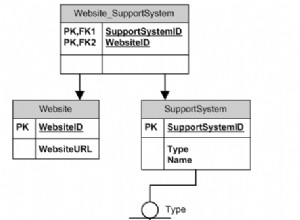
Le partitionnement n'est jamais une option pour améliorer les performances. Le mieux que vous puissiez espérer est d'avoir des performances comparables avec une table non partitionnée. Habituellement, vous obtenez une régression qui augmente avec le nombre de partitions. Pour les performances, vous avez besoin d'index, pas de partitions. Les partitions sont destinées aux opérations de gestion de données :ETL, archivage, etc. Certains prétendent que l'élimination des partitions est un gain de performances possible, mais pour tout ce que l'élimination des partitions peut donner, placer la clé d'index de tête sur la même colonne que la colonne de partitionnement donnera de bien meilleurs résultats.
Cette requête a besoin d'un index sur State . Sinon, il s'agit d'un balayage de table, et il balayera toute la table. Une analyse de table sur une table partitionnée est toujours plus lent qu'un balayage sur une table non partitionnée de même taille. L'index lui-même peut être aligné sur le même schéma de partition, mais la clé principale doit être State .
Le parallélisme n'a rien à voir avec le partitionnement, malgré l'idée fausse commune du contraire. Les analyses de plage partitionnées et non partitionnées peuvent utiliser un opérateur parallèle, ce sera la décision de l'optimiseur de requête.
Non
Un index vous aidera. Si l'index doit être aligné, il doit être partitionné. Un index non partitionné sera plus rapide qu'un index partitionné, mais l'exigence d'alignement d'index pour les opérations d'activation/désactivation ne peut pas être contournée.
Si vous envisagez le partitionnement, cela devrait être dû au fait que vous devez effectuer des opérations d'activation et de désactivation rapides pour supprimer les anciennes données au-delà de la période de la politique de rétention ou quelque chose de similaire. Pour les performances, vous devez regarder les index, pas le partitionnement.