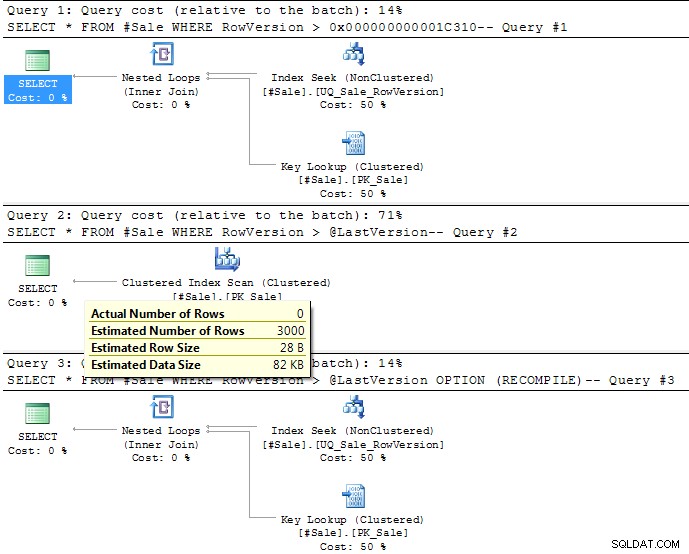
La requête 2 utilise une variable.
Au moment où le lot est compilé, SQL Server ne connaît pas la valeur de la variable et revient donc à une heuristique très similaire à OPTIMIZE FOR (UNKNOWN)
Pour > il supposera que 30 % des lignes finiront par correspondre (ou 3 000 lignes dans votre exemple de données). Cela peut être vu dans l'image du plan d'exécution ci-dessous. C'est nettement au-dessus des 12 lignes (0,12 %) qui est le point de basculement
pour cette requête si elle utilise un parcours d'index clusterisé ou une recherche d'index non clusterisé et des recherches de clé.
Vous auriez besoin d'utiliser OPTION (RECOMPILE) pour qu'il tienne compte de la valeur réelle de la variable comme indiqué dans le troisième plan ci-dessous.
Script
CREATE TABLE #Sale
(
SaleId INT IDENTITY(1, 1)
CONSTRAINT PK_Sale PRIMARY KEY,
Test1 VARCHAR(10) NULL,
RowVersion rowversion NOT NULL
CONSTRAINT UQ_Sale_RowVersion UNIQUE
)
/*A better way of populating the table!*/
INSERT INTO #Sale (Test1)
SELECT TOP 10000 NULL
FROM master..spt_values v1, master..spt_values v2
GO
SELECT *
FROM #Sale
WHERE RowVersion > 0x000000000001C310-- Query #1
DECLARE @LastVersion rowversion = 0x000000000001C310
SELECT *
FROM #Sale
WHERE RowVersion > @LastVersion-- Query #2
SELECT *
FROM #Sale
WHERE RowVersion > @LastVersion
OPTION (RECOMPILE)-- Query #3
DROP TABLE #Sale