Pour exploiter efficacement une base de données, vous devez avoir un aperçu des performances de la base de données. Cela n'est peut-être pas évident lorsque tout va bien, mais dès que quelque chose ne va pas, l'accès à l'information peut être déterminant pour diagnostiquer rapidement et correctement le problème.
Toutes les bases de données mettent certaines de leurs données d'état internes à la disposition des utilisateurs. Dans MySQL, vous pouvez obtenir ces données principalement en exécutant "SHOW STATUS" et "SHOW GLOBAL STATUS", en exécutant "SHOW ENGINE INNODB STATUS", en vérifiant les tables information_schema et, dans les versions plus récentes, en interrogeant les tables performance_schema.

Ces méthodes sont loin d'être pratiques dans les opérations quotidiennes, d'où la popularité des différentes solutions de surveillance et de tendances. Des outils comme Nagios/Icinga sont conçus pour surveiller les hôtes/services et alerter lorsqu'un service tombe en dehors d'une plage acceptable. D'autres outils tels que Cacti et Munin fournissent un aperçu graphique des informations sur l'hôte/service et donnent un contexte historique aux performances et à l'utilisation. ClusterControl combine ces deux types de surveillance, nous allons donc examiner les informations qu'il présente et comment nous devons les interpréter.
Si vous utilisez Galera Cluster (MySQL Galera Cluster by Codership ou MariaDB Cluster ou Percona XtraDB Cluster), vous avez peut-être remarqué la section suivante dans l'onglet "Aperçu" de ClusterControl :
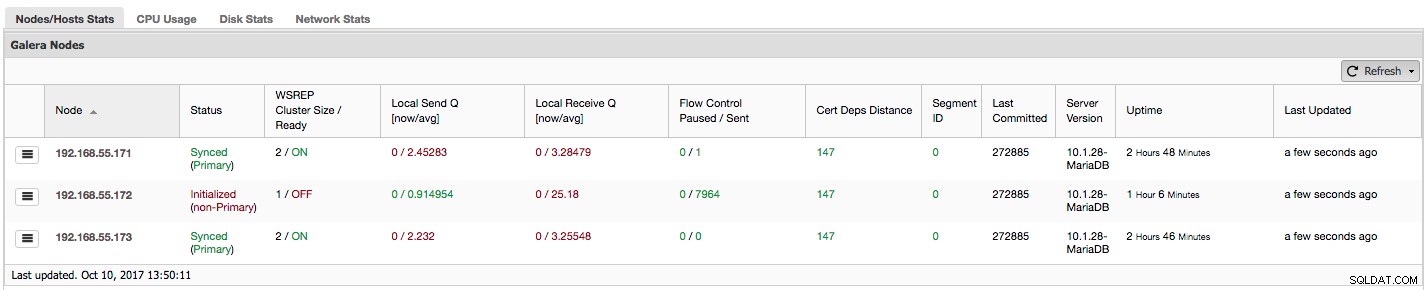
Voyons, étape par étape, quel type de données nous avons ici.
La première colonne contient la liste des nœuds avec leurs adresses IP - il n'y a pas grand-chose d'autre à dire à ce sujet.
La deuxième colonne est plus intéressante - elle décrit l'état du nœud (wsrep_local_state_comment statut). Un nœud peut être dans différents états :
- Initialisé :le nœud est opérationnel, mais il ne fait pas partie d'un cluster. Cela peut être causé, par exemple, par des problèmes de réseau ;
- Rejoindre :le nœud est en train de rejoindre le cluster et il reçoit ou demande un transfert d'état de l'un des autres nœuds ;
- Donateur/Désynchronisé :le nœud sert de donneur à un autre nœud qui rejoint le cluster ;
- Joined :le nœud est joint au cluster, mais il est occupé à rattraper les ensembles d'écriture validés ;
- Synchronisé :le nœud fonctionne normalement.
Dans la même colonne entre parenthèses se trouve l'état du cluster (wsrep_cluster_status statut). Il peut avoir trois états distincts :
- Primaire :la communication entre les nœuds fonctionne et le quorum est présent (la majorité des nœuds est disponible)
- Non primaire :le nœud faisait partie du cluster mais, pour une raison quelconque, il a perdu le contact avec le reste du cluster. Par conséquent, ce nœud est considéré comme inactif et n'accepte pas les requêtes
- Déconnecté :le nœud n'a pas pu établir de communication de groupe.
"WSREP Cluster Size / Ready" nous indique la taille d'un cluster tel que le nœud le voit et si le nœud est prêt à accepter les requêtes. Les composants non principaux créent un cluster avec une taille de 1 et la préparation wsrep est désactivée.
Jetons un coup d'œil à la capture d'écran ci-dessus et voyons ce qu'elle nous dit sur Galera. Nous pouvons voir trois nœuds. Deux d'entre eux (192.168.55.171 et 192.168.55.173) vont parfaitement bien, ils sont tous les deux "Synchronisés" et le cluster est à l'état "Primaire". Le cluster se compose actuellement de deux nœuds. Le nœud 192.168.55.172 est "initialisé" et il forme un composant "non principal". Cela signifie que ce nœud a perdu la connexion avec le cluster - très probablement une sorte de problèmes de réseau (en fait, nous avons utilisé iptables pour bloquer le trafic vers ce nœud à partir de 192.168.55.171 et 192.168.55.173).
À ce moment, nous devons nous arrêter un peu et décrire le fonctionnement interne de Galera Cluster. Nous n'entrerons pas dans trop de détails car cela n'entre pas dans le cadre de cet article de blog, mais certaines connaissances sont nécessaires pour comprendre l'importance des données présentées dans les colonnes suivantes.
Galera est un cluster multimaître "virtuellement" synchrone. Cela signifie que vous devez vous attendre à ce que les données soient transférées entre les nœuds "virtuellement" en même temps (plus de problèmes gênants avec les esclaves en retard) et que vous pouvez écrire sur n'importe quel nœud d'un cluster (plus de problèmes gênants avec la promotion d'un esclave à maître ). Pour ce faire, Galera utilise des jeux d'écriture - un ensemble atomique de modifications qui sont répliquées dans le cluster. Un jeu d'écriture peut contenir plusieurs modifications de ligne et des informations supplémentaires nécessaires telles que des données concernant le verrouillage.
Une fois qu'un client émet COMMIT, mais avant que MySQL ne valide quoi que ce soit, un jeu d'écriture est créé et envoyé à tous les nœuds du cluster pour certification. Tous les nœuds vérifient s'il est possible de valider les modifications ou non (car les modifications peuvent interférer avec d'autres écritures exécutées, entre-temps, directement sur un autre nœud). Si oui, les données sont effectivement validées par MySQL, sinon, la restauration est exécutée.
Ce qu'il est important de retenir, c'est le fait que les nœuds, similaires aux esclaves dans la réplication régulière, peuvent fonctionner différemment - certains peuvent avoir un meilleur matériel que d'autres, certains peuvent être plus chargés que d'autres. Pourtant, Galera leur demande de traiter les jeux d'écriture de manière courte et rapide, afin de maintenir une synchronisation "virtuelle". Il doit y avoir un mécanisme qui peut limiter la réplication et permettre aux nœuds plus lents de suivre le reste du cluster.
Examinons les colonnes "Local Send Q [now/avg]" et "Local Receive Q [now/avg]". Chaque nœud a une file d'attente locale pour envoyer et recevoir des jeux d'écriture. Il permet de paralléliser certaines des écritures et des données de file d'attente qui ne pourraient pas être traitées immédiatement si le nœud ne peut pas suivre le trafic. Dans SHOW GLOBAL STATUS, nous pouvons trouver huit compteurs décrivant les deux files d'attente, quatre compteurs par file d'attente :
- wsrep_local_send_queue - état actuel de la file d'envoi
- wsrep_local_send_queue_min - minimum depuis FLUSH STATUS
- wsrep_local_send_queue_max - maximum depuis FLUSH STATUS
- wsrep_local_send_queue_avg - moyenne depuis FLUSH STATUS
- wsrep_local_recv_queue - état actuel de la file d'attente de réception
- wsrep_local_recv_queue_min - minimum depuis FLUSH STATUS
- wsrep_local_recv_queue_max - maximum depuis FLUSH STATUS
- wsrep_local_recv_queue_avg - moyenne depuis FLUSH STATUS
Les métriques ci-dessus sont unifiées sur tous les nœuds sous ClusterControl -> Performances -> État de la base de données :
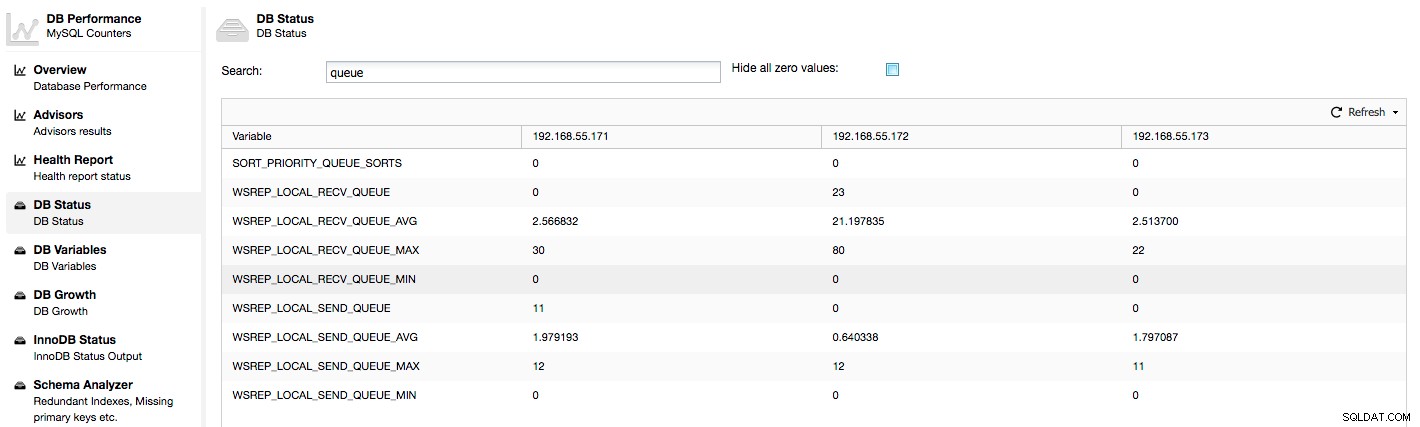
ClusterControl affiche les compteurs "maintenant" et "moyen", car ils sont les plus significatifs en tant que nombre unique (vous pouvez également créer des graphiques personnalisés basés sur des variables décrivant l'état actuel des files d'attente). Lorsque nous voyons que l'une des files d'attente augmente, cela signifie que le nœud ne peut pas suivre la réplication et que les autres nœuds devront ralentir pour lui permettre de rattraper son retard. Nous vous recommandons d'étudier une charge de travail de ce nœud donné - vérifiez la liste des processus pour certaines requêtes de longue durée, vérifiez les statistiques du système d'exploitation telles que l'utilisation du processeur et la charge de travail des E/S. Peut-être est-il également possible de redistribuer une partie du trafic de ce nœud vers le reste du cluster.
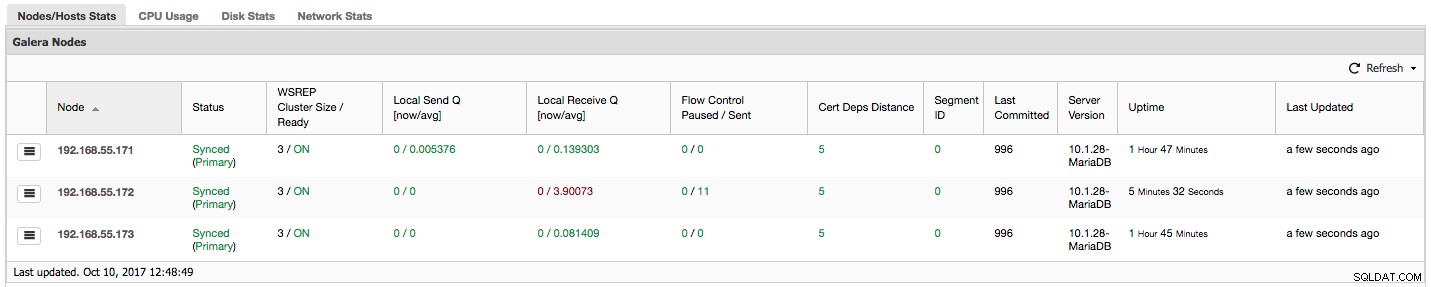
"Flow Control Paused" affiche des informations sur le pourcentage de temps qu'un nœud donné a dû mettre en pause sa réplication en raison d'une charge trop lourde. Lorsqu'un nœud ne peut pas suivre la charge de travail, il envoie des paquets de contrôle de flux à d'autres nœuds, les informant qu'ils doivent ralentir l'envoi de jeux d'écriture. Dans notre capture d'écran, nous avons une valeur de "0,30" pour le nœud 192.168.55.172. Cela signifie que près de 30 % du temps, ce nœud a dû interrompre la réplication car il n'était pas en mesure de suivre le taux de certification du jeu d'écriture requis par les autres nœuds (ou plus simplement, trop d'écritures l'ont atteint !). Comme nous pouvons le voir, c'est "Local Receive Q [avg]" qui nous indique également ce fait.
La colonne suivante, "Flow Control Sent" nous donne des informations sur le nombre de paquets de contrôle de flux qu'un nœud donné a envoyés au cluster. Encore une fois, nous voyons que c'est le nœud 192.168.55.172 qui ralentit le cluster.
Que pouvons-nous faire avec ces informations ? Surtout, nous devrions enquêter sur ce qui se passe dans le nœud lent. Vérifiez l'utilisation du processeur, vérifiez les performances d'E/S et les statistiques du réseau. Cette première étape permet d'évaluer le type de problème auquel nous sommes confrontés.
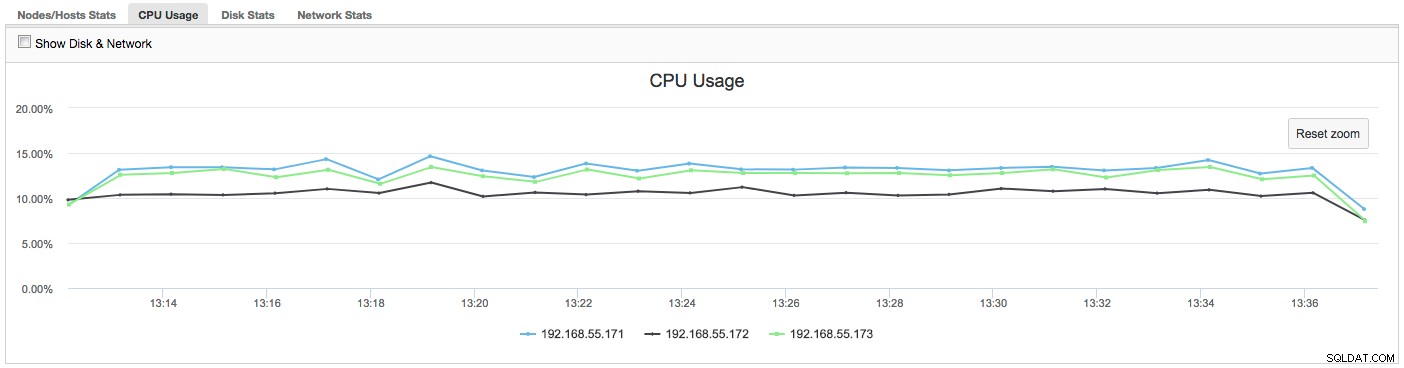
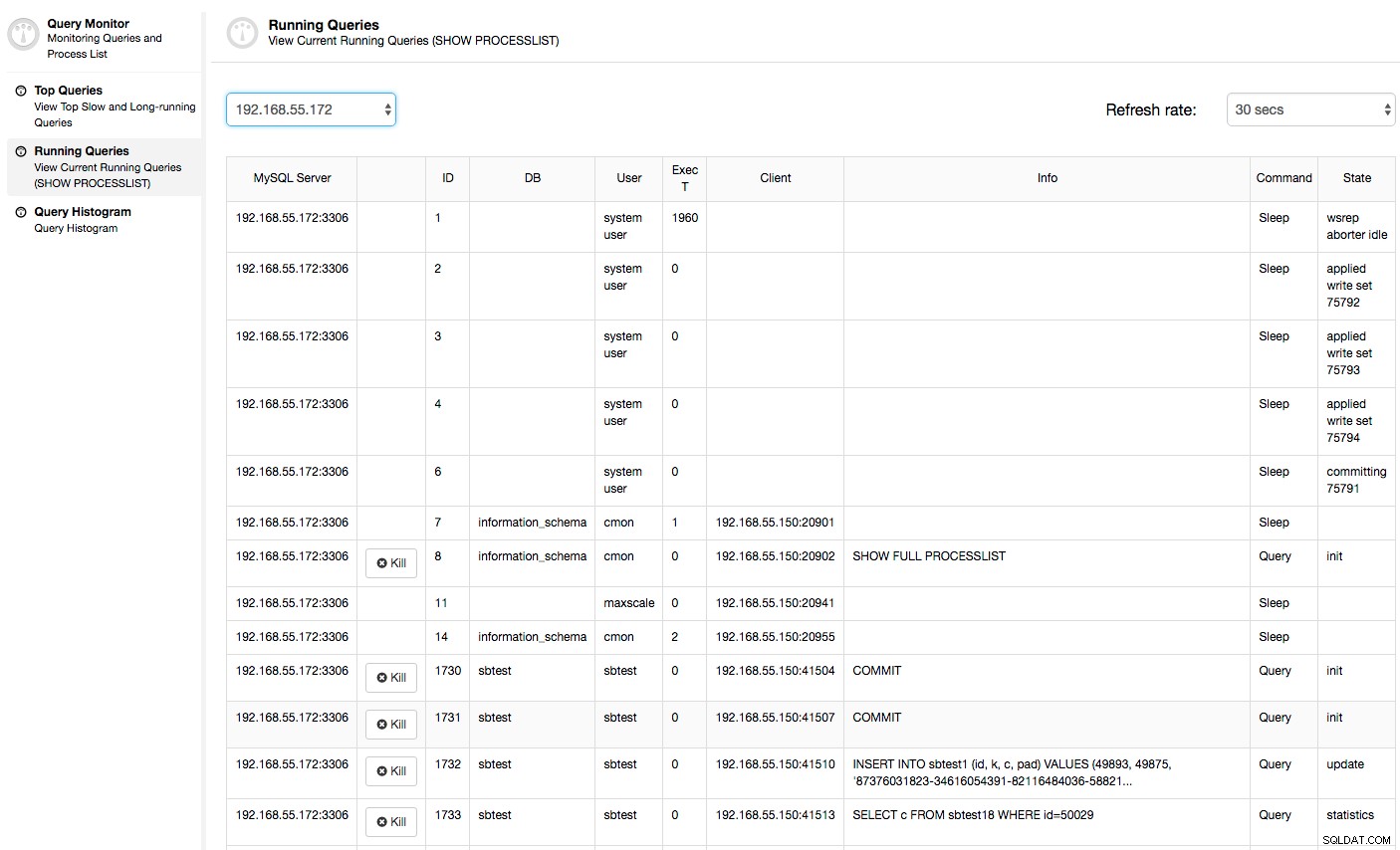
Dans ce cas, une fois que nous passons à l'onglet Utilisation du processeur, il devient clair que l'utilisation intensive du processeur est à l'origine de nos problèmes. La prochaine étape serait d'identifier le coupable en regardant dans PROCESSLIST (Moniteur de requête -> Requêtes en cours d'exécution -> filtrer par 192.168.55.172) pour vérifier les requêtes incriminées :
Ou, vérifiez les processus sur le nœud du côté du système d'exploitation (Nodes -> 192.168.55.172 -> Top) pour voir si la charge n'est pas causée par quelque chose en dehors de Galera/MySQL.
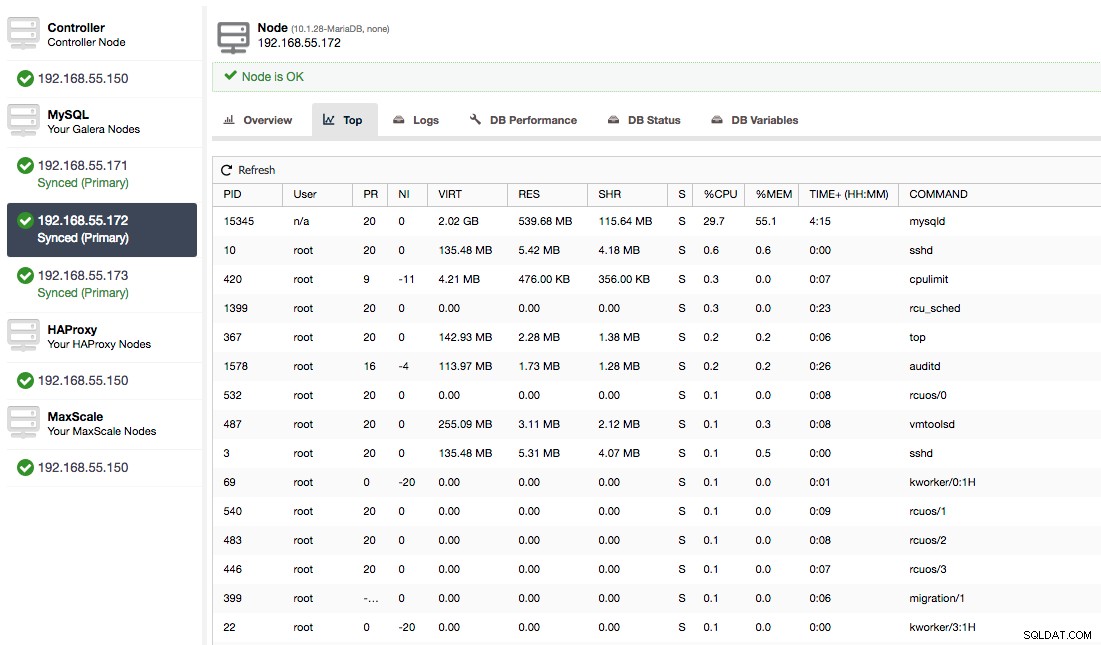
Dans ce cas, nous avons exécuté la commande mysqld via cpulimit, pour simuler une utilisation lente du processeur spécifiquement pour le processus mysqld en le limitant à 30 % sur 400 % du processeur disponible (le serveur a 4 cœurs).
La colonne "Cert Deps Distance" nous donne des informations sur le nombre de jeux d'écriture, en moyenne, qui peuvent être appliqués en parallèle. Les jeux d'écriture peuvent parfois être exécutés en même temps - Galera en profite en utilisant plusieurs wsrep_slave_threads pour appliquer des jeux d'écriture. Cette colonne vous donne une idée du nombre de threads esclaves que vous pourriez utiliser sur votre charge de travail. Il convient de noter qu'il est inutile de configurer wsrep_slave_threads variable à des valeurs supérieures à celles que vous voyez dans cette colonne ou dans wsrep_cert_deps_distance variable d'état, sur laquelle la colonne "Cert Deps Distance" est basée. Une autre remarque importante :il est également inutile de définir wsrep_slave_threads variable à plus que le nombre de cœurs de votre CPU.
"ID de segment" - cette colonne nécessitera plus d'explications. Les segments sont une nouvelle fonctionnalité ajoutée dans Galera 3.0. Avant cette version, les jeux d'écriture étaient échangés entre tous les nœuds. Disons que nous avons deux centres de données :
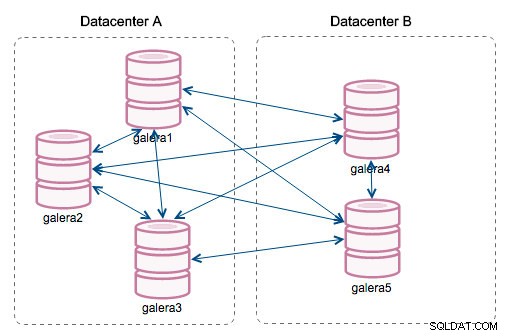
Ce type de bavardage fonctionne bien sur les réseaux locaux, mais le WAN est une autre histoire - la certification ralentit en raison de la latence accrue, des coûts supplémentaires sont générés en raison de la bande passante réseau utilisée pour transférer les jeux d'écriture entre chaque membre du cluster.
Avec l'introduction des "Segments", les choses ont changé. Vous pouvez affecter un nœud à un segment en modifiant wsrep_provider_options variable et en y ajoutant "gmcast.segment=x" (0, 1, 2). Les nœuds avec le même numéro de segment sont traités comme s'ils se trouvaient dans le même centre de données, connectés par un réseau local. Notre graphique devient alors différent :
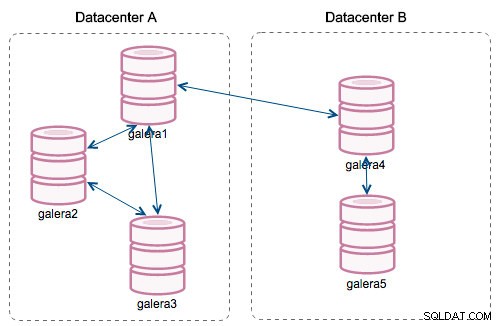
La principale différence est qu'il n'y a plus de communication de tout le monde à tout le monde. Au sein de chaque segment, oui - c'est toujours le même mécanisme mais les deux segments ne communiquent que par une seule connexion entre deux nœuds choisis. En cas d'indisponibilité, cette connexion basculera automatiquement. En conséquence, nous obtenons moins de bavardages sur le réseau et moins d'utilisation de la bande passante entre les centres de données distants. Donc, en gros, la colonne "ID de segment" nous indique à quel segment un nœud est affecté.
La colonne "Last Committed" nous donne des informations sur le numéro de séquence du jeu d'écriture qui a été exécuté en dernier sur un nœud donné. Cela peut être utile pour déterminer quel nœud est le plus récent s'il est nécessaire d'amorcer le cluster.
Le reste des colonnes est explicite :version du serveur, disponibilité d'un nœud et date de mise à jour de l'état.
Comme vous pouvez le voir, la section "Nœuds Galera" des "Statistiques des nœuds/hôtes" dans l'onglet "Vue d'ensemble" vous donne une assez bonne compréhension de la santé du cluster - s'il forme un composant "Primaire", combien de nœuds sont sains , y a-t-il des problèmes de performances avec certains nœuds et si oui, quel nœud ralentit le cluster.
Cet ensemble de données est très pratique lorsque vous exploitez votre cluster Galera, alors j'espère que vous ne volerez plus à l'aveuglette :-)