Je suppose que la raison en est qu'ils n'ont tout simplement pas considéré cela comme une fonctionnalité prioritaire à mettre en œuvre. Il ressemble à Postgres le fait prendre en charge les deux
UNION et UNION ALL .
Si vous avez des arguments solides pour cette fonctionnalité, vous pouvez fournir des commentaires sur Connect (ou quelle que soit l'URL de son remplacement).
Empêcher l'ajout de doublons peut être utile, car une ligne en double ajoutée ultérieurement à une précédente finira presque toujours par provoquer une boucle infinie ou dépasser la limite de récursivité maximale.
Il y a pas mal d'endroits dans les Normes SQL
où le code est utilisé démontrant UNION comme ci-dessous
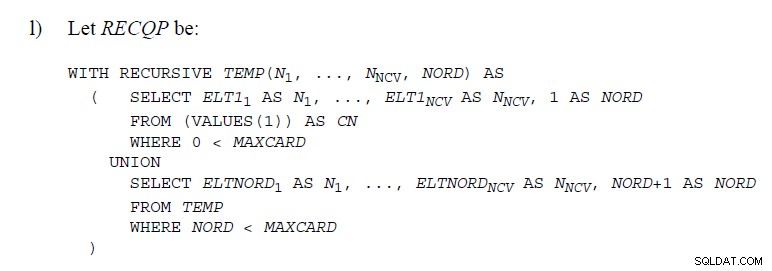
En attendant, vous pouvez facilement obtenir la même chose dans un TVF à plusieurs instructions.
Pour prendre un exemple idiot ci-dessous (Postgres Fiddle )
WITH R
AS (SELECT 0 AS N
UNION
SELECT ( N + 1 )%10
FROM R)
SELECT N
FROM R
Modification de l'UNION à UNION ALL et en ajoutant un DISTINCT à la fin ne vous sauvera pas de la récursivité infinie.
Mais vous pouvez implémenter cela comme
CREATE FUNCTION dbo.F ()
RETURNS @R TABLE(n INT PRIMARY KEY WITH (IGNORE_DUP_KEY = ON))
AS
BEGIN
INSERT INTO @R
VALUES (0); --anchor
WHILE @@ROWCOUNT > 0
BEGIN
INSERT INTO @R
SELECT ( N + 1 )%10
FROM @R
END
RETURN
END
GO
SELECT *
FROM dbo.F ()
Ce qui précède utilise IGNORE_DUP_KEY pour éliminer les doublons. Si la liste des colonnes est trop large pour être indexée, vous aurez besoin de DISTINCT et NOT EXISTS Au lieu. Vous voudrez probablement aussi un paramètre pour définir le nombre maximum de récursions et éviter les boucles infinies.