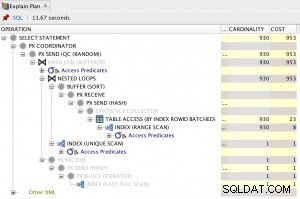
Vous pouvez (ab)utiliser MERGE
avec OUTPUT clause.
MERGE peut INSERT , UPDATE et DELETE Lignes. Dans notre cas, nous n'avons qu'à INSERT .1=0 est toujours faux, donc le NOT MATCHED BY TARGET part est toujours exécutée.En général, il pourrait y avoir d'autres branches, voir docs.WHEN MATCHED est généralement utilisé pour UPDATE;WHEN NOT MATCHED BY SOURCE est généralement utilisé pour DELETE , mais nous n'en avons pas besoin ici.
Cette forme alambiquée de MERGE équivaut à un simple INSERT , mais contrairement au simple INSERT sa OUTPUT La clause permet de faire référence aux colonnes dont nous avons besoin. Elle permet de récupérer les colonnes des tables source et destination, économisant ainsi un mappage entre les anciens et les nouveaux ID.
MERGE INTO [dbo].[Test]
USING
(
SELECT [Data]
FROM @Old AS O
) AS Src
ON 1 = 0
WHEN NOT MATCHED BY TARGET THEN
INSERT ([Data])
VALUES (Src.[Data])
OUTPUT Src.ID AS OldID, inserted.ID AS NewID
INTO @New(ID, [OtherID])
;
Concernant votre mise à jour et en vous basant sur l'ordre des IDENTITY générés valeurs.
Dans le cas simple, lorsque [dbo].[Test] a IDENTITY colonne, puis INSERT avec ORDER BY va garantir que l'IDENTITY généré les valeurs seraient dans l'ordre spécifié. Voir le point 4 dans Commander des garanties dans SQL Server . Attention, cela ne garantit pas l'ordre physique des lignes insérées, mais cela garantit l'ordre dans lequel IDENTITY les valeurs sont générées.
INSERT INTO [dbo].[Test] ([Data])
SELECT [Data]
FROM @Old
ORDER BY [RowID]
Mais, lorsque vous utilisez le OUTPUT clause :
INSERT INTO [dbo].[Test] ([Data])
OUTPUT inserted.[ID] INTO @New
SELECT [Data]
FROM @Old
ORDER BY [RowID]
les lignes dans le OUTPUT flux ne sont pas ordonnés. Au moins, à proprement parler, ORDER BY dans la requête s'applique au INSERT principal opération, mais rien n'indique quel est l'ordre de la OUTPUT . Donc, je n'essaierais pas de me fier à cela. Soit utiliser MERGE ou ajoutez une colonne supplémentaire pour stocker explicitement le mappage entre les ID.