Résumé :
J'ai exécuté chaque requête 10 fois chacune en utilisant l'ensemble de données de test ci-dessous.
- Un très grand ensemble de résultats de sous-requêtes (100 000 lignes)
- Lignes en double
- Lignes nulles
Pour tous les scénarios ci-dessus, à la fois IN et EXISTS effectué de manière identique.
Quelques informations sur Base de données Performance V3 utilisé pour les tests. 20 000 clients ayant 1 000 000 commandes, de sorte que chaque client est dupliqué de manière aléatoire (dans une plage de 10 à 100) dans le tableau des commandes.
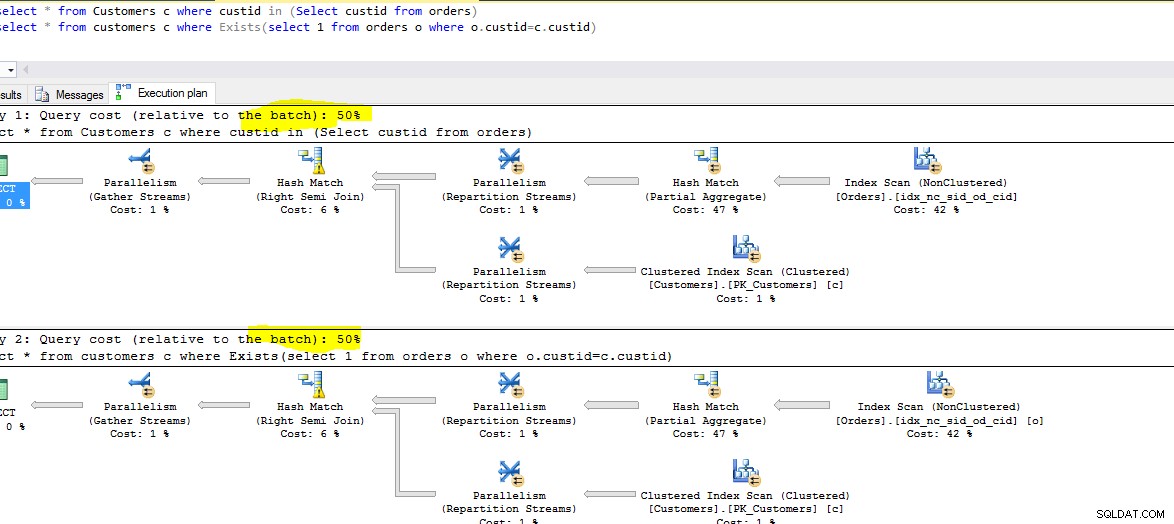
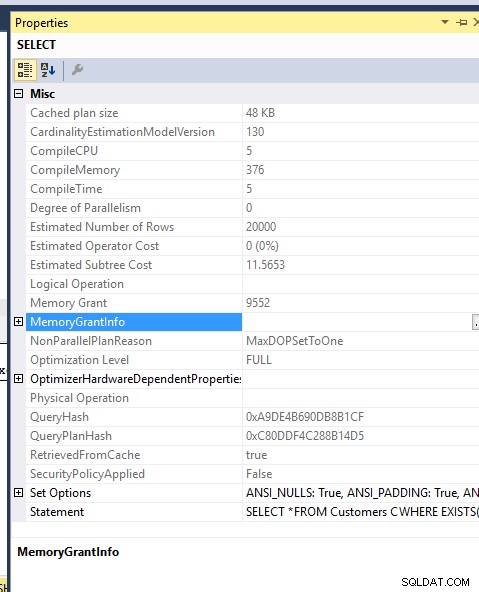
Coût d'exécution, Temps :
Vous trouverez ci-dessous une capture d'écran des deux requêtes en cours d'exécution. Observez le coût relatif de chaque requête.
Coût de la mémoire :
L'allocation de mémoire pour les deux requêtes est également la même..J'ai forcé MDOP 1 afin de ne pas les renverser sur TEMPDB..
Temps CPU, lecture :
Pour existe :
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Customers'. Scan count 1, logical reads 109, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 1, logical reads 3855, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 469 ms, elapsed time = 595 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
Pour IN :
(20000 row(s) affected)
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Customers'. Scan count 1, logical reads 109, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 1, logical reads 3855, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 547 ms, elapsed time = 669 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
Dans chaque cas, l'optimiseur est suffisamment intelligent pour réorganiser les requêtes.
J'ai tendance à utiliser EXISTS seulement si (mon avis). Un cas d'utilisation pour utiliser EXISTS est lorsque vous ne souhaitez pas renvoyer un deuxième ensemble de résultats de table.
Mettre à jour selon les requêtes de Martin Smith :
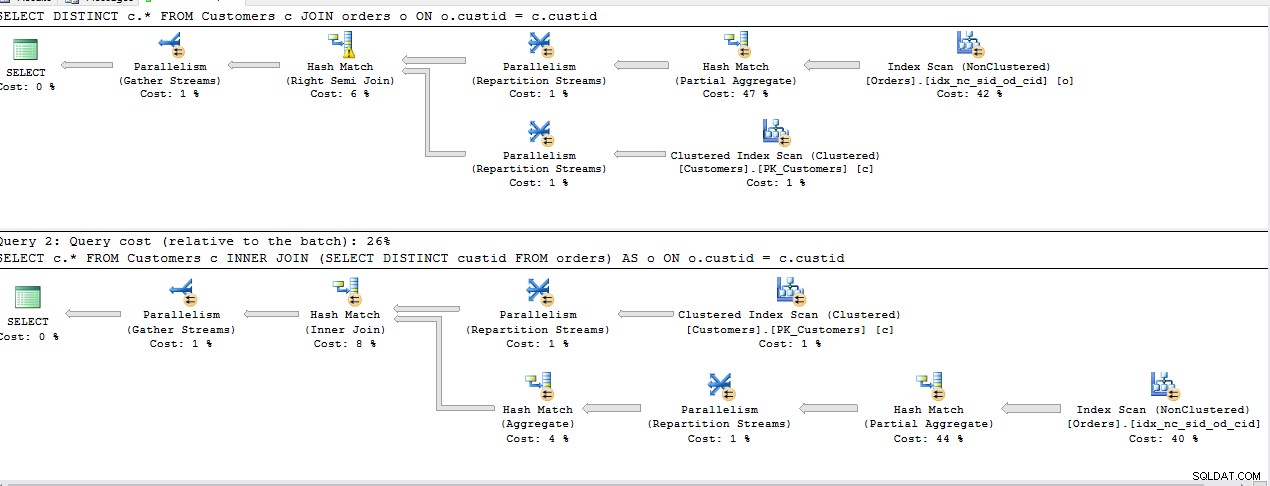
J'ai exécuté les requêtes ci-dessous pour trouver le moyen le plus efficace d'obtenir des lignes de la première table pour lesquelles une référence existe dans la deuxième table.
SELECT DISTINCT c.*
FROM Customers c
JOIN Orders o ON o.custid = c.custid
SELECT c.*
FROM Customers c
INNER JOIN (SELECT DISTINCT custid FROM Orders) AS o ON o.custid = c.custid
SELECT *
FROM Customers C
WHERE EXISTS(SELECT 1 FROM Orders o WHERE o.custid = c.custid)
SELECT *
FROM Customers c
WHERE custid IN (SELECT custid FROM Orders)
Toutes les requêtes ci-dessus partagent le même coût à l'exception du 2ème INNER JOIN , Le plan étant le même pour le reste.
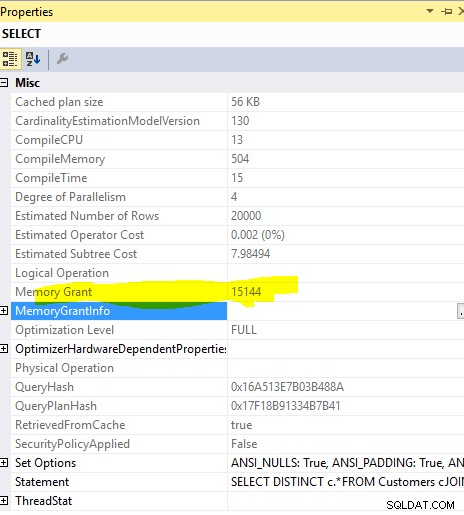
Subvention de mémoire :
Cette requête
SELECT DISTINCT c.*
FROM Customers c
JOIN Orders o ON o.custid = c.custid
allocation de mémoire requise de
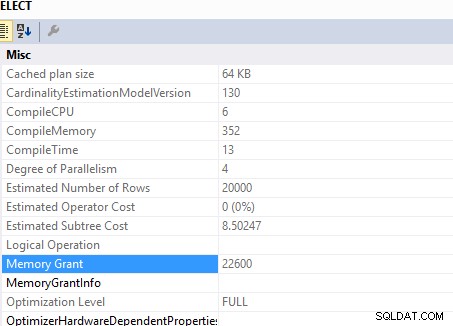
Cette requête
SELECT c.*
FROM Customers c
INNER JOIN (SELECT DISTINCT custid FROM Orders) AS o ON o.custid = c.custid
allocation de mémoire requise de ..
Temps CPU,Lis :
Pour la requête :
SELECT DISTINCT c.*
FROM Customers c
JOIN Orders o ON o.custid = c.custid
(20000 row(s) affected)
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 48, logical reads 1344, physical reads 96, read-ahead reads 1248, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 5, logical reads 3929, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Customers'. Scan count 5, logical reads 322, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1453 ms, elapsed time = 781 ms.
Pour la requête :
SELECT c.*
FROM Customers c
INNER JOIN (SELECT DISTINCT custid FROM Orders) AS o ON o.custid = c.custid
(20000 row(s) affected)
Table 'Customers'. Scan count 5, logical reads 322, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 5, logical reads 3929, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1499 ms, elapsed time = 403 ms.