En tant qu'administrateurs système et développeurs, nous passons beaucoup de temps dans un terminal. Nous avons donc apporté ClusterControl au terminal avec notre outil d'interface de ligne de commande appelé s9s. s9s fournit une interface simple à l'API ClusterControl RPC v2. Vous le trouverez très utile lorsque vous travaillez avec des déploiements à grande échelle, car la CLI vous permettra de concevoir des fonctionnalités et des flux de travail plus complexes.
Ce billet de blog explique comment utiliser s9s pour automatiser la gestion de Galera Cluster pour MySQL ou MariaDB, ainsi qu'une simple configuration de réplication maître-esclave.
Configuration
Vous pouvez trouver des instructions d'installation pour votre système d'exploitation particulier dans la documentation. Ce qu'il est important de noter, c'est que si vous utilisez les derniers outils s9s, de GitHub, il y a un léger changement dans la façon dont vous créez un utilisateur. La commande suivante fonctionnera correctement :
s9s user --create --generate-key --controller="https://localhost:9501" dbaEn général, deux étapes sont nécessaires si vous souhaitez configurer la CLI localement sur l'hôte ClusterControl. Tout d'abord, vous devez créer un utilisateur, puis apporter des modifications au fichier de configuration - toutes les étapes sont incluses dans la documentation.
Déploiement
Une fois que l'interface de ligne de commande a été correctement configurée et dispose d'un accès SSH aux hôtes de votre base de données cible, vous pouvez démarrer le processus de déploiement. Au moment de la rédaction, vous pouvez utiliser la CLI pour déployer des clusters MySQL, MariaDB et PostgreSQL. Commençons par un exemple de déploiement de Percona XtraDB Cluster 5.7. Une seule commande est nécessaire pour cela.
s9s cluster --create --cluster-type=galera --nodes="10.0.0.226;10.0.0.227;10.0.0.228" --vendor=percona --provider-version=5.7 --db-admin-passwd="pass" --os-user=root --cluster-name="PXC_Cluster_57" --waitLa dernière option "--wait" signifie que la commande attendra la fin du travail, indiquant sa progression. Vous pouvez l'ignorer si vous le souhaitez - dans ce cas, la commande s9s reviendra immédiatement au shell après avoir enregistré une nouvelle tâche dans cmon. C'est parfaitement bien car cmon est le processus qui gère le travail lui-même. Vous pouvez toujours vérifier la progression d'une tâche séparément, en utilisant :
example@sqldat.com:~# s9s job --list -l
--------------------------------------------------------------------------------------
Create Galera Cluster
Installing MySQL on 10.0.0.226 [██▊ ]
26.09%
Created : 2017-10-05 11:23:00 ID : 1 Status : RUNNING
Started : 2017-10-05 11:23:02 User : dba Host :
Ended : Group: users
--------------------------------------------------------------------------------------
Total: 1Prenons un autre exemple. Cette fois, nous allons créer un nouveau cluster, la réplication MySQL :simple paire maître - esclave. Encore une fois, une seule commande suffit :
example@sqldat.com:~# s9s cluster --create --nodes="10.0.0.229?master;10.0.0.230?slave" --vendor=percona --cluster-type=mysqlreplication --provider-version=5.7 --os-user=root --wait
Create MySQL Replication Cluster
/ Job 6 FINISHED [██████████] 100% Cluster createdNous pouvons maintenant vérifier que les deux clusters sont opérationnels :
example@sqldat.com:~# s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED galera dba users PXC_Cluster_57 All nodes are operational.
2 STARTED replication dba users cluster_2 All nodes are operational.
Total: 2Bien sûr, tout cela est également visible via l'interface graphique :
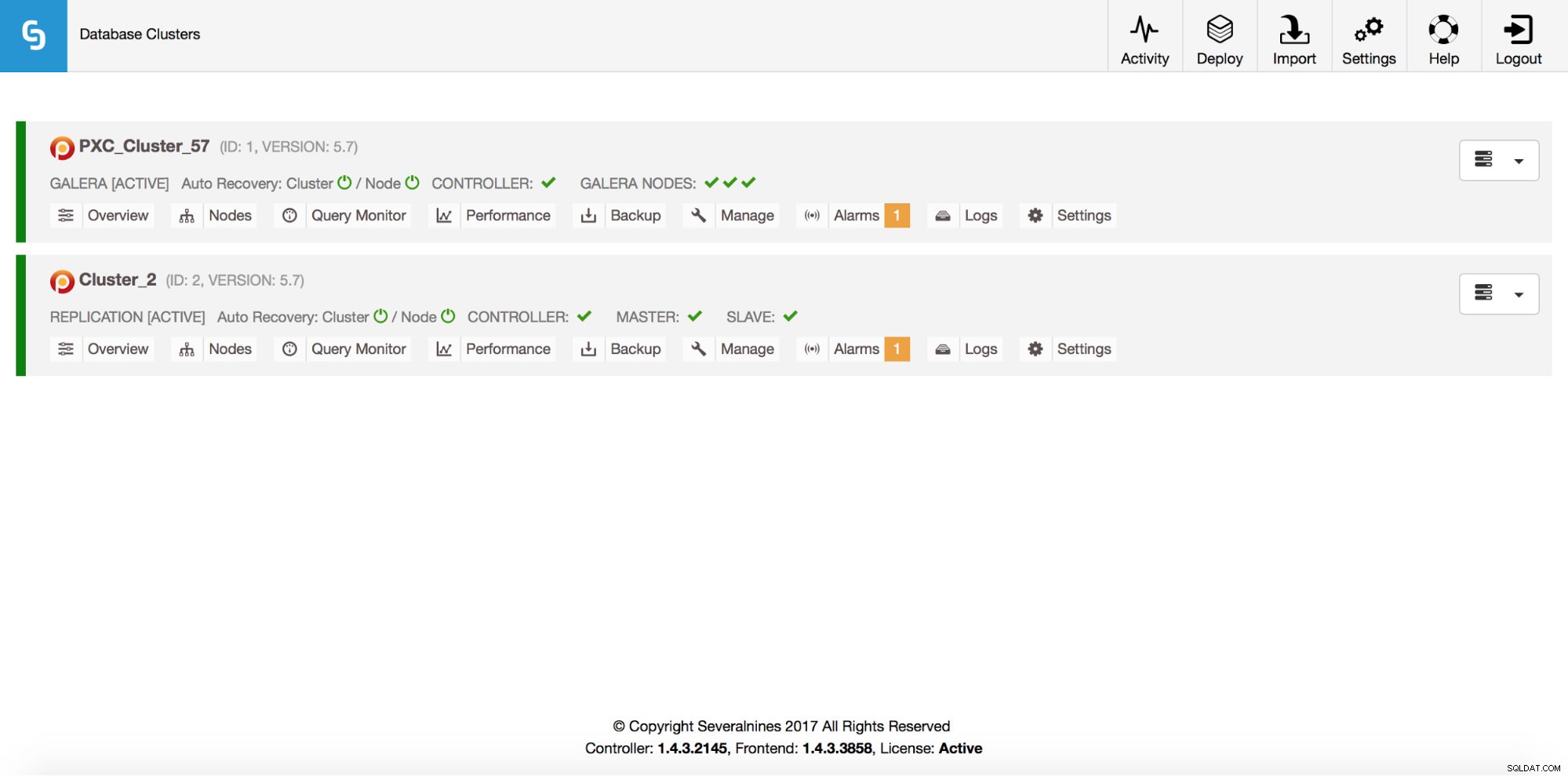
Ajoutons maintenant un équilibreur de charge ProxySQL :
example@sqldat.com:~# s9s cluster --add-node --nodes="proxysql://10.0.0.226" --cluster-id=1
WARNING: admin/admin
WARNING: proxy-monitor/proxy-monitor
Job with ID 7 registered.Cette fois, nous n'avons pas utilisé l'option "--wait", donc si nous voulons vérifier la progression, nous devons le faire nous-mêmes. Veuillez noter que nous utilisons un ID de travail qui a été renvoyé par la commande précédente, nous n'obtiendrons donc des informations que sur ce travail particulier :
example@sqldat.com:~# s9s job --list --long --job-id=7
--------------------------------------------------------------------------------------
Add ProxySQL to Cluster
Waiting for ProxySQL [██████▋ ]
65.00%
Created : 2017-10-06 14:09:11 ID : 7 Status : RUNNING
Started : 2017-10-06 14:09:12 User : dba Host :
Ended : Group: users
--------------------------------------------------------------------------------------
Total: 7Scaling out
Des nœuds peuvent être ajoutés à notre cluster Galera via une seule commande :
s9s cluster --add-node --nodes 10.0.0.229 --cluster-id 1
Job with ID 8 registered.
example@sqldat.com:~# s9s job --list --job-id=8
ID CID STATE OWNER GROUP CREATED RDY TITLE
8 1 FAILED dba users 14:15:52 0% Add Node to Cluster
Total: 8Quelque chose s'est mal passé. Nous pouvons vérifier ce qui s'est passé exactement :
example@sqldat.com:~# s9s job --log --job-id=8
addNode: Verifying job parameters.
10.0.0.229:3306: Adding host to cluster.
10.0.0.229:3306: Testing SSH to host.
10.0.0.229:3306: Installing node.
10.0.0.229:3306: Setup new node (installSoftware = true).
10.0.0.229:3306: Detected a running mysqld server. It must be uninstalled first, or you can also add it to ClusterControl.Bon, cette adresse IP est déjà utilisée pour notre serveur de réplication. Nous aurions dû utiliser une autre IP gratuite. Essayons cela :
example@sqldat.com:~# s9s cluster --add-node --nodes 10.0.0.231 --cluster-id 1
Job with ID 9 registered.
example@sqldat.com:~# s9s job --list --job-id=9
ID CID STATE OWNER GROUP CREATED RDY TITLE
9 1 FINISHED dba users 14:20:08 100% Add Node to Cluster
Total: 9Gérer
Disons que nous voulons faire une sauvegarde de notre maître de réplication. Nous pouvons le faire à partir de l'interface graphique, mais parfois nous devrons peut-être l'intégrer à des scripts externes. ClusterControl CLI conviendrait parfaitement à un tel cas. Voyons quels clusters nous avons :
example@sqldat.com:~# s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED galera dba users PXC_Cluster_57 All nodes are operational.
2 STARTED replication dba users cluster_2 All nodes are operational.
Total: 2Ensuite, vérifions les hôtes de notre cluster de réplication, avec l'ID de cluster 2 :
example@sqldat.com:~# s9s nodes --list --long --cluster-id=2
STAT VERSION CID CLUSTER HOST PORT COMMENT
soM- 5.7.19-17-log 2 cluster_2 10.0.0.229 3306 Up and running
soS- 5.7.19-17-log 2 cluster_2 10.0.0.230 3306 Up and running
coC- 1.4.3.2145 2 cluster_2 10.0.2.15 9500 Up and runningComme nous pouvons le voir, il y a trois hôtes que ClusterControl connaît - deux d'entre eux sont des hôtes MySQL (10.0.0.229 et 10.0.0.230), le troisième est l'instance ClusterControl elle-même. N'imprimons que les hôtes MySQL pertinents :
example@sqldat.com:~# s9s nodes --list --long --cluster-id=2 10.0.0.2*
STAT VERSION CID CLUSTER HOST PORT COMMENT
soM- 5.7.19-17-log 2 cluster_2 10.0.0.229 3306 Up and running
soS- 5.7.19-17-log 2 cluster_2 10.0.0.230 3306 Up and running
Total: 3Dans la colonne "STAT", vous pouvez y voir quelques caractères. Pour plus d'informations, nous vous suggérons de consulter la page de manuel des nœuds s9s (man s9s-nodes). Ici, nous allons simplement résumer les éléments les plus importants. Le premier caractère nous renseigne sur le type de nœud :"s" signifie qu'il s'agit d'un nœud MySQL normal, "c" - contrôleur ClusterControl. Le deuxième caractère décrit l'état du nœud :"o" nous indique qu'il est en ligne. Troisième caractère - rôle du nœud. Ici, "M" décrit un maître et "S" - un esclave tandis que "C" signifie contrôleur. Enfin, le quatrième caractère nous indique si le nœud est en mode maintenance. "-" signifie qu'il n'y a pas de maintenance planifiée. Sinon, nous verrions "M" ici. Ainsi, à partir de ces données, nous pouvons voir que notre maître est un hôte avec IP :10.0.0.229. Prenons-en une sauvegarde et stockons-la sur le contrôleur.
example@sqldat.com:~# s9s backup --create --nodes=10.0.0.229 --cluster-id=2 --backup-method=xtrabackupfull --wait
Create Backup
| Job 12 FINISHED [██████████] 100% Command okNous pouvons alors vérifier s'il s'est bien déroulé. A noter l'option "--backup-format" qui permet de définir quelles informations doivent être imprimées :
example@sqldat.com:~# s9s backup --list --full --backup-format="Started: %B Completed: %E Method: %M Stored on: %S Size: %s %F\n" --cluster-id=2
Started: 15:29:11 Completed: 15:29:19 Method: xtrabackupfull Stored on: 10.0.0.229 Size: 543382 backup-full-2017-10-06_152911.xbstream.gz
Total 1Surveillance
Toutes les bases de données doivent être surveillées. ClusterControl utilise des conseillers pour surveiller certaines des métriques à la fois sur MySQL et sur le système d'exploitation. Lorsqu'une condition est remplie, une notification est envoyée. ClusterControl fournit également un ensemble complet de graphiques, à la fois en temps réel et historiques pour la planification post-mortem ou de capacité. Parfois, ce serait formidable d'avoir accès à certaines de ces métriques sans avoir à passer par l'interface graphique. ClusterControl CLI le permet via la commande s9s-node. Des informations sur la façon de procéder peuvent être trouvées dans la page de manuel de s9s-node. Nous allons montrer quelques exemples de ce que vous pouvez faire avec CLI.
Tout d'abord, examinons l'option "--node-format" de la commande "s9s node". Comme vous pouvez le voir, il existe de nombreuses options pour imprimer du contenu intéressant.
example@sqldat.com:~# s9s node --list --node-format "%N %T %R %c cores %u%% CPU utilization %fmG of free memory, %tMB/s of net TX+RX, %M\n" "10.0.0.2*"
10.0.0.226 galera none 1 cores 13.823200% CPU utilization 0.503227G of free memory, 0.061036MB/s of net TX+RX, Up and running
10.0.0.227 galera none 1 cores 13.033900% CPU utilization 0.543209G of free memory, 0.053596MB/s of net TX+RX, Up and running
10.0.0.228 galera none 1 cores 12.929100% CPU utilization 0.541988G of free memory, 0.052066MB/s of net TX+RX, Up and running
10.0.0.226 proxysql 1 cores 13.823200% CPU utilization 0.503227G of free memory, 0.061036MB/s of net TX+RX, Process 'proxysql' is running.
10.0.0.231 galera none 1 cores 13.104700% CPU utilization 0.544048G of free memory, 0.045713MB/s of net TX+RX, Up and running
10.0.0.229 mysql master 1 cores 11.107300% CPU utilization 0.575871G of free memory, 0.035830MB/s of net TX+RX, Up and running
10.0.0.230 mysql slave 1 cores 9.861590% CPU utilization 0.580315G of free memory, 0.035451MB/s of net TX+RX, Up and runningAvec ce que nous avons montré ici, vous pouvez probablement imaginer des cas d'automatisation. Par exemple, vous pouvez surveiller l'utilisation du processeur des nœuds et si elle atteint un certain seuil, vous pouvez exécuter un autre travail s9s pour faire tourner un nouveau nœud dans le cluster Galera. Vous pouvez également, par exemple, surveiller l'utilisation de la mémoire et envoyer des alertes si elle dépasse un certain seuil.
La CLI peut faire plus que cela. Tout d'abord, il est possible de vérifier les graphiques depuis la ligne de commande. Bien sûr, ceux-ci ne sont pas aussi riches en fonctionnalités que les graphiques de l'interface graphique, mais il suffit parfois de voir un graphique pour trouver un modèle inattendu et décider s'il vaut la peine d'être approfondi.
example@sqldat.com:~# s9s node --stat --cluster-id=1 --begin="00:00" --end="14:00" --graph=load 10.0.0.231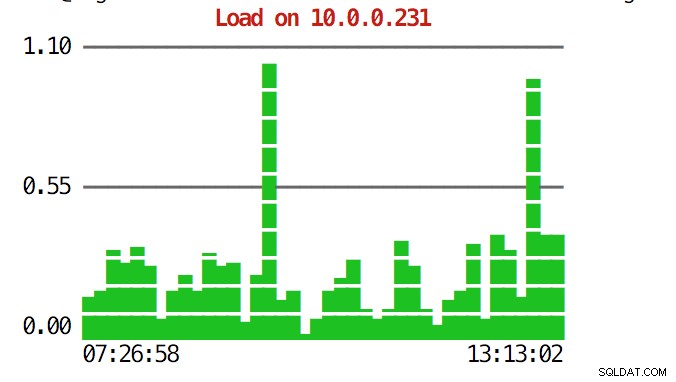
example@sqldat.com:~# s9s node --stat --cluster-id=1 --begin="00:00" --end="14:00" --graph=sqlqueries 10.0.0.231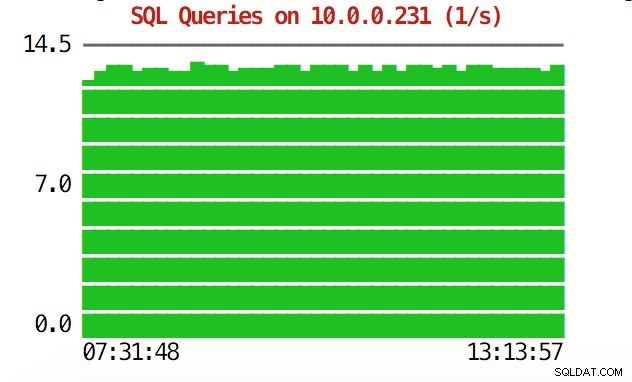
Lors de situations d'urgence, vous souhaiterez peut-être vérifier l'utilisation des ressources dans le cluster. Vous pouvez créer une sortie de type top qui combine les données de tous les nœuds du cluster :
example@sqldat.com:~# s9s process --top --cluster-id=1
PXC_Cluster_57 - 14:38:01 All nodes are operational.
4 hosts, 7 cores, 2.2 us, 3.1 sy, 94.7 id, 0.0 wa, 0.0 st,
GiB Mem : 2.9 total, 0.2 free, 0.9 used, 0.2 buffers, 1.6 cached
GiB Swap: 3 total, 0 used, 3 free,
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
8331 root 10.0.2.15 20 743748 40948 S 10.28 5.40 cmon
26479 root 10.0.0.226 20 278532 6448 S 2.49 0.85 accounts-daemon
5466 root 10.0.0.226 20 95372 7132 R 1.72 0.94 sshd
651 root 10.0.0.227 20 278416 6184 S 1.37 0.82 accounts-daemon
716 root 10.0.0.228 20 278304 6052 S 1.35 0.80 accounts-daemon
22447 n/a 10.0.0.226 20 2744444 148820 S 1.20 19.63 mysqld
975 mysql 10.0.0.228 20 2733624 115212 S 1.18 15.20 mysqld
13691 n/a 10.0.0.227 20 2734104 130568 S 1.11 17.22 mysqld
22994 root 10.0.2.15 20 30400 9312 S 0.93 1.23 s9s
9115 root 10.0.0.227 20 95368 7192 S 0.68 0.95 sshd
23768 root 10.0.0.228 20 95372 7160 S 0.67 0.94 sshd
15690 mysql 10.0.2.15 20 1102012 209056 S 0.67 27.58 mysqld
11471 root 10.0.0.226 20 95372 7392 S 0.17 0.98 sshd
22086 vagrant 10.0.2.15 20 95372 4960 S 0.17 0.65 sshd
7282 root 10.0.0.226 20 0 0 S 0.09 0.00 kworker/u4:2
9003 root 10.0.0.226 20 0 0 S 0.09 0.00 kworker/u4:1
1195 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/u4:0
27240 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/1:1
9933 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/u4:2
16181 root 10.0.0.228 20 0 0 S 0.08 0.00 kworker/u4:1
1744 root 10.0.0.228 20 0 0 S 0.08 0.00 kworker/1:1
28506 root 10.0.0.228 20 95372 7348 S 0.08 0.97 sshd
691 messagebus 10.0.0.228 20 42896 3872 S 0.08 0.51 dbus-daemon
11892 root 10.0.2.15 20 0 0 S 0.08 0.00 kworker/0:2
15609 root 10.0.2.15 20 403548 12908 S 0.08 1.70 apache2
256 root 10.0.2.15 20 0 0 S 0.08 0.00 jbd2/dm-0-8
840 root 10.0.2.15 20 316200 1308 S 0.08 0.17 VBoxService
14694 root 10.0.0.227 20 95368 7200 S 0.00 0.95 sshd
12724 n/a 10.0.0.227 20 4508 1780 S 0.00 0.23 mysqld_safe
10974 root 10.0.0.227 20 95368 7400 S 0.00 0.98 sshd
14712 root 10.0.0.227 20 95368 7384 S 0.00 0.97 sshd
16952 root 10.0.0.227 20 95368 7344 S 0.00 0.97 sshd
17025 root 10.0.0.227 20 95368 7100 S 0.00 0.94 sshd
27075 root 10.0.0.227 20 0 0 S 0.00 0.00 kworker/u4:1
27169 root 10.0.0.227 20 0 0 S 0.00 0.00 kworker/0:0
881 root 10.0.0.227 20 37976 760 S 0.00 0.10 rpc.mountd
100 root 10.0.0.227 0 0 0 S 0.00 0.00 deferwq
102 root 10.0.0.227 0 0 0 S 0.00 0.00 bioset
11876 root 10.0.0.227 20 9588 2572 S 0.00 0.34 bash
11852 root 10.0.0.227 20 95368 7352 S 0.00 0.97 sshd
104 root 10.0.0.227 0 0 0 S 0.00 0.00 kworker/1:1HLorsque vous regardez en haut, vous verrez des statistiques de CPU et de mémoire agrégées sur l'ensemble du cluster.
example@sqldat.com:~# s9s process --top --cluster-id=1
PXC_Cluster_57 - 14:38:01 All nodes are operational.
4 hosts, 7 cores, 2.2 us, 3.1 sy, 94.7 id, 0.0 wa, 0.0 st,
GiB Mem : 2.9 total, 0.2 free, 0.9 used, 0.2 buffers, 1.6 cached
GiB Swap: 3 total, 0 used, 3 free,Vous trouverez ci-dessous la liste des processus de tous les nœuds du cluster.
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
8331 root 10.0.2.15 20 743748 40948 S 10.28 5.40 cmon
26479 root 10.0.0.226 20 278532 6448 S 2.49 0.85 accounts-daemon
5466 root 10.0.0.226 20 95372 7132 R 1.72 0.94 sshd
651 root 10.0.0.227 20 278416 6184 S 1.37 0.82 accounts-daemon
716 root 10.0.0.228 20 278304 6052 S 1.35 0.80 accounts-daemon
22447 n/a 10.0.0.226 20 2744444 148820 S 1.20 19.63 mysqld
975 mysql 10.0.0.228 20 2733624 115212 S 1.18 15.20 mysqld
13691 n/a 10.0.0.227 20 2734104 130568 S 1.11 17.22 mysqldCela peut être extrêmement utile si vous avez besoin de déterminer ce qui cause la charge et quel nœud est le plus affecté.
Espérons que l'outil CLI vous facilite l'intégration de ClusterControl avec des scripts externes et des outils d'orchestration d'infrastructure. Nous espérons que vous apprécierez cet outil et si vous avez des commentaires sur la façon de l'améliorer, n'hésitez pas à nous le faire savoir.