvoie le jeu de résultats au client.
Paradigmes d'exécution des requêtes
Voyons un peu plus comment ColumnStore exécute la requête et quand cela a un impact.
ColumnStore diffère des moteurs de stockage MySQL/MariaDB standard tels qu'InnoDB puisque ColumnStore gagne en performance en analysant uniquement les colonnes nécessaires, en utilisant le partitionnement maintenu par le système et en utilisant plusieurs threads et serveurs pour adapter le temps de réponse aux requêtes. Les performances sont améliorées lorsque vous n'incluez que les colonnes nécessaires à la récupération de vos données. Cela signifie que l'astérisque gourmand (*) dans votre requête de sélection a un impact significatif par rapport à un SELECT
Comme avec InnoDB et d'autres moteurs de stockage, le type de données a également une importance dans les performances de ce que vous avez utilisé. Si vous avez une colonne qui ne peut avoir que des valeurs de 0 à 100, déclarez-la comme un tinyint car cela sera représenté avec 1 octet au lieu de 4 octets pour int. Cela réduira le coût des E/S de 4 fois. Pour les types de chaîne, un seuil important est char(9) et varchar(8) ou supérieur. Chaque fichier de stockage de colonne utilise un nombre fixe d'octets par valeur. Cela permet une recherche positionnelle rapide d'autres colonnes pour former la ligne. Actuellement, la limite supérieure pour le stockage de données en colonnes est de 8 octets. Ainsi, pour les chaînes plus longues que cela, le système maintient une étendue de « dictionnaire » supplémentaire dans laquelle les valeurs sont stockées. Le fichier d'étendue en colonnes stocke ensuite un pointeur dans le dictionnaire. Il est donc plus coûteux de lire et de traiter une colonne varchar(8) qu'une colonne char(8) par exemple. Ainsi, dans la mesure du possible, vous obtiendrez de meilleures performances si vous pouvez utiliser des chaînes plus courtes, en particulier si vous évitez la recherche dans le dictionnaire. Tous les types de données TEXT/BLOB à partir de la version 1.1 utilisent un dictionnaire et effectuent une recherche de plusieurs blocs de 8 Ko pour récupérer ces données si nécessaire. Plus les données sont longues, plus les blocs sont récupérés et plus l'impact potentiel sur les performances est important.
Dans un système basé sur des lignes, l'ajout de colonnes redondantes augmente le coût global de la requête, mais dans un système en colonnes, un coût ne se produit que si la colonne est référencée. Par conséquent, des colonnes supplémentaires doivent être créées pour prendre en charge différents chemins d'accès. Par exemple, stockez une partie principale d'un champ dans une colonne pour permettre des recherches plus rapides, mais stockez également la valeur de forme longue dans une autre colonne. Les scans sur un code plus court ou une colonne de partie principale seront plus rapides.
Les jointures de requête sont optimisées pour les jointures à grande échelle et évitent le besoin d'index et la surcharge du traitement des boucles imbriquées. ColumnStore gère les statistiques de table afin de déterminer l'ordre de jointure optimal. Des approches similaires sont partagées avec InnoDB, comme si la jointure est trop volumineuse pour la mémoire de la messagerie unifiée, elle utilise une jointure basée sur disque pour effectuer la requête.
Pour les agrégations, ColumnStore distribue autant que possible l'évaluation agrégée. Cela signifie qu'il partage entre UM et PM pour gérer les requêtes en particulier ou un très grand nombre de valeurs dans la ou les colonnes agrégées. Select count(*) est optimisé en interne pour sélectionner le plus petit nombre d'octets de stockage dans une table. Cela signifie qu'il choisirait la colonne CHAR(1) (utilise 1 octet) sur la colonne INT qui prend 4 octets. L'implémentation respecte toujours la sémantique ANSI dans la mesure où select count(*) inclura des valeurs nulles dans le nombre total, par opposition à une sélection explicite (COL-N) qui exclut les valeurs nulles dans le nombre.
L'ordre par et la limite sont actuellement implémentés à la toute fin par le processus du serveur mariadb sur la table d'ensemble de résultats temporaire. Cela a été mentionné à l'étape 9 sur la façon dont ColumnStore traite la requête. Donc techniquement, les résultats sont transmis à MariaDB Server pour trier les données.
Pour les requêtes complexes qui utilisent des sous-requêtes, c'est fondamentalement la même approche où elles sont exécutées en séquence et sont gérées par la messagerie unifiée, comme pour les fonctions de fenêtre gérées par la messagerie unifiée, mais elle utilise un processus de tri plus rapide dédié, donc c'est fondamentalement plus rapide.
Le partitionnement de vos données est fourni par ColumnStore qui utilise des cartes d'étendue qui conservent les valeurs min/max des données de colonne et fournissent une plage logique pour le partitionnement et suppriment le besoin d'indexation. Les cartes d'étendue fournissent également un partitionnement manuel des tables, des vues matérialisées, des tables récapitulatives et d'autres structures et objets que les bases de données basées sur les lignes doivent implémenter pour les performances des requêtes. Les valeurs en colonnes présentent certains avantages lorsqu'elles sont dans l'ordre ou dans un semi-ordre, car cela permet un partitionnement des données très efficace. Avec les valeurs min et max, les cartes d'étendue entières après le filtre et l'exclusion seront éliminées. Voir cette page dans leur manuel sur l'élimination de l'étendue. Cela fonctionne généralement particulièrement bien pour les données de séries chronologiques ou des valeurs similaires qui augmentent avec le temps.
Installation de MariaDB ColumnStore
L'installation de MariaDB ColumnStore peut être simple et directe. MariaDB contient ici une série de notes auxquelles vous pouvez vous référer. Pour ce blog, notre environnement cible d'installation est CentOS 7. Vous pouvez accéder à ce lien https://downloads.mariadb.com/ColumnStore/1.2.4/ et consulter les packages en fonction de votre environnement de système d'exploitation. Consultez les étapes détaillées ci-dessous pour vous aider à accélérer :
### Note: The installation details is ideal for root user installation
cd /root/
wget https://downloads.mariadb.com/ColumnStore/1.2.4/centos/x86_64/7/mariadb-columnstore-1.2.4-1-centos7.x86_64.rpm.tar.gz
tar xzf mariadb-columnstore-1.0.7-1-centos7.x86_64.rpm.tar.gz
sudo yum -y install boost expect perl perl-DBI openssl zlib snappy libaio perl-DBD-MySQL net-tools wget jemalloc
sudo rpm -ivh mariadb-columnstore*.rpm
Une fois cela fait, vous devez exécuter postConfigure commande pour enfin installer et configurer votre MariaDB ColumnStore. Dans cet exemple d'installation, il y a deux nœuds que j'ai configurés en cours d'exécution sur une machine vagabonde :
csnode1:192.168.2.10
csnode2:192.168.2.20
Ces deux nœuds sont définis dans leurs /etc/hosts respectifs et les deux nœuds ciblés sont configurés pour que leurs modules utilisateur et de performance soient combinés dans les deux hôtes. L'installation est un peu triviale au début. Par conséquent, nous partageons comment vous pouvez le configurer afin que vous puissiez avoir une base. Voir les détails ci-dessous pour l'exemple de processus d'installation :
[example@sqldat.com ~]# /usr/local/mariadb/columnstore/bin/postConfigure -d
This is the MariaDB ColumnStore System Configuration and Installation tool.
It will Configure the MariaDB ColumnStore System and will perform a Package
Installation of all of the Servers within the System that is being configured.
IMPORTANT: This tool requires to run on the Performance Module #1
Prompting instructions:
Press 'enter' to accept a value in (), if available or
Enter one of the options within [], if available, or
Enter a new value
===== Setup System Server Type Configuration =====
There are 2 options when configuring the System Server Type: single and multi
'single' - Single-Server install is used when there will only be 1 server configured
on the system. It can also be used for production systems, if the plan is
to stay single-server.
'multi' - Multi-Server install is used when you want to configure multiple servers now or
in the future. With Multi-Server install, you can still configure just 1 server
now and add on addition servers/modules in the future.
Select the type of System Server install [1=single, 2=multi] (2) >
===== Setup System Module Type Configuration =====
There are 2 options when configuring the System Module Type: separate and combined
'separate' - User and Performance functionality on separate servers.
'combined' - User and Performance functionality on the same server
Select the type of System Module Install [1=separate, 2=combined] (1) > 2
Combined Server Installation will be performed.
The Server will be configured as a Performance Module.
All MariaDB ColumnStore Processes will run on the Performance Modules.
NOTE: The MariaDB ColumnStore Schema Sync feature will replicate all of the
schemas and InnoDB tables across the User Module nodes. This feature can be enabled
or disabled, for example, if you wish to configure your own replication post installation.
MariaDB ColumnStore Schema Sync feature, do you want to enable? [y,n] (y) >
NOTE: MariaDB ColumnStore Replication Feature is enabled
Enter System Name (columnstore-1) >
===== Setup Storage Configuration =====
----- Setup Performance Module DBRoot Data Storage Mount Configuration -----
There are 2 options when configuring the storage: internal or external
'internal' - This is specified when a local disk is used for the DBRoot storage.
High Availability Server Failover is not Supported in this mode
'external' - This is specified when the DBRoot directories are mounted.
High Availability Server Failover is Supported in this mode.
Select the type of Data Storage [1=internal, 2=external] (1) >
===== Setup Memory Configuration =====
NOTE: Setting 'NumBlocksPct' to 50%
Setting 'TotalUmMemory' to 25%
===== Setup the Module Configuration =====
----- Performance Module Configuration -----
Enter number of Performance Modules [1,1024] (1) > 2
*** Parent OAM Module Performance Module #1 Configuration ***
Enter Nic Interface #1 Host Name (csnode1) >
Enter Nic Interface #1 IP Address or hostname of csnode1 (unassigned) > 192.168.2.10
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm1' (1) >
*** Performance Module #2 Configuration ***
Enter Nic Interface #1 Host Name (unassigned) > csnode2
Enter Nic Interface #1 IP Address or hostname of csnode2 (192.168.2.20) >
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm2' () >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm2' () > 2
===== Running the MariaDB ColumnStore MariaDB Server setup scripts =====
post-mysqld-install Successfully Completed
post-mysql-install Successfully Completed
Next step is to enter the password to access the other Servers.
This is either user password or you can default to using a ssh key
If using a user password, the password needs to be the same on all Servers.
Enter password, hit 'enter' to default to using a ssh key, or 'exit' >
===== System Installation =====
System Configuration is complete.
Performing System Installation.
Performing a MariaDB ColumnStore System install using RPM packages
located in the /root directory.
----- Performing Install on 'pm2 / csnode2' -----
Install log file is located here: /tmp/columnstore_tmp_files/pm2_rpm_install.log
MariaDB ColumnStore Package being installed, please wait ... DONE
===== Checking MariaDB ColumnStore System Logging Functionality =====
The MariaDB ColumnStore system logging is setup and working on local server
===== MariaDB ColumnStore System Startup =====
System Configuration is complete.
Performing System Installation.
----- Starting MariaDB ColumnStore on local server -----
MariaDB ColumnStore successfully started
MariaDB ColumnStore Database Platform Starting, please wait .......... DONE
System Catalog Successfully Created
Run MariaDB ColumnStore Replication Setup.. DONE
MariaDB ColumnStore Install Successfully Completed, System is Active
Enter the following command to define MariaDB ColumnStore Alias Commands
. /etc/profile.d/columnstoreAlias.sh
Enter 'mcsmysql' to access the MariaDB ColumnStore SQL console
Enter 'mcsadmin' to access the MariaDB ColumnStore Admin console
NOTE: The MariaDB ColumnStore Alias Commands are in /etc/profile.d/columnstoreAlias.sh
[example@sqldat.com ~]# . /etc/profile.d/columnstoreAlias.sh
[example@sqldat.com ~]#Une fois l'installation et la configuration terminées, MariaDB créera une configuration maître/esclave pour cela afin que tout ce que nous avons chargé à partir de csnode1 soit répliqué sur csnode2.
Vider vos mégadonnées
Après votre installation, vous n'aurez peut-être pas d'exemple de données à essayer. IMDB a partagé un échantillon de données que vous pouvez télécharger sur leur site https://www.imdb.com/interfaces/. Pour ce blog, j'ai créé un script qui fait tout pour vous. Découvrez-le ici https://github.com/paulnamuag/columnstore-imdb-data-load. Rendez-le simplement exécutable, puis exécutez le script. Il fera tout pour vous en téléchargeant les fichiers, en créant le schéma, puis en chargeant les données dans la base de données. C'est aussi simple que ça.
Exécuter vos exemples de requêtes
Essayons maintenant d'exécuter quelques exemples de requêtes.
MariaDB [imdb]> select count(1), 'title_akas' table_name from title_akas union all select count(1), 'name_basics' as table_name from name_basics union all select count(1), 'title_crew' as table_name from title_crew union all select count(1), 'title_episode' as table_name from title_episode union all select count(1), 'title_ratings' as table_name from title_ratings order by 1 asc;
+----------+---------------+
| count(1) | table_name |
+----------+---------------+
| 945057 | title_ratings |
| 3797618 | title_akas |
| 4136880 | title_episode |
| 5953930 | title_crew |
| 9403540 | name_basics |
+----------+---------------+
5 rows in set (0.162 sec)MariaDB [imdb]> select count(*), 'title_akas' table_name from title_akas union all select count(*), 'name_basics' as table_name from name_basics union all select count(*), 'title_crew' as table_name from title_crew union all select count(*), 'title_episode' as table_name from title_episode union all select count(*), 'title_ratings' as table_name from title_ratings order by 2;
+----------+---------------+
| count(*) | table_name |
+----------+---------------+
| 9405192 | name_basics |
| 3797618 | title_akas |
| 5953930 | title_crew |
| 4136880 | title_episode |
| 945057 | title_ratings |
+----------+---------------+
5 rows in set (0.371 sec)Fondamentalement, c'est plus rapide et plus rapide. Il existe des requêtes que vous ne pouvez pas traiter de la même manière que vous exécutez avec d'autres moteurs de stockage, tels qu'InnoDB. Par exemple, j'ai essayé de jouer et de faire quelques requêtes stupides et de voir comment il réagit et il en résulte :
MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select a.titleId from title_akas) limit 25;
ERROR 1815 (HY000): Internal error: IDB-1000: 'a' and 'title_akas' are not joined.Par conséquent, j'ai trouvé MCOL-1620 et MCOL-131 et cela pointe vers la définition de la variable infinidb_vtable_mode. Voir ci-dessous :
MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select c.titleId from title_akas c) limit 2;
ERROR 1815 (HY000): Internal error: IDB-1000: 'a' and 'b, sub-query' are not joined.Mais en définissant infinidb_vtable_mode=0 , ce qui signifie qu'il traite la requête comme un mode de traitement ligne par ligne générique et hautement compatible. Certains composants de la clause WHERE peuvent être traités par ColumnStore, mais les jointures sont entièrement traitées par mysqld en utilisant un mécanisme de jointure en boucle imbriquée. Voir ci-dessous :
MariaDB [imdb]> set infinidb_vtable_mode=0;
Query OK, 0 rows affected (0.000 sec)MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select c.titleId from title_akas c) limit 2;
+-----------+---------------+--------+-----------+-------------+---------------+
| titleId | title | region | id | primaryName | profession |
+-----------+---------------+--------+-----------+-------------+---------------+
| tt0082880 | Vaticano Show | ES | nm0594213 | Velda Mitzi | miscellaneous |
| tt0082880 | Il pap'occhio | IT | nm0594213 | Velda Mitzi | miscellaneous |
+-----------+---------------+--------+-----------+-------------+---------------+
2 rows in set (13.789 sec)Cela a pris un certain temps car il explique qu'il a été entièrement traité par mysqld. Pourtant, optimiser et écrire de bonnes requêtes reste la meilleure approche et ne pas tout déléguer à ColumnStore.
De plus, vous avez de l'aide pour analyser vos requêtes en exécutant des commandes telles que SELECT calSetTrace(1); ou SELECT calGetStats(); . Vous pouvez utiliser ces ensembles de commandes, par exemple, optimiser les requêtes basses et mauvaises ou afficher son plan de requête. Consultez-le ici pour plus de détails sur l'analyse des requêtes.
Administrer ColumnStore
Une fois que vous avez entièrement configuré MariaDB ColumnStore, il est livré avec son outil nommé mcsadmin pour lequel vous pouvez utiliser pour effectuer certaines tâches administratives. Vous pouvez également utiliser cet outil pour ajouter un autre module, affecter ou déplacer vers DBroots de PM à PM, etc. Consultez leur manuel à propos de cet outil.
Fondamentalement, vous pouvez effectuer les opérations suivantes, par exemple, vérifier les informations système :
mcsadmin> getSystemi
getsysteminfo Mon Jun 24 12:55:25 2019
System columnstore-1
System and Module statuses
Component Status Last Status Change
------------ -------------------------- ------------------------
System ACTIVE Fri Jun 21 21:40:56 2019
Module pm1 ACTIVE Fri Jun 21 21:40:54 2019
Module pm2 ACTIVE Fri Jun 21 21:40:50 2019
Active Parent OAM Performance Module is 'pm1'
Primary Front-End MariaDB ColumnStore Module is 'pm1'
MariaDB ColumnStore Replication Feature is enabled
MariaDB ColumnStore set for Distributed Install
MariaDB ColumnStore Process statuses
Process Module Status Last Status Change Process ID
------------------ ------ --------------- ------------------------ ----------
ProcessMonitor pm1 ACTIVE Thu Jun 20 17:36:27 2019 6026
ProcessManager pm1 ACTIVE Thu Jun 20 17:36:33 2019 6165
DBRMControllerNode pm1 ACTIVE Fri Jun 21 21:40:31 2019 19890
ServerMonitor pm1 ACTIVE Fri Jun 21 21:40:33 2019 19955
DBRMWorkerNode pm1 ACTIVE Fri Jun 21 21:40:33 2019 20003
PrimProc pm1 ACTIVE Fri Jun 21 21:40:37 2019 20137
ExeMgr pm1 ACTIVE Fri Jun 21 21:40:42 2019 20541
WriteEngineServer pm1 ACTIVE Fri Jun 21 21:40:47 2019 20660
DDLProc pm1 ACTIVE Fri Jun 21 21:40:51 2019 20810
DMLProc pm1 ACTIVE Fri Jun 21 21:40:55 2019 20956
mysqld pm1 ACTIVE Fri Jun 21 21:40:41 2019 19778
ProcessMonitor pm2 ACTIVE Thu Jun 20 17:37:16 2019 9728
ProcessManager pm2 HOT_STANDBY Fri Jun 21 21:40:26 2019 25211
DBRMControllerNode pm2 COLD_STANDBY Fri Jun 21 21:40:32 2019
ServerMonitor pm2 ACTIVE Fri Jun 21 21:40:35 2019 25560
DBRMWorkerNode pm2 ACTIVE Fri Jun 21 21:40:36 2019 25593
PrimProc pm2 ACTIVE Fri Jun 21 21:40:40 2019 25642
ExeMgr pm2 ACTIVE Fri Jun 21 21:40:44 2019 25715
WriteEngineServer pm2 ACTIVE Fri Jun 21 21:40:48 2019 25768
DDLProc pm2 COLD_STANDBY Fri Jun 21 21:40:50 2019
DMLProc pm2 COLD_STANDBY Fri Jun 21 21:40:50 2019
mysqld pm2 ACTIVE Fri Jun 21 21:40:32 2019 25467
Active Alarm Counts: Critical = 1, Major = 0, Minor = 0, Warning = 0, Info = 0Conclusion
MariaDB ColumnStore est un moteur de stockage très puissant pour votre traitement OLAP et Big Data. Ceci est entièrement open source, ce qui est très avantageux à utiliser que d'utiliser des bases de données OLAP propriétaires et coûteuses disponibles sur le marché. Pourtant, il existe d'autres alternatives à essayer telles que ClickHouse, Apache HBase ou cstore_fdw de Citus Data. Cependant, aucun d'entre eux n'utilise MySQL/MariaDB, ce n'est donc peut-être pas votre option viable si vous choisissez de vous en tenir aux variantes MySQL/MariaDB.