Le schéma de base de données n'est pas quelque chose d'immuable. Il est conçu pour une application donnée, mais les exigences peuvent changer et changent généralement. De nouveaux modules et fonctionnalités sont ajoutés à l'application, davantage de données sont collectées, une refactorisation du code et du modèle de données est effectuée. D'où la nécessité de modifier le schéma de la base de données pour s'adapter à ces changements; ajouter ou modifier des colonnes, créer de nouvelles tables ou en partitionner de grandes. Les requêtes changent également à mesure que les développeurs ajoutent de nouvelles façons pour les utilisateurs d'interagir avec les données - de nouvelles requêtes pourraient utiliser de nouveaux index plus efficaces, nous nous précipitons donc pour les créer afin de fournir à l'application les meilleures performances de base de données.
Alors, comment aborder au mieux un changement de schéma ? Quels outils sont utiles ? Comment minimiser l'impact sur une base de production ? Quels sont les problèmes les plus courants liés à la conception de schéma ? Quels outils peuvent vous aider à rester au top de votre schéma ? Dans cet article de blog, nous vous donnerons un bref aperçu de la façon de modifier le schéma dans MySQL et MariaDB. Veuillez noter que nous ne discuterons pas des changements de schéma dans le contexte de Galera Cluster. Nous avons déjà discuté de l'isolement total des commandes, des mises à niveau du schéma de roulement et des conseils pour minimiser l'impact du RSU dans les articles de blog précédents. Nous aborderons également des trucs et astuces liés à la conception de schémas et comment ClusterControl peut vous aider à rester au courant de toutes les modifications de schéma.
Types de modifications de schéma
Tout d'abord. Avant d'approfondir le sujet, nous devons comprendre comment MySQL et MariaDB effectuent les changements de schéma. Vous voyez, un changement de schéma n'est pas égal à un autre changement de schéma.
Vous avez peut-être entendu parler des modifications en ligne, des modifications instantanées ou des modifications sur place. Tout cela est le résultat d'un travail en cours pour minimiser l'impact des changements de schéma sur la base de données de production. Historiquement, presque tous les changements de schéma étaient bloquants. Si vous avez exécuté un changement de schéma, toutes les requêtes commenceront à s'accumuler, attendant que ALTER se termine. Évidemment, cela posait de sérieux problèmes pour les déploiements en production. Bien sûr, les gens commencent immédiatement à chercher des solutions de contournement, et nous en discuterons plus tard dans ce blog, car même aujourd'hui, celles-ci sont toujours pertinentes. Mais aussi, des travaux ont commencé pour améliorer la capacité de MySQL à exécuter DDL (Data Definition Language) sans trop d'impact sur les autres requêtes.
Modifications instantanées
Parfois, il n'est pas nécessaire de toucher aux données du tablespace, car tout ce qui doit être changé, ce sont les métadonnées. Un exemple ici sera de supprimer un index ou de renommer une colonne. Ces opérations sont rapides et efficaces. Généralement, leur impact est limité. Ce n'est pourtant pas sans impact. Parfois, il faut quelques secondes pour effectuer la modification des métadonnées et une telle modification nécessite l'acquisition d'un verrou de métadonnées. Ce verrou est sur une base par table, et il peut bloquer d'autres opérations qui doivent être exécutées sur cette table. Vous verrez cela comme des entrées "En attente du verrouillage des métadonnées de la table" dans la liste des processus.
Un exemple d'un tel changement peut être ADD COLUMN instantané, introduit dans MariaDB 10.3 et MySQL 8.0. Il donne la possibilité d'exécuter ce changement de schéma assez populaire sans aucun délai. MariaDB et Oracle ont décidé d'inclure le code de Tencent Game qui permet d'ajouter instantanément une nouvelle colonne au tableau. C'est sous certaines conditions spécifiques; la colonne doit être ajoutée en dernier, les index de texte intégral ne peuvent pas exister dans la table, le format de ligne ne peut pas être compressé - vous pouvez trouver plus d'informations sur le fonctionnement de la colonne d'ajout instantané dans la documentation MariaDB. Pour MySQL, la seule référence officielle se trouve sur le blog mysqlserverteam.com, bien qu'un bug existe pour mettre à jour la documentation officielle.
Modifications en place
Certaines des modifications nécessitent la modification des données dans l'espace de table. De telles modifications peuvent être effectuées sur les données elles-mêmes, et il n'est pas nécessaire de créer une table temporaire avec une nouvelle structure de données. De tels changements permettent généralement (mais pas toujours) d'exécuter d'autres requêtes touchant la table pendant que le changement de schéma est en cours d'exécution. Un exemple d'une telle opération consiste à ajouter un nouvel index secondaire à la table. Cette opération prendra un certain temps mais permettra l'exécution de DML.
Reconstruire le tableau
S'il n'est pas possible d'apporter une modification sur place, InnoDB créera une table temporaire avec la nouvelle structure souhaitée. Il copiera ensuite les données existantes dans la nouvelle table. Cette opération est la plus coûteuse et il est probable (bien que cela ne se produise pas toujours) de verrouiller les DML. Par conséquent, un tel changement de schéma est très difficile à exécuter sur une grande table sur un serveur autonome, sans l'aide d'outils externes - généralement, vous ne pouvez pas vous permettre de verrouiller votre base de données pendant de longues minutes, voire des heures. Un exemple d'une telle opération serait de changer le type de données de la colonne, par exemple de INT à VARCHAR.
Modifications de schéma et réplication
Ok, nous savons donc qu'InnoDB autorise les changements de schéma en ligne et si nous consultons la documentation de MySQL, nous verrons que la majorité des changements de schéma (du moins parmi les plus courants) peuvent être effectués en ligne. Quelle est la raison de consacrer des heures de développement à créer des outils de changement de schéma en ligne comme gh-ost ? Nous pouvons accepter que pt-online-schema-change soit un vestige de l'ancien mauvais temps, mais gh-ost est un nouveau logiciel.
La réponse est complexe. Il y a deux problèmes principaux.
Pour commencer, une fois que vous avez commencé un changement de schéma, vous n'avez aucun contrôle dessus. Vous pouvez l'interrompre mais vous ne pouvez pas le mettre en pause. Vous ne pouvez pas l'étrangler. Comme vous pouvez l'imaginer, la reconstruction de la table est une opération coûteuse et même si InnoDB autorise l'exécution de DML, la charge de travail d'E/S supplémentaire du DDL affecte toutes les autres requêtes et il n'y a aucun moyen de limiter cet impact à un niveau acceptable pour le application.
Deuxièmement, un problème encore plus grave est la réplication. Si vous exécutez une opération non bloquante, qui nécessite une reconstruction de table, cela ne verrouillera en effet pas les DML, mais cela n'est vrai que sur le maître. Supposons qu'un tel DDL ait pris 30 minutes - la vitesse d'ALTER dépend du matériel mais il est assez courant de voir de tels temps d'exécution sur des tables d'une taille de 20 Go. Il est ensuite répliqué sur tous les esclaves et, à partir du moment où DDL démarre sur ces esclaves, la réplication attendra qu'il se termine. Peu importe si vous utilisez MySQL ou MariaDB, ou si vous avez une réplication multithread. Les esclaves seront en retard - ils attendront ces 30 minutes que le DDL se termine avant de commencer à appliquer les événements binlog restants. Comme vous pouvez l'imaginer, 30 minutes de décalage (parfois même 30 secondes ne seront pas acceptables - tout dépend de l'application) est quelque chose qui rend impossible l'utilisation de ces esclaves pour le scale-out. Bien sûr, il existe des solutions de contournement - vous pouvez effectuer des modifications de schéma du bas vers le haut de la chaîne de réplication, mais cela limite sérieusement vos options. Surtout si vous utilisez la réplication basée sur les lignes, vous ne pouvez exécuter que des modifications de schéma compatibles de cette manière. Quelques exemples de limitations de la réplication basée sur les lignes ; vous ne pouvez pas supprimer une colonne qui n'est pas la dernière, vous ne pouvez pas ajouter une colonne à une position autre que la dernière. Vous ne pouvez pas également modifier le type de colonne (par exemple, INT -> VARCHAR).
Comme vous pouvez le constater, la réplication ajoute de la complexité à la façon dont vous pouvez effectuer des modifications de schéma. Les opérations qui ne sont pas bloquantes sur l'hôte autonome deviennent bloquantes lorsqu'elles sont exécutées sur des esclaves. Examinons quelques méthodes que vous pouvez utiliser pour minimiser l'impact des modifications de schéma.
Outils de modification de schéma en ligne
Comme nous l'avons mentionné précédemment, il existe des outils destinés à effectuer des modifications de schéma. Les plus populaires sont pt-online-schema-change créé par Percona et gh-ost, créé par GitHub. Dans une série d'articles de blog, nous les avons comparés et avons expliqué comment gh-ost peut être utilisé pour effectuer des modifications de schéma et comment vous pouvez limiter et reconfigurer une migration en cours. Ici, nous n'entrerons pas dans les détails, mais nous aimerions tout de même mentionner certains des aspects les plus importants de l'utilisation de ces outils. Pour commencer, un changement de schéma exécuté via pt-osc ou gh-ost se produira sur tous les nœuds de base de données à la fois. Il n'y a aucun délai quant au moment où le changement sera appliqué. Cela permet d'utiliser ces outils même pour les modifications de schéma incompatibles avec la réplication basée sur les lignes. Les mécanismes exacts sur la façon dont ces outils suivent les changements sur la table sont différents (déclencheurs dans pt-osc vs analyse binlog dans gh-ost) mais l'idée principale est la même - une nouvelle table est créée avec le schéma souhaité et les données existantes sont copié de l'ancien tableau. En attendant, les DML sont suivis (d'une manière ou d'une autre) et appliqués à la nouvelle table. Une fois toutes les données migrées, les tables sont renommées et la nouvelle table remplace l'ancienne. Il s'agit d'une opération atomique, elle n'est donc pas visible pour l'application. Les deux outils ont une option pour limiter la charge et suspendre les opérations. Gh-ost peut arrêter toute l'activité, pt-osc ne peut arrêter que le processus de copie des données entre l'ancienne et la nouvelle table - les déclencheurs resteront actifs et ils continueront à dupliquer les données, ce qui ajoute une surcharge. En raison de la table de renommage, les deux outils ont certaines limitations concernant les clés étrangères - non pris en charge par gh-ost, partiellement pris en charge par pt-osc soit via ALTER normal, ce qui peut entraîner un retard de réplication (impossible si la table enfant est grande) ou par supprimer l'ancienne table avant de renommer la nouvelle - c'est dangereux car il n'y a aucun moyen de revenir en arrière si, pour une raison quelconque, les données n'ont pas été correctement copiées dans la nouvelle table. Les déclencheurs sont également difficiles à prendre en charge.
Ils ne sont pas pris en charge dans gh-ost, pt-osc dans MySQL 5.7 et les versions plus récentes ont une prise en charge limitée des tables avec des déclencheurs existants. D'autres limitations importantes pour les outils de changement de schéma en ligne sont que la clé unique ou primaire doit exister dans la table. Il est utilisé pour identifier les lignes à copier entre les anciennes et les nouvelles tables. Ces outils sont également beaucoup plus lents que ALTER direct - un changement qui prend des heures lors de l'exécution d'ALTER peut prendre des jours lorsqu'il est effectué à l'aide de pt-osc ou gh-ost.
D'autre part, comme nous l'avons mentionné, tant que les exigences sont satisfaites et que les limitations n'entrent pas en jeu, vous pouvez exécuter tous les changements de schéma en utilisant l'un des outils. Tout se passera en même temps sur tous les hôtes, vous n'avez donc pas à vous soucier de la compatibilité. Vous avez également un certain niveau de contrôle sur la façon dont le processus est exécuté (moins dans pt-osc, beaucoup plus dans gh-ost).
Vous pouvez réduire l'impact du changement de schéma, vous pouvez les mettre en pause et les laisser s'exécuter uniquement sous supervision, vous pouvez tester le changement avant de l'effectuer réellement. Vous pouvez leur demander de suivre le décalage de réplication et de faire une pause si un impact est détecté. Cela fait de ces outils un très bon ajout à l'arsenal du DBA tout en travaillant avec la réplication MySQL.
Changements de schéma glissants
Généralement, un administrateur de base de données utilise l'un des outils de modification de schéma en ligne. Mais comme nous en avons discuté précédemment, dans certaines circonstances, ils ne peuvent pas être utilisés et une modification directe est la seule option viable. Si nous parlons de MySQL autonome, vous n'avez pas le choix - si le changement n'est pas bloquant, c'est bien. Si ce n'est pas le cas, eh bien, vous ne pouvez rien y faire. Mais alors, peu de gens utilisent MySQL en tant qu'instance unique, n'est-ce pas ? Qu'en est-il de la réplication ? Comme nous en avons discuté précédemment, une modification directe sur le maître n'est pas réalisable - la plupart des cas, cela entraînera un décalage sur l'esclave et cela peut ne pas être acceptable. Ce qui peut être fait, cependant, est d'exécuter le changement de manière progressive. Vous pouvez commencer avec des esclaves et, une fois le changement appliqué sur chacun d'eux, promouvoir l'un des esclaves en tant que nouveau maître, rétrograder l'ancien maître en esclave et exécuter le changement sur celui-ci. Bien sûr, le changement doit être compatible mais, à vrai dire, les cas les plus courants où vous ne pouvez pas utiliser les changements de schéma en ligne sont dus à un manque de clé primaire ou unique. Pour tous les autres cas, il existe une sorte de solution de contournement, en particulier dans pt-online-schema-change car gh-ost a des limitations plus strictes. C'est une solution de contournement que vous appelleriez "donc" ou "loin d'être idéale", mais elle fera l'affaire si vous n'avez pas d'autre option à choisir. Ce qui est également important, la plupart des limitations peuvent être évitées si vous surveillez votre schéma et détectez les problèmes avant que la table ne grandisse. Même si quelqu'un crée une table sans clé primaire, ce n'est pas un problème d'exécuter une modification directe qui prend une demi-seconde ou moins, car la table est presque vide.
S'il se développe, cela deviendra un problème sérieux, mais il appartient au DBA de détecter ce type de problèmes avant qu'ils ne commencent à créer des problèmes. Nous couvrirons quelques trucs et astuces sur la façon de vous assurer que vous détecterez ces problèmes à temps. Nous partagerons également des conseils génériques sur la façon de concevoir vos schémas.
Conseils et astuces
Conception de schéma
Comme nous l'avons montré dans cet article, les outils de modification de schéma en ligne sont très importants lorsque vous travaillez avec une configuration de réplication. Il est donc très important de vous assurer que votre schéma est conçu de manière à ne pas limiter vos options pour effectuer des modifications de schéma. Il y a trois aspects importants. Tout d'abord, la clé primaire ou unique doit exister - vous devez vous assurer qu'il n'y a pas de tables sans clé primaire dans votre base de données. Vous devez surveiller cela régulièrement, sinon cela pourrait devenir un problème sérieux à l'avenir. Deuxièmement, vous devriez sérieusement vous demander si l'utilisation de clés étrangères est une bonne idée. Bien sûr, ils ont leurs utilisations, mais ils ajoutent également des frais généraux à votre base de données et ils peuvent rendre problématique l'utilisation d'outils de changement de schéma en ligne. Les relations peuvent être imposées par l'application. Même si cela signifie plus de travail, cela peut toujours être une meilleure idée que de commencer à utiliser des clés étrangères et d'être sévèrement limité aux types de modifications de schéma qui peuvent être effectuées. Troisièmement, les déclencheurs. Même histoire que pour les clés étrangères. Ils sont une fonctionnalité intéressante à avoir, mais ils peuvent devenir un fardeau. Vous devez sérieusement vous demander si les gains de leur utilisation l'emportent sur les limitations qu'ils posent.
Suivi des modifications de schéma
La gestion des changements de schéma ne consiste pas seulement à exécuter des changements de schéma. Vous devez également rester au top de la structure de votre schéma, surtout si vous n'êtes pas le seul à effectuer les modifications.
ClusterControl fournit aux utilisateurs des outils pour suivre certains des problèmes de conception de schéma les plus courants. Cela peut vous aider à suivre les tables qui n'ont pas de clés primaires :
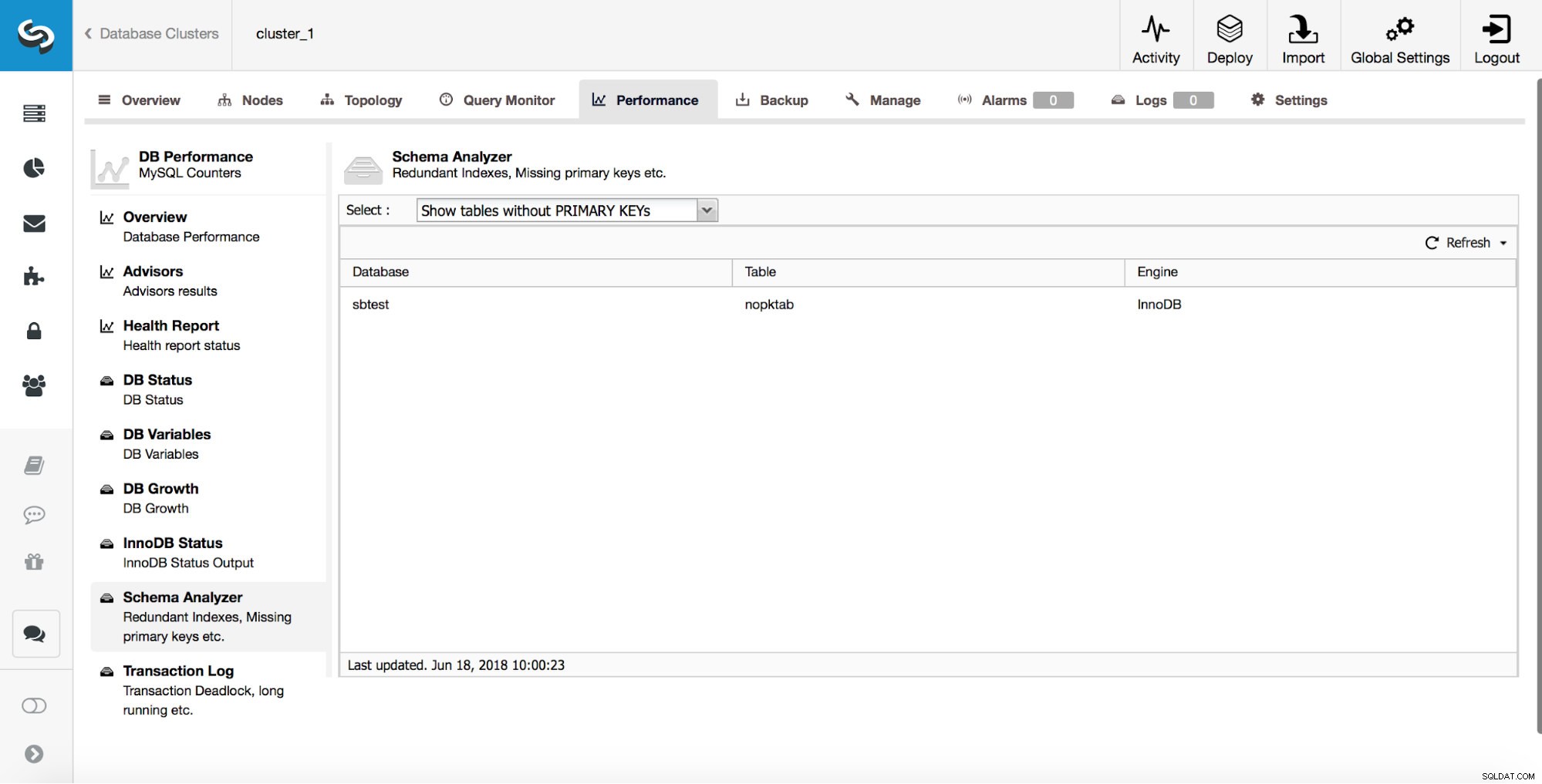
Comme nous en avons discuté précédemment, il est très important d'attraper ces tables tôt car les clés primaires doivent être ajoutées à l'aide de la modification directe.
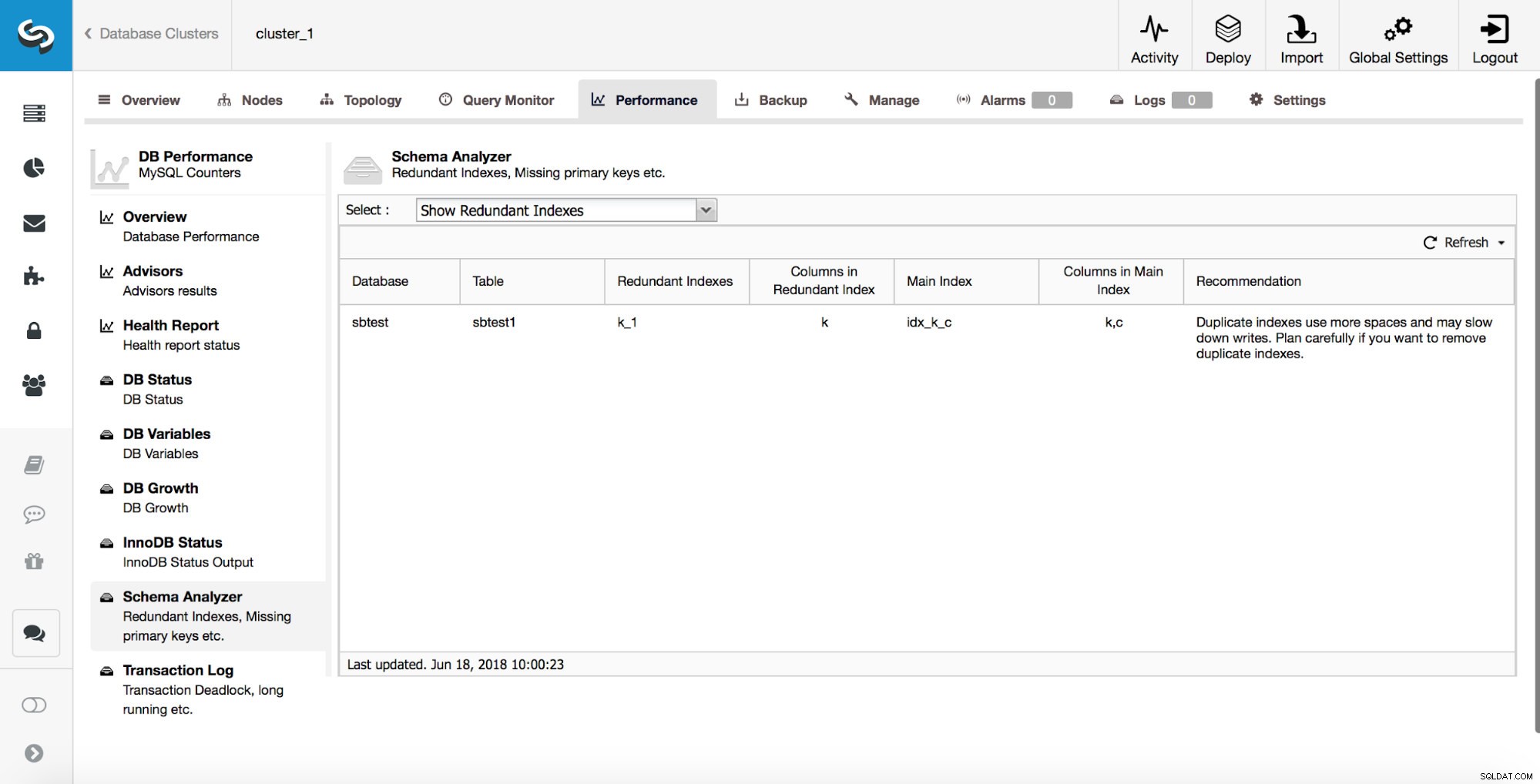
ClusterControl peut également vous aider à suivre les index en double. En règle générale, vous ne souhaitez pas avoir plusieurs index redondants. Dans l'exemple ci-dessus, vous pouvez voir qu'il y a un index sur (k, c) et il y a aussi un index sur (k). Toute requête pouvant utiliser un index créé sur la colonne "k" peut également utiliser un index composite créé sur les colonnes (k, c). Il y a des cas où il est avantageux de conserver des index redondants mais il faut l'aborder au cas par cas. A partir de MySQL 8.0, il est possible de tester rapidement si un index est vraiment nécessaire ou non. Vous pouvez rendre un index redondant "invisible" en exécutant :
ALTER TABLE sbtest.sbtest1 ALTER INDEX k_1 INVISIBLE;Cela obligera MySQL à ignorer cet index et, grâce à la surveillance, vous pourrez vérifier s'il y a eu un impact négatif sur les performances de la base de données. Si tout fonctionne comme prévu pendant un certain temps (quelques jours ou même semaines), vous pouvez prévoir de supprimer l'index redondant. Si vous détectez que quelque chose ne va pas, vous pouvez toujours réactiver cet index en exécutant :
ALTER TABLE sbtest.sbtest1 ALTER INDEX k_1 VISIBLE;Ces opérations sont instantanées et l'index est là tout le temps, et est toujours maintenu - c'est seulement qu'il ne sera pas pris en considération par l'optimiseur. Grâce à cette option, la suppression des index dans MySQL 8.0 sera une opération beaucoup plus sûre. Dans les versions précédentes, rajouter un index supprimé par erreur pouvait prendre des heures, voire des jours sur de grandes tables.
ClusterControl peut également vous informer sur les tables MyISAM.
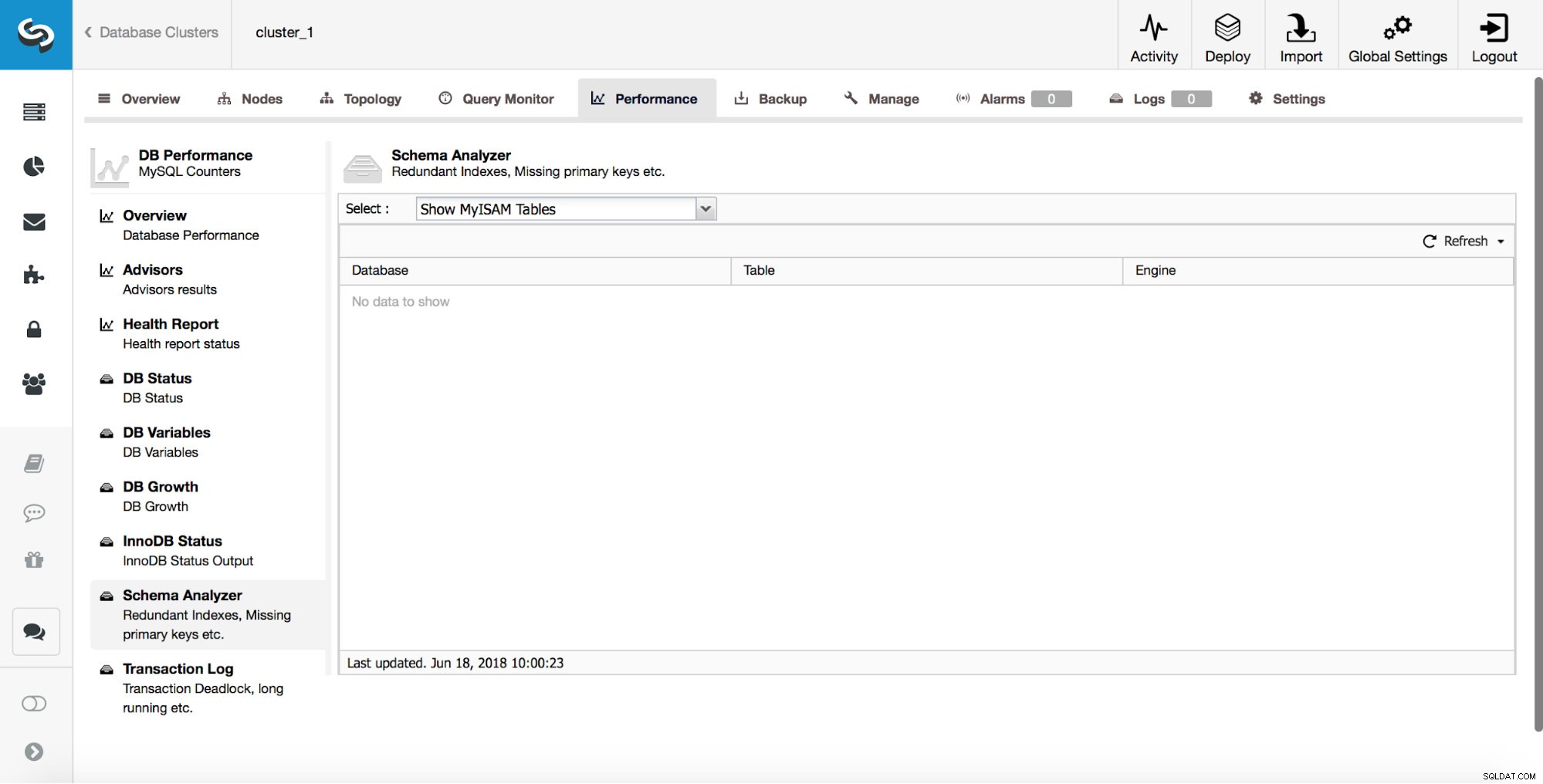
Bien que MyISAM puisse encore avoir ses utilisations, vous devez garder à l'esprit qu'il ne s'agit pas d'un moteur de stockage transactionnel. En tant que tel, il peut facilement introduire une incohérence des données entre les nœuds dans une configuration de réplication.
Une autre fonctionnalité très utile de ClusterControl est l'un des rapports opérationnels - un rapport de changement de schéma.
Dans un monde idéal, un administrateur de base de données examine, approuve et implémente toutes les modifications de schéma. Malheureusement, ce n'est pas toujours le cas. Un tel processus de révision ne va tout simplement pas bien avec le développement agile. En plus de cela, le ratio développeur / DBA est généralement assez élevé, ce qui peut également devenir un problème car les DBA auraient du mal à ne pas devenir un goulot d'étranglement. C'est pourquoi il n'est pas rare de voir des changements de schéma effectués en dehors des connaissances du DBA. Pourtant, le DBA est généralement celui qui est responsable des performances et de la stabilité de la base de données. Grâce au rapport de modification de schéma, ils peuvent désormais suivre les modifications de schéma.
Au début, une configuration est nécessaire. Dans un fichier de configuration pour un cluster donné (/etc/cmon.d/cmon_X.cnf), vous devez définir sur quel hôte ClusterControl doit suivre les changements et quels schémas doivent être vérifiés.
schema_change_detection_address=10.0.0.126
schema_change_detection_databases=sbtestUne fois cela fait, vous pouvez planifier l'exécution régulière d'un rapport. Un exemple de sortie peut être comme ci-dessous :
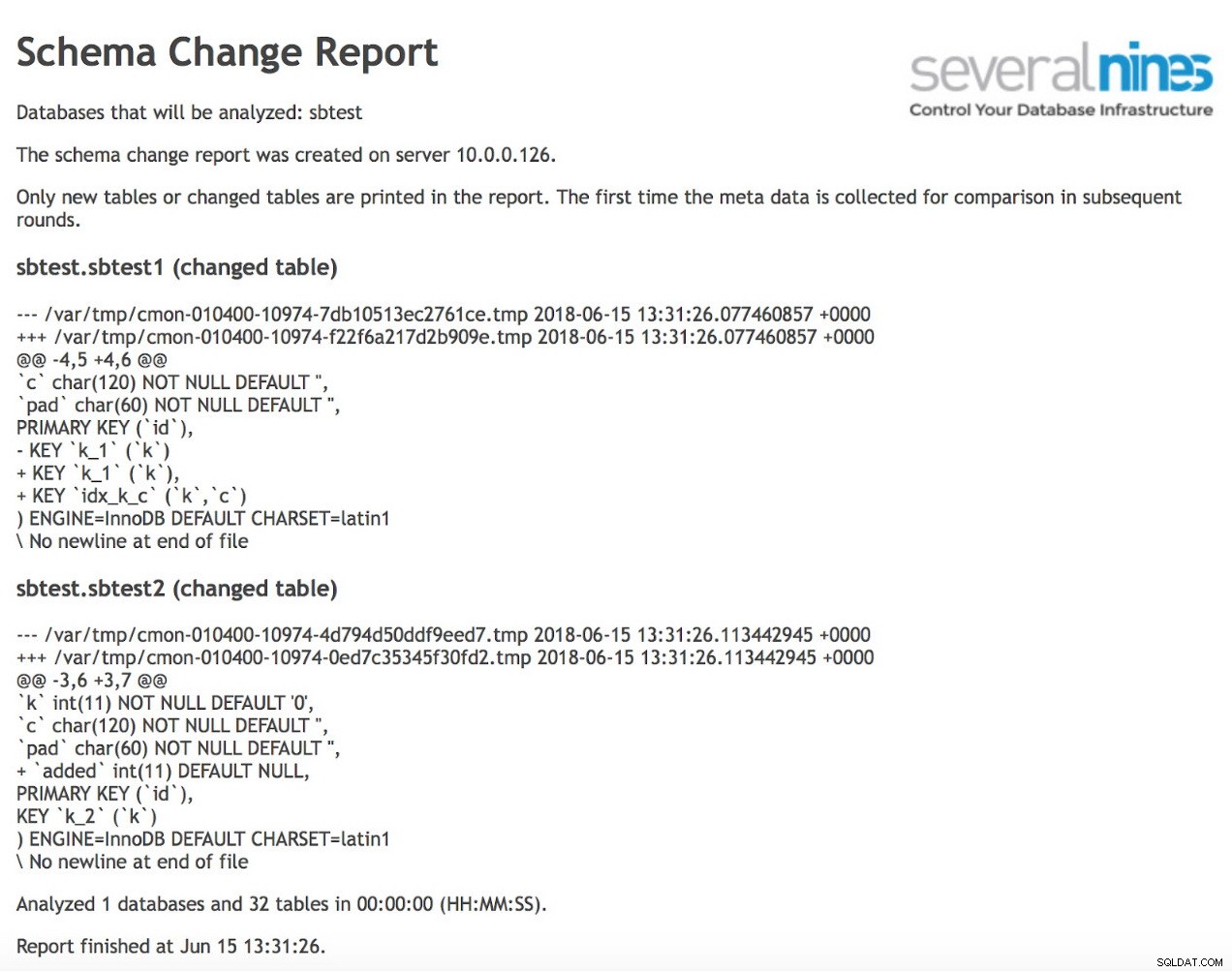
Comme vous pouvez le constater, deux tableaux ont été modifiés depuis la précédente exécution du rapport. Dans le premier, un nouvel index composite a été créé sur les colonnes (k, c). Dans le deuxième tableau, une colonne a été ajoutée.
Lors de l'exécution suivante, nous avons obtenu des informations sur la nouvelle table, qui a été créée sans index ni clé primaire. Grâce à ce type d'informations, nous pouvons facilement agir en cas de besoin et résoudre les problèmes avant qu'ils ne deviennent des bloqueurs.



