Sur une table de test de mon côté, votre plan original ressemble à ceci.
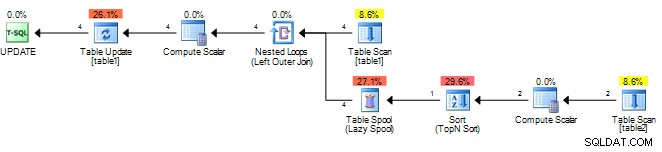
Il calcule simplement le résultat une fois et le met en cache dans un sppol puis rejoue ce résultat. Vous pouvez essayer ce qui suit pour que SQL Server considère la sous-requête comme corrélée et nécessitant une réévaluation pour chaque ligne externe.
UPDATE table1
SET table2Id = (SELECT TOP 1 table2Id
FROM table2
ORDER BY Newid(),
table1.table1Id)
Pour moi ça donne ce plan sans la bobine.
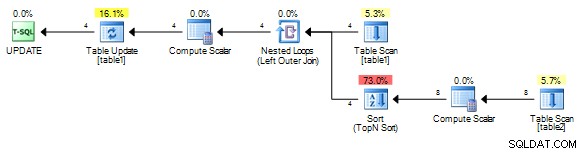
Il est important de corréler sur un champ unique de table1 cependant, même si une bobine est ajoutée, elle doit toujours être rebondie plutôt que rembobinée (rejouer le dernier résultat) car la valeur de corrélation sera différente pour chaque ligne.
Si les tables sont volumineuses, cela sera lent car le travail requis est un produit des deux lignes de la table (pour chaque ligne dans table1 il doit faire une analyse complète de table2 )