Les mots sont plutôt logiques et vous les apprendrez assez rapidement. :)
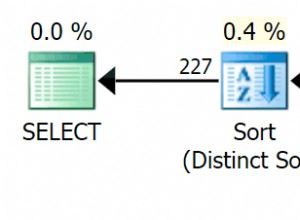
En termes simples, SEEK implique la recherche d'emplacements précis pour les enregistrements, ce que fait le serveur SQL lorsque la colonne dans laquelle vous recherchez est indexée et que votre filtre (la condition WHERE) est suffisamment précis.
SCAN signifie une plus grande plage de lignes où le planificateur d'exécution de requêtes estime qu'il est plus rapide de récupérer une plage entière plutôt que de rechercher individuellement chaque valeur.
Et oui, vous pouvez avoir plusieurs index sur le même champ, et parfois cela peut être une très bonne idée. Jouez avec les index et utilisez le planificateur d'exécution de requêtes pour déterminer ce qui se passe (raccourci dans SSMS :Ctrl + M). Vous pouvez même exécuter deux versions de la même requête et le planificateur d'exécution vous montrera facilement combien de ressources et de temps sont pris par chacune, ce qui rend l'optimisation assez facile.
Mais pour les développer un peu, disons que vous avez une table d'adresses comme celle-ci, et qu'elle contient plus d'un milliard d'enregistrements :
CREATE TABLE ADDRESS
(ADDRESS_ID INT -- CLUSTERED primary key ADRESS_PK_IDX
, PERSON_ID INT -- FOREIGN KEY, NONCLUSTERED INDEX ADDRESS_PERSON_IDX
, CITY VARCHAR(256)
, MARKED_FOR_CHECKUP BIT
, **+n^10 different other columns...**)
Maintenant, si vous voulez trouver toutes les informations d'adresse pour la personne 12345, l'index sur PERSON_ID est parfait. Étant donné que la table contient de nombreuses autres données sur la même ligne, il serait inefficace et gourmand en espace de créer un index non clusterisé pour couvrir toutes les autres colonnes ainsi que PERSON_ID. Dans ce cas, SQL Server exécutera un index SEEK sur l'index dans PERSON_ID, puis l'utilisera pour effectuer une recherche de clé sur l'index clusterisé dans ADDRESS_ID, et à partir de là, renverra toutes les données dans toutes les autres colonnes de cette même ligne.
Cependant, supposons que vous souhaitiez rechercher toutes les personnes d'une ville, mais que vous n'ayez pas besoin d'autres informations d'adresse. Cette fois, le moyen le plus efficace serait de créer un index sur CITY et d'utiliser l'option INCLUDE pour couvrir également PERSON_ID. De cette façon, une seule recherche / analyse d'index renverrait toutes les informations dont vous avez besoin sans avoir à recourir à la vérification de l'index CLUSTERED pour les données PERSON_ID sur la même ligne.
Maintenant, disons que ces deux requêtes sont nécessaires mais toujours assez lourdes à cause du milliard d'enregistrements. Mais il y a une requête spéciale qui doit être vraiment très rapide. Cette requête veut toutes les personnes dont les adresses ont été MARKED_FOR_CHECKUP et qui doivent vivre à New York (ignorez ce que signifie checkup, cela n'a pas d'importance). Maintenant, vous voudrez peut-être créer un troisième index filtré sur MARKED_FOR_CHECKUP et CITY, avec INCLUDE couvrant PERSON_ID, et avec un filtre disant CITY ='New York' et MARKED_FOR_CHECKUP =1. Cet index serait incroyablement rapide, car il ne couvre que les requêtes qui satisfont ces conditions exactes, et a donc une fraction des données à parcourir par rapport aux autres index.
(Avis de non-responsabilité ici, gardez à l'esprit que le planificateur d'exécution de requêtes n'est pas stupide, il peut utiliser plusieurs index non clusterisés ensemble pour produire les résultats corrects, donc les exemples ci-dessus peuvent ne pas être les meilleurs disponibles car il est très difficile d'imaginer quand vous auriez besoin 3 index différents couvrant la même colonne, mais je suis sûr que vous avez compris.)
Les types d'index, leurs colonnes, les colonnes incluses, les ordres de tri, les filtres, etc. dépendent entièrement de la situation. Vous devrez créer des index de couverture pour répondre à plusieurs types de requêtes différents, ainsi que des index personnalisés créés spécifiquement pour les requêtes singulières et importantes. Chaque index occupe de l'espace sur le disque dur, donc créer des index inutiles est un gaspillage et nécessite une maintenance supplémentaire chaque fois que le modèle de données change, et fait perdre du temps dans les opérations de défragmentation et de mise à jour des statistiques ... vous ne voulez donc pas simplement gifler un index sur tout soit.
Expérimentez, apprenez et déterminez ce qui convient le mieux à vos besoins.