Raison du problème :
TOKEN La méthode dans SSIS utilise l'implémentation de strtok fonction en C++ . J'ai recueilli ces informations en lisant le livre Microsoft® SQL Server® 2012 Integration Services
. Il est mentionné comme note à la page 113 (J'aime ce livre ! Beaucoup d'informations intéressantes. ).
J'ai cherché l'implémentation de strtok fonction et j'ai trouvé les liens suivants.
INFO :strtok() :Fonction C -- Supplément de documentation - L'exemple de code dans ce lien montre que la fonction ignore les caractères de délimitation consécutifs.
Les réponses aux questions SO suivantes indiquent que strtok est conçue pour ignorer les délimiteurs consécutifs.
comportement de strtok_s avec des délimiteurs consécutifs
Je pense que le TOKEN et TOKENCOUNT les fonctions fonctionnent comme prévu, mais si c'est ainsi que SSIS doit se comporter, cela pourrait être une question pour l'équipe Microsoft SSIS.
Message d'origine - La section ci-dessus est une mise à jour :
J'ai créé un package simple dans SSIS 2012 basé sur vos entrées de données. Comme vous l'aviez décrit dans votre question, le TOKEN fonction ne se comporte pas comme prévu. Je suis d'accord avec vous que la fonction ne semble pas fonctionner. Ce message n'est pas une réponse à votre problème d'origine.
Voici une autre façon d'écrire l'expression d'une manière relativement plus simple. Cela ne fonctionnera que si le dernier segment de votre enregistrement d'entrée aura toujours une valeur (disons A1 , B2 , C3 etc.).
L'expression peut être réécrite comme :
Cette instruction prendra l'enregistrement d'entrée comme paramètre, le délimiteur caret (^) comme second paramètre. Le troisième paramètre calcule le nombre total de segments dans les enregistrements lorsqu'ils sont divisés par le délimiteur. Si vous avez des données dans le dernier segment, vous êtes assuré d'avoir deux segments. Vous pouvez ensuite soustraire 1 pour récupérer l'avant-dernier segment.
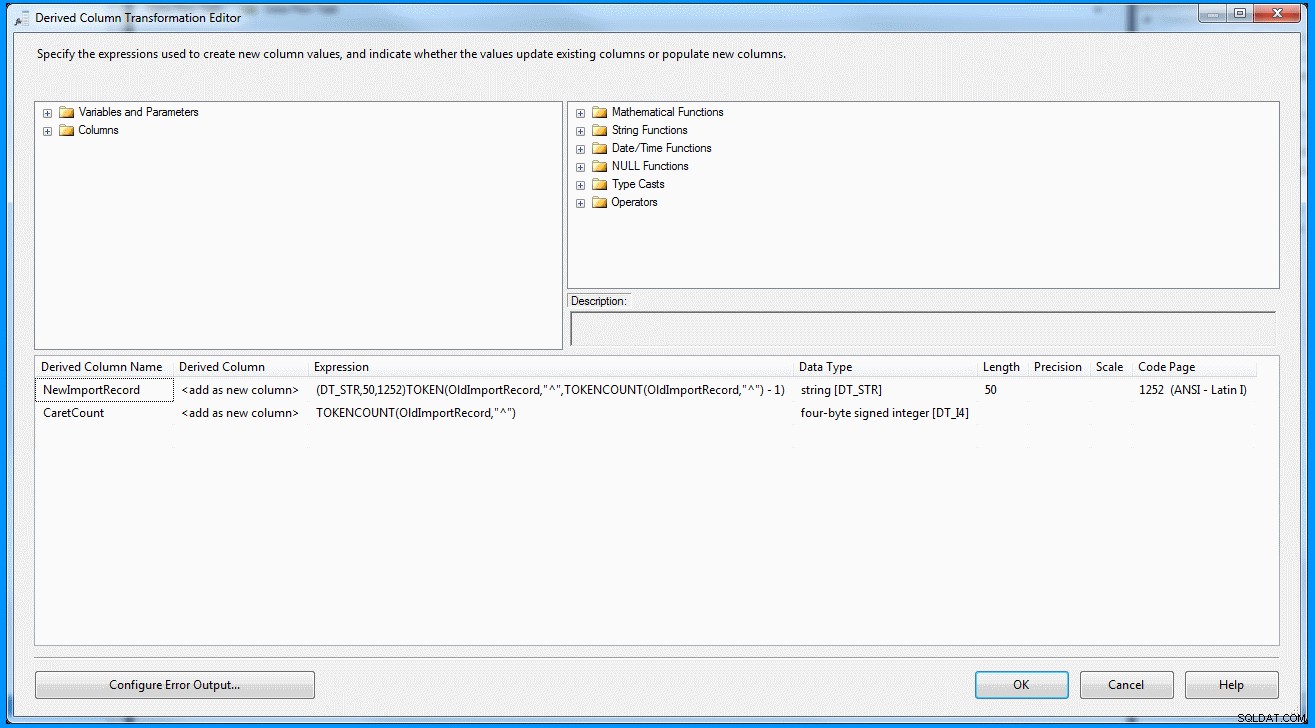
(DT_STR,50,1252)TOKEN(OldImportRecord,"^",TOKENCOUNT(OldImportRecord,"^") - 1)
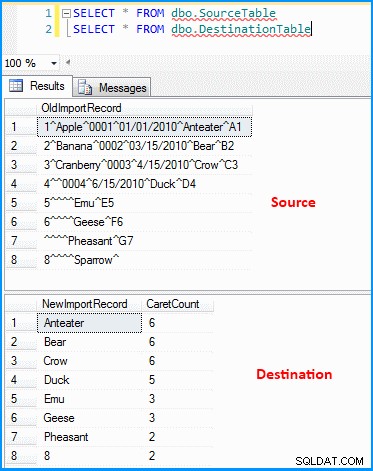
J'ai créé un package simple avec une tâche de flux de données. La source OLE DB récupère les données et la transformation dérivée analyse et divise les données selon la capture d'écran ci-dessous. La sortie est ensuite insérée dans la table de destination. Vous pouvez voir les tables source et destination dans la dernière capture d'écran. Le tableau de destination comporte deux colonnes. La première colonne stocke les données de l'avant-dernier segment et les segments comptent en fonction du délimiteur (qui, encore une fois, n'est pas correct). Vous pouvez remarquer que le dernier enregistrement n'a pas récupéré les résultats corrects. Si le dernier enregistrement n'avait pas la valeur 8 , l'expression ci-dessus échouera car l'expression sera évaluée à zéro index.
J'espère que cela aide à simplifier votre expression.
Si vous n'avez pas de nouvelles de quelqu'un d'autre, je vous recommande de consigner ce problème sur site Web Microsoft Connect .
Créer une table et remplir des scripts :
CREATE TABLE [dbo].[SourceTable](
[OldImportRecord] [varchar](50) NOT NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[DestinationTable](
[NewImportRecord] [varchar](50) NOT NULL,
[CaretCount] [int] NOT NULL
) ON [PRIMARY]
GO
INSERT INTO dbo.SourceTable (OldImportRecord) VALUES
('1^Apple^0001^01/01/2010^Anteater^A1'),
('2^Banana^0002^03/15/2010^Bear^B2'),
('3^Cranberry^0003^4/15/2010^Crow^C3'),
('4^^0004^6/15/2010^Duck^D4'),
('5^^^^Emu^E5'),
('6^^^^Geese^F6'),
('^^^^Pheasant^G7'),
('8^^^^Sparrow^');
GO
Transformation de colonne dérivée dans la tâche de flux de données :
Données dans les tables source et destination :