Dans un article précédent, nous avons expliqué comment prendre le contrôle du processus de basculement dans ClusterControl en utilisant des listes blanches et des listes noires. Dans cet article, nous allons discuter d'un concept similaire. Mais cette fois, nous nous concentrerons sur les intégrations avec des scripts et des applications externes via de nombreux crochets mis à disposition par ClusterControl.
Les environnements d'infrastructure peuvent être construits de différentes manières, car il existe souvent de nombreuses options parmi lesquelles choisir pour une pièce donnée du puzzle. Comment définissons-nous sur quel nœud de base de données écrire ? Utilisez-vous une adresse IP virtuelle ? Utilisez-vous une sorte de découverte de service ? Peut-être allez-vous avec des entrées DNS et modifiez les enregistrements A si nécessaire ? Qu'en est-il de la couche proxy ? Comptez-vous sur la valeur "read_only" pour que vos proxys décident de l'écrivain, ou peut-être apportez-vous les modifications requises directement dans la configuration du proxy ? Comment votre environnement gère-t-il les basculements ? Pouvez-vous simplement aller de l'avant et l'exécuter, ou peut-être devez-vous prendre des mesures préliminaires au préalable ? Par exemple, arrêter d'autres processus avant de pouvoir effectuer le changement ?
Il n'est pas possible qu'un logiciel de basculement soit préconfiguré pour couvrir toutes les différentes configurations que les utilisateurs peuvent créer. C'est la raison principale pour fournir différentes manières de se connecter au processus de basculement. De cette façon, vous pouvez le personnaliser et permettre de gérer toutes les subtilités de votre configuration. Dans cet article de blog, nous verrons comment le processus de basculement de ClusterControl peut être personnalisé à l'aide de différents scripts de pré-basculement et de post-basculement. Nous discuterons également de quelques exemples de ce qui peut être accompli avec une telle personnalisation.
Intégration de ClusterControl
ClusterControl fournit plusieurs crochets qui peuvent être utilisés pour brancher des scripts externes. Vous trouverez ci-dessous une liste de ceux-ci avec quelques explications.
- Replication_onfail_failover_script - ce script s'exécute dès qu'il a été découvert qu'un basculement est nécessaire. Si le script renvoie une valeur différente de zéro, il forcera l'abandon du basculement. Si le script est défini mais introuvable, le basculement sera abandonné. Quatre arguments sont fournis au script :arg1='tous les serveurs' arg2='ancien maître' arg3='candidat', arg4='esclaves de l'ancien maître' et passés comme ceci :'nom du script arg1 arg2 arg3 arg4'. Le script doit être accessible sur le contrôleur et être exécutable.
- Replication_pre_failover_script - ce script s'exécute avant que le basculement ne se produise, mais après qu'un candidat a été élu et qu'il est possible de poursuivre le processus de basculement. Si le script renvoie une valeur différente de zéro, il forcera l'abandon du basculement. Si le script est défini mais introuvable, le basculement sera abandonné. Le script doit être accessible sur le contrôleur et être exécutable.
- Replication_post_failover_script - ce script s'exécute après le basculement. Si le script renvoie une valeur différente de zéro, un avertissement sera écrit dans le journal des travaux. Le script doit être accessible sur le contrôleur et être exécutable.
- Replication_post_unsuccessful_failover_script - Ce script est exécuté après l'échec de la tentative de basculement. Si le script renvoie une valeur différente de zéro, un avertissement sera écrit dans le journal des travaux. Le script doit être accessible sur le contrôleur et être exécutable.
- Replication_failed_reslave_failover_script - ce script est exécuté après qu'un nouveau maître a été promu et si le réasservissement des esclaves au nouveau maître échoue. Si le script renvoie une valeur différente de zéro, un avertissement sera écrit dans le journal des travaux. Le script doit être accessible sur le contrôleur et être exécutable.
- Replication_pre_switchover_script :ce script s'exécute avant le basculement. Si le script renvoie une valeur différente de zéro, il forcera le basculement à échouer. Si le script est défini mais introuvable, le basculement sera abandonné. Le script doit être accessible sur le contrôleur et être exécutable.
- Replication_post_switchover_script - ce script s'exécute après le basculement. Si le script renvoie une valeur différente de zéro, un avertissement sera écrit dans le journal des travaux. Le script doit être accessible sur le contrôleur et être exécutable.
Comme vous pouvez le voir, les crochets couvrent la plupart des cas où vous voudrez peut-être effectuer certaines actions - avant et après un basculement, avant et après un basculement, lorsque le reslave a échoué ou lorsque le basculement a échoué. Tous les scripts sont invoqués avec quatre arguments (qui peuvent ou non être gérés dans le script, il n'est pas nécessaire que le script les utilise tous) :tous les serveurs, nom d'hôte (ou IP - tel qu'il est défini dans ClusterControl) de l'ancien maître, le nom d'hôte (ou IP - tel qu'il est défini dans ClusterControl) du candidat maître et le quatrième, toutes les répliques de l'ancien maître. Ces options devraient permettre de traiter la majorité des cas.
Tous ces crochets doivent être définis dans un fichier de configuration pour un cluster donné (/etc/cmon.d/cmon_X.cnf où X est l'identifiant du cluster). Un exemple peut ressembler à ceci :
replication_pre_failover_script=/usr/bin/stonith.py
replication_post_failover_script=/usr/bin/vipmove.shBien sûr, les scripts invoqués doivent être exécutables, sinon cmon ne pourra pas les exécuter. Prenons maintenant un moment et passons en revue le processus de basculement dans ClusterControl et voyons quand les scripts externes sont exécutés.
Processus de basculement dans ClusterControl
Nous avons défini tous les hooks disponibles :
replication_onfail_failover_script=/tmp/1.sh
replication_pre_failover_script=/tmp/2.sh
replication_post_failover_script=/tmp/3.sh
replication_post_unsuccessful_failover_script=/tmp/4.sh
replication_failed_reslave_failover_script=/tmp/5.sh
replication_pre_switchover_script=/tmp/6.sh
replication_post_switchover_script=/tmp/7.shAprès cela, vous devez redémarrer le processus cmon. Une fois que c'est fait, nous sommes prêts à tester le basculement. La topologie d'origine ressemble à ceci :
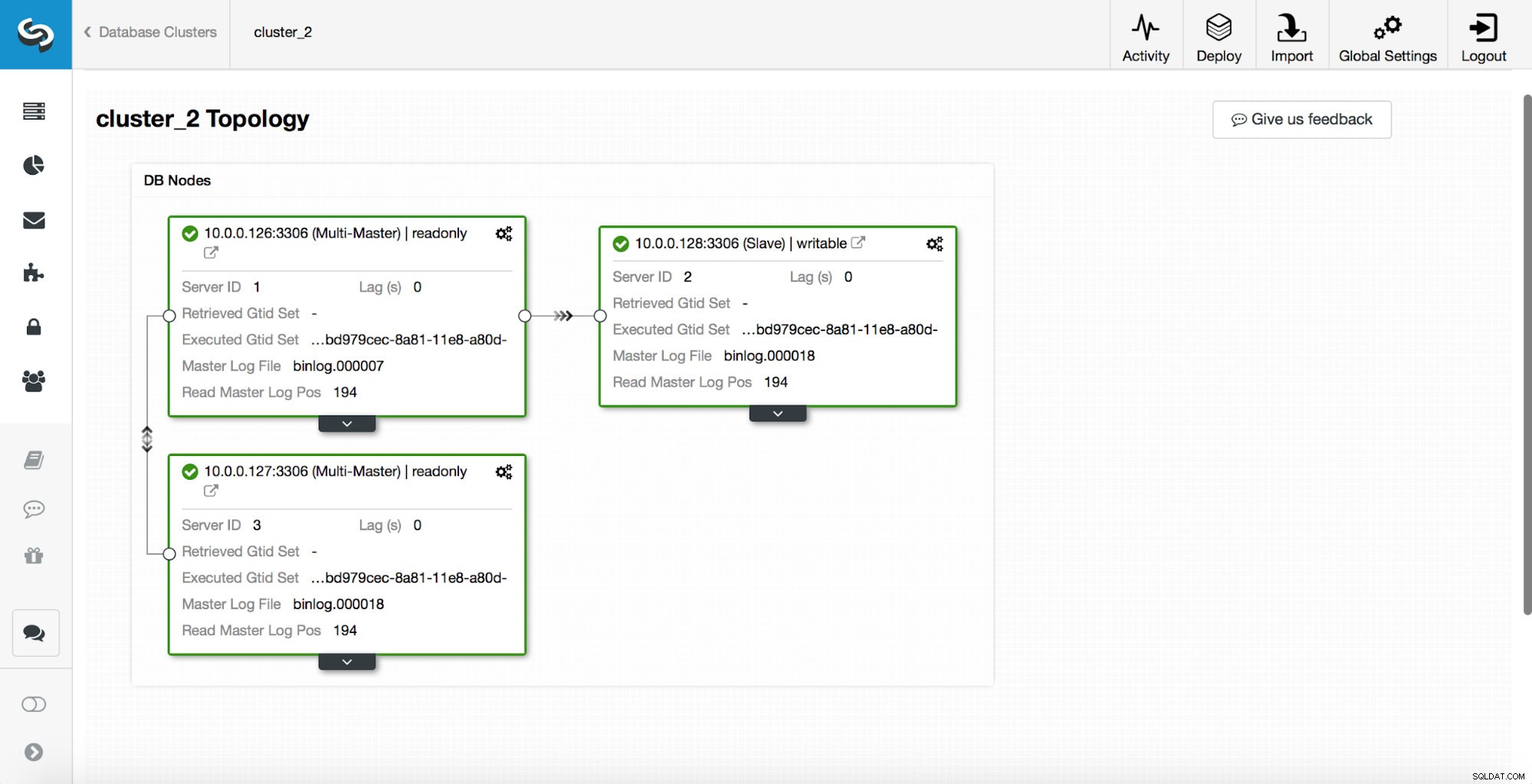
Un maître a été tué et le processus de basculement a démarré. Veuillez noter que les entrées de journal les plus récentes sont en haut, vous souhaitez donc suivre le basculement de bas en haut.
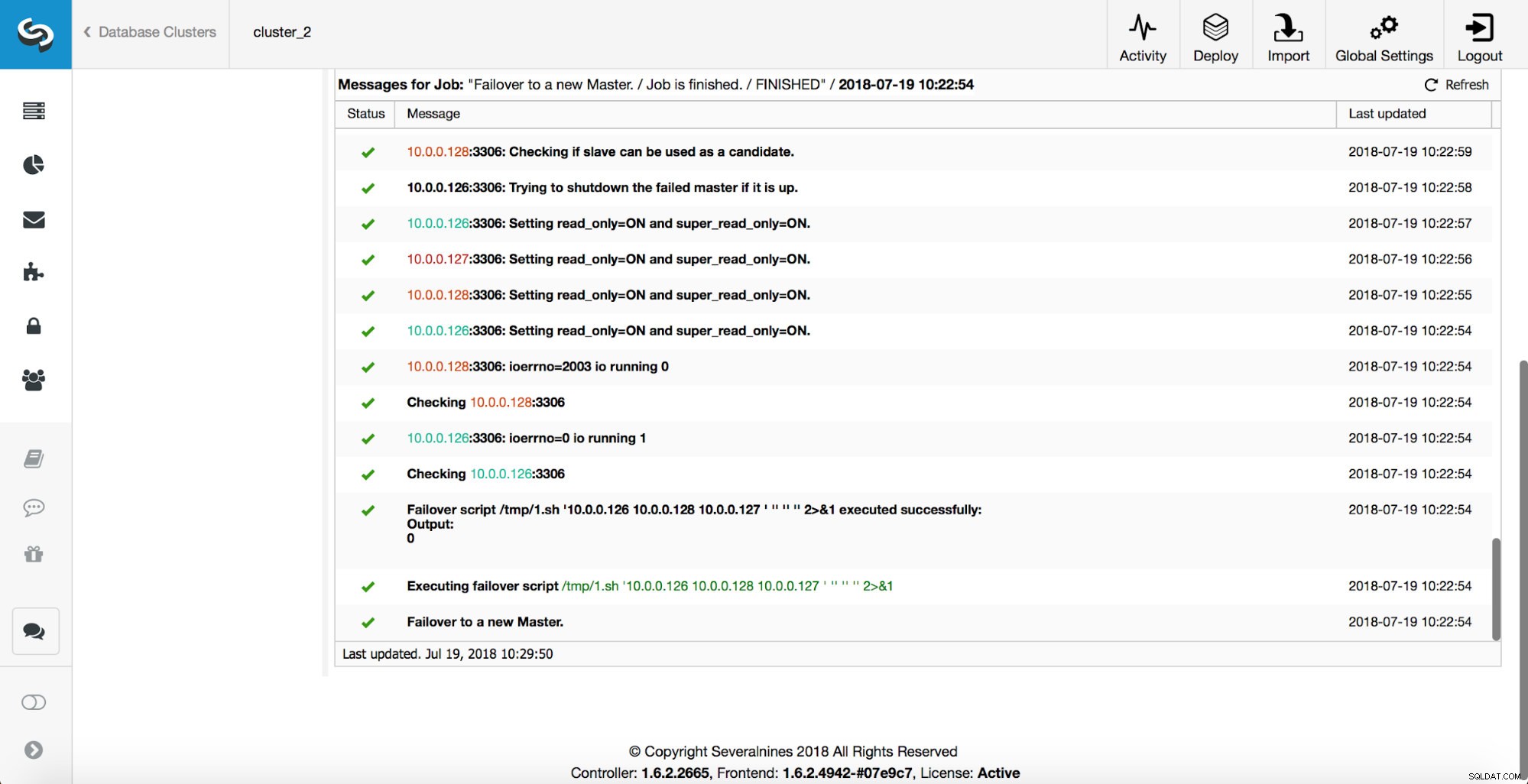
Comme vous pouvez le voir, immédiatement après le démarrage de la tâche de basculement, il déclenche le hook « replication_onfail_failover_script ». Ensuite, tous les hôtes accessibles sont marqués en lecture seule et ClusterControl tente d'empêcher l'ancien maître de s'exécuter.
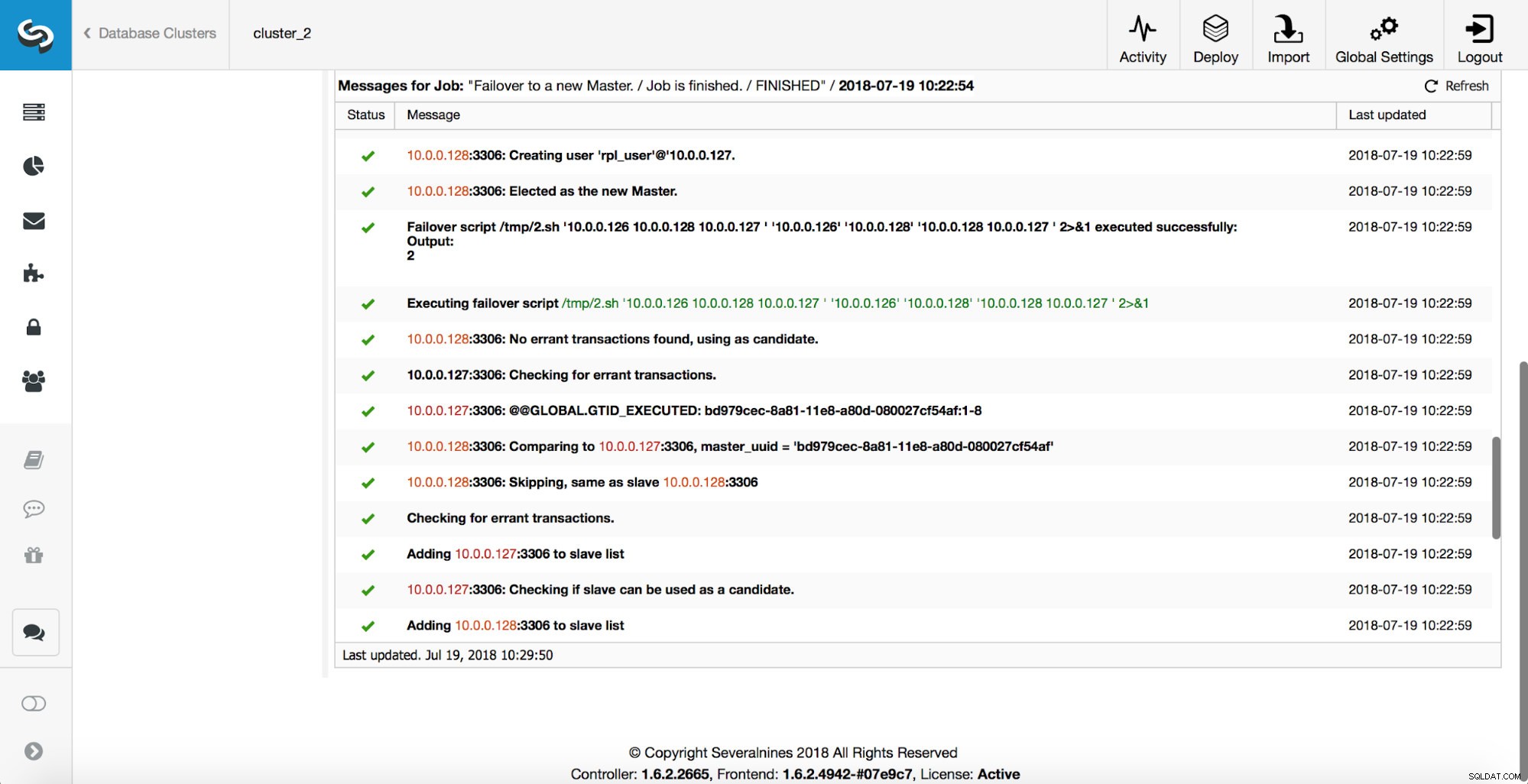
Ensuite, le candidat principal est choisi, des vérifications de cohérence sont exécutées. Une fois qu'il est confirmé que le maître candidat peut être utilisé comme nouveau maître, le "replication_pre_failover_script" est exécuté.
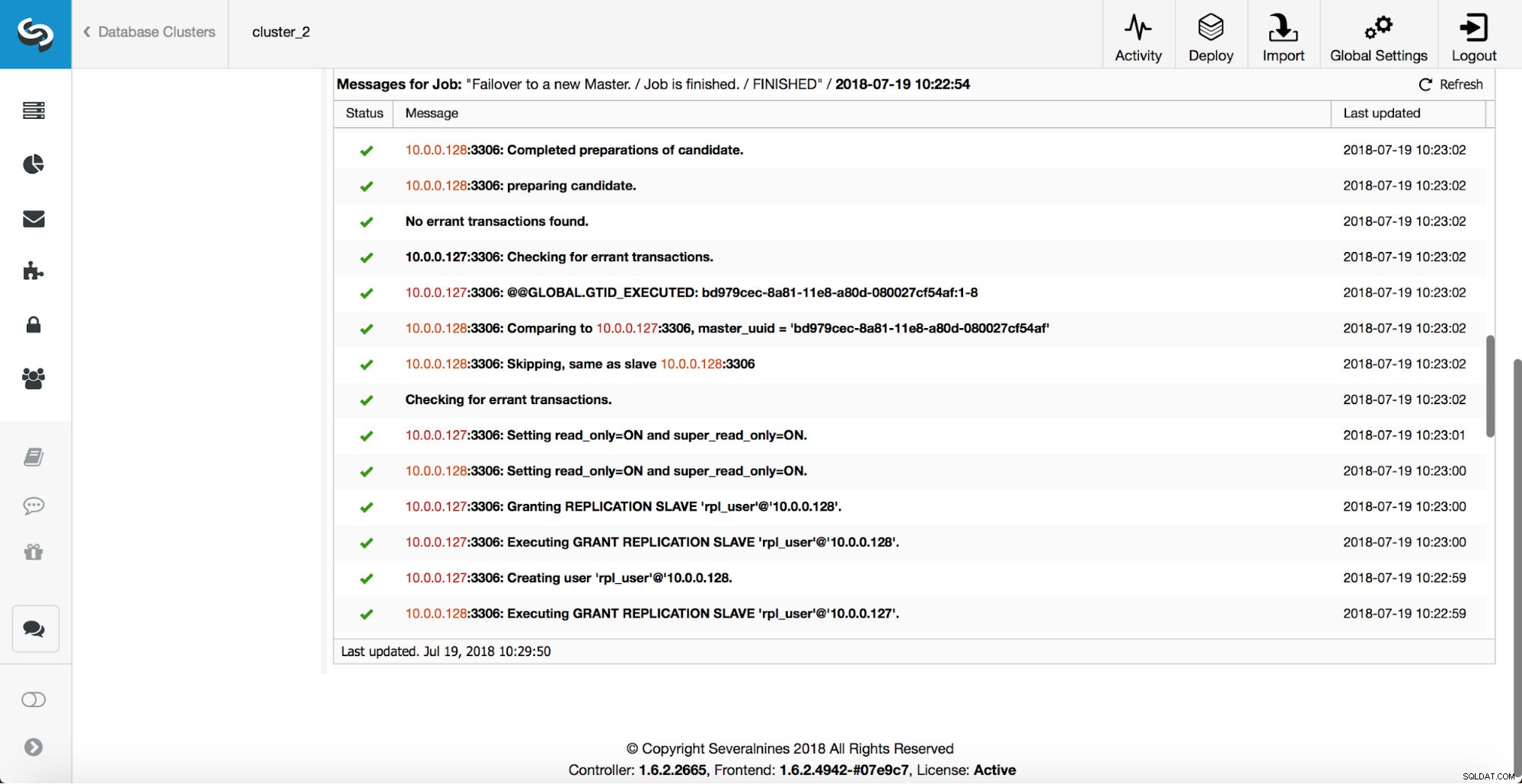
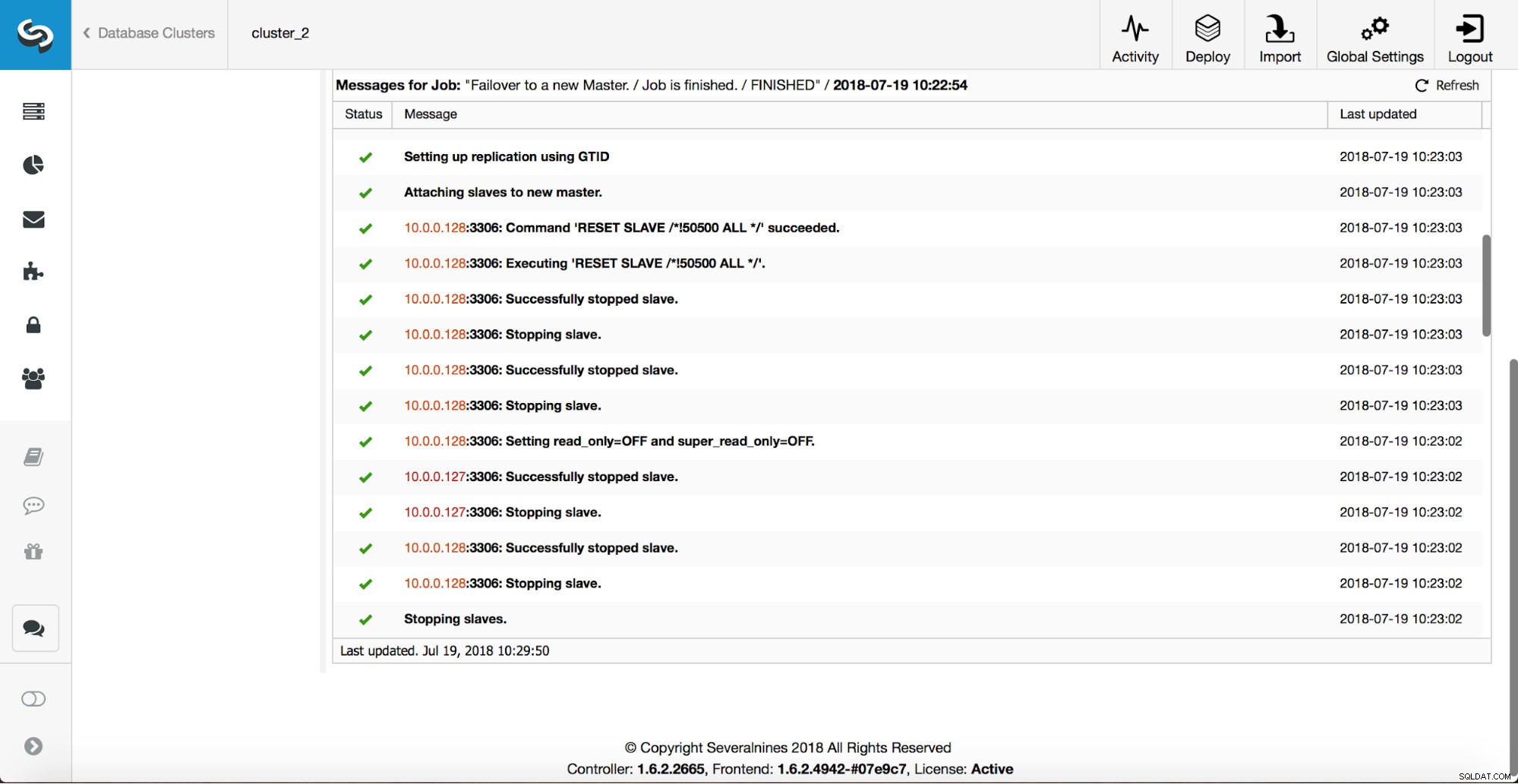
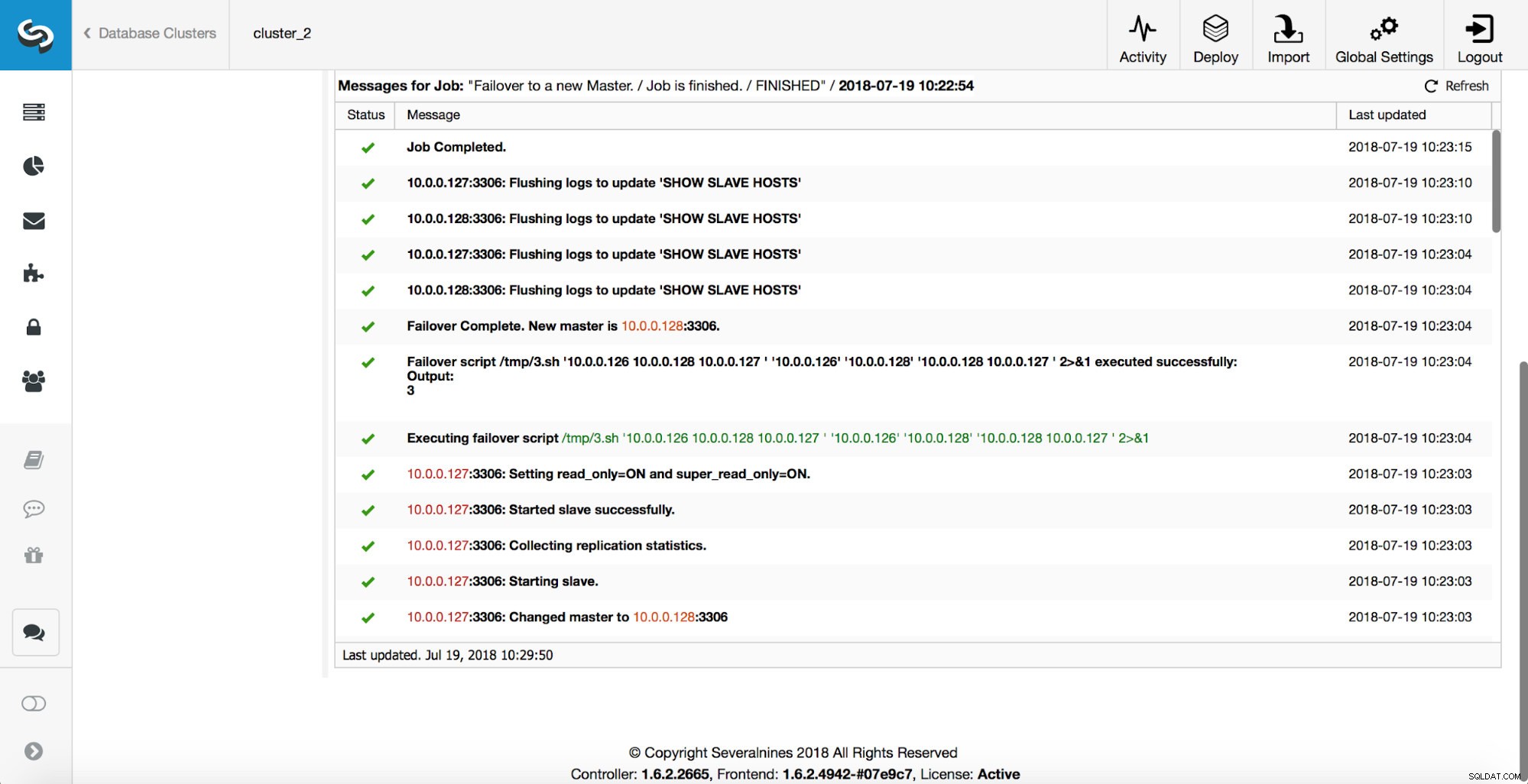
D'autres vérifications sont effectuées, les répliques sont arrêtées et asservies au nouveau maître. Enfin, une fois le basculement terminé, un crochet final, "replication_post_failover_script", est déclenché.
Quand les crochets peuvent être utiles ?
Dans cette section, nous allons passer en revue quelques exemples de cas où il pourrait être judicieux d'implémenter des scripts externes. Nous n'entrerons pas dans les détails car ceux-ci sont trop étroitement liés à un environnement particulier. Il s'agira plutôt d'une liste de suggestions qu'il pourrait être utile de mettre en œuvre.
Script STONITH
Shoot The Other Node In The Head (STONITH) est un processus qui permet de s'assurer que l'ancien maître, qui est mort, restera mort (et oui... nous n'aimons pas que les zombies errent dans notre infrastructure). La dernière chose que vous voulez probablement est d'avoir un ancien maître qui ne répond pas qui se remet ensuite en ligne et, par conséquent, vous vous retrouvez avec deux maîtres inscriptibles. Vous pouvez prendre certaines précautions pour vous assurer que l'ancien maître ne sera pas utilisé même s'il réapparaît, et il est plus sûr qu'il reste hors ligne. Les moyens de s'en assurer différeront d'un environnement à l'autre. Par conséquent, très probablement, il n'y aura pas de prise en charge intégrée de STONITH dans l'outil de basculement. Selon l'environnement, vous souhaiterez peut-être exécuter une commande CLI qui arrêtera (et même supprimera) une machine virtuelle sur laquelle l'ancien maître est en cours d'exécution. Si vous avez une configuration sur site, vous pouvez avoir plus de contrôle sur le matériel. Il pourrait être possible d'utiliser une sorte de gestion à distance (Lights-out intégré ou un autre accès à distance au serveur). Vous pouvez également avoir accès à des prises de courant gérables et couper l'alimentation de l'une d'entre elles pour vous assurer que le serveur ne redémarrera jamais sans intervention humaine.
Découverte de services
Nous avons déjà parlé un peu de la découverte de service. Il existe de nombreuses façons de stocker des informations sur une topologie de réplication et de détecter quel hôte est un maître. L'une des options les plus populaires consiste certainement à utiliser etc.d ou Consul pour stocker des données sur la topologie actuelle. Avec lui, une application ou un proxy peut s'appuyer sur ces données pour envoyer le trafic au bon nœud. ClusterControl (tout comme la plupart des outils qui prennent en charge la gestion du basculement) n'a pas d'intégration directe avec etc.d ou Consul. La tâche de mise à jour des données de topologie incombe à l'utilisateur. Elle peut utiliser des crochets comme replication_post_failover_script ou replication_post_switchover_script pour invoquer certains des scripts et effectuer les modifications requises. Une autre solution assez courante consiste à utiliser le DNS pour diriger le trafic vers les instances correctes. Si vous souhaitez maintenir la durée de vie d'un enregistrement DNS faible, vous devriez pouvoir définir un domaine qui pointera vers votre maître (c'est-à-dire writes.cluster1.example.com). Cela nécessite une modification des enregistrements DNS et, encore une fois, des crochets comme replication_post_failover_script ou replication_post_switchover_script peuvent être très utiles pour apporter les modifications requises après un basculement.
Reconfiguration du proxy
Chaque serveur proxy utilisé doit envoyer le trafic aux instances correctes. En fonction du proxy lui-même, la façon dont une détection principale est effectuée peut être (partiellement) codée en dur ou peut appartenir à l'utilisateur de définir ce qu'il veut. Le mécanisme de basculement de ClusterControl est conçu de manière à s'intégrer parfaitement aux proxys qu'il a déployés et configurés. Il peut toujours arriver qu'il y ait des proxies en place, qui n'ont pas été installés par ClusterControl et qui nécessitent que certaines actions manuelles aient lieu pendant l'exécution du basculement. Ces proxys peuvent également être intégrés au processus de basculement de ClusterControl via des scripts externes et des hooks tels que replication_post_failover_script ou replication_post_switchover_script.
Journalisation supplémentaire
Il peut arriver que vous souhaitiez collecter des données du processus de basculement à des fins de débogage. ClusterControl dispose de nombreux imprimés pour s'assurer qu'il est possible de suivre le processus et de comprendre ce qui s'est passé et pourquoi. Il peut toujours arriver que vous souhaitiez collecter des informations supplémentaires et personnalisées. Fondamentalement, tous les crochets peuvent être utilisés ici - vous pouvez collecter l'état initial, avant le basculement, vous pouvez suivre l'état de l'environnement à toutes les étapes du basculement.