La disponibilité, l'accessibilité et la performance des données sont essentielles au succès de l'entreprise. Le réglage des performances et l'optimisation des requêtes SQL sont des pratiques délicates, mais nécessaires pour les professionnels des bases de données. Ils nécessitent d'examiner diverses collections de données à l'aide d'événements étendus, de performances, de plans d'exécution, de statistiques et d'index, pour n'en nommer que quelques-uns. Parfois, les propriétaires d'applications demandent d'augmenter les ressources système (processeur et mémoire) pour améliorer les performances du système. Cependant, vous n'aurez peut-être pas besoin de ces ressources supplémentaires et elles peuvent avoir un coût qui leur est associé. Parfois, il suffit d'apporter des améliorations mineures pour modifier le comportement de la requête.
Dans cet article, nous aborderons quelques bonnes pratiques d'optimisation des requêtes SQL à appliquer lors de l'écriture de requêtes SQL.
SELECT * vs liste de colonnes SELECT
Généralement, les développeurs utilisent l'instruction SELECT * pour lire les données d'une table. Il lit toutes les données disponibles de la colonne dans la table. Supposons qu'une table [AdventureWorks2019].[HumanResources].[Employee] stocke les données de 290 employés et que vous deviez récupérer les informations suivantes :
- Numéro d'identification national de l'employé
- DOB
- Sexe
- Date d'embauche
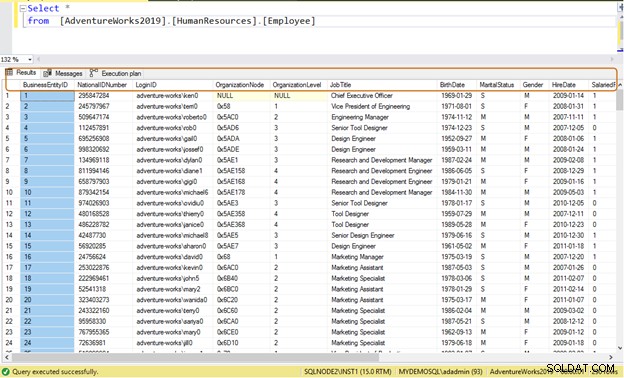
Requête inefficace : Si vous utilisez l'instruction SELECT *, elle renvoie toutes les données de la colonne pour les 290 employés.
Select * from [AdventureWorks2019].[HumanResources].[Employee]
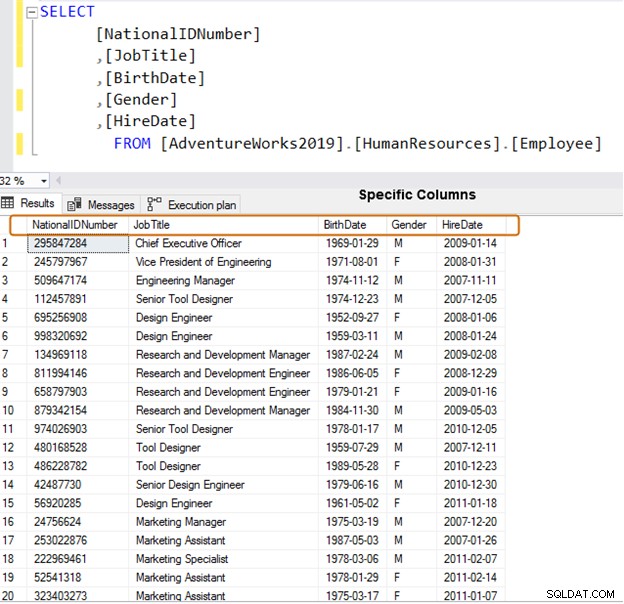
Utilisez plutôt des noms de colonne spécifiques pour la récupération des données.
SELECT [NationalIDNumber] ,[JobTitle] ,[BirthDate] ,[Gender] ,[HireDate] FROM [AdventureWorks2019].[HumanResources].[Employee]
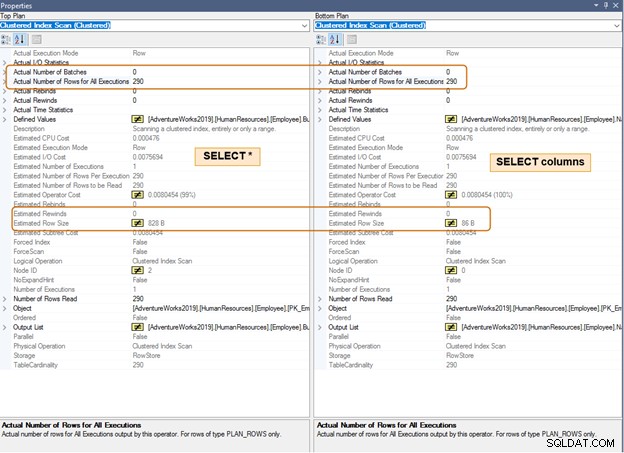
Dans le plan d'exécution ci-dessous, notez la différence dans la taille de ligne estimée pour le même nombre de lignes. Vous remarquerez également une différence de CPU et d'E/S pour un grand nombre de lignes.
Utilisation de COUNT() par rapport à EXISTS
Supposons que vous souhaitiez vérifier si un enregistrement spécifique existe dans la table SQL. Habituellement, nous utilisons COUNT (*) pour vérifier l'enregistrement, et il renvoie le nombre d'enregistrements dans la sortie.
Cependant, nous pouvons utiliser la fonction IF EXISTS() à cette fin. Pour la comparaison, j'ai activé les statistiques avant d'exécuter les requêtes.
La requête pour COUNT()
SET STATISTICS IO ON Select count(*) from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824 SET STATISTICS IO OFF
La requête pour IF EXISTS()
SET STATISTICS IO ON IF EXISTS(Select [CarrierTrackingNumber] from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824) PRINT 'YES' ELSE PRINT 'NO' SET STATISTICS IO OFF
J'ai utilisé statisticsparser pour analyser les résultats statistiques des deux requêtes. Regardez les résultats ci-dessous. La requête avec COUNT(*) a 276 lectures logiques alors que IF EXISTS() a 83 lectures logiques. Vous pouvez même obtenir une réduction plus significative des lectures logiques avec IF EXISTS(). Par conséquent, vous devez l'utiliser pour optimiser les requêtes SQL pour de meilleures performances.

Évitez d'utiliser SQL DISTINCT
Chaque fois que nous voulons des enregistrements uniques de la requête, nous utilisons habituellement la clause SQL DISTINCT. Supposons que vous avez joint deux tables ensemble et que, dans la sortie, il renvoie les lignes en double. Une solution rapide consiste à spécifier l'opérateur DISTINCT qui supprime la ligne dupliquée.
Examinons les instructions SELECT simples et comparons les plans d'exécution. La seule différence entre les deux requêtes est un opérateur DISTINCT.
SELECT SalesOrderID FROM Sales.SalesOrderDetail Go SELECT DISTINCT SalesOrderID FROM Sales.SalesOrderDetail Go
Avec l'opérateur DISTINCT, le coût de la requête est de 77 %, tandis que la requête précédente (sans DISTINCT) n'a que 23 % de coût par lot.
Vous pouvez utiliser GROUP BY, CTE ou une sous-requête pour écrire du code SQL efficace au lieu d'utiliser DISTINCT pour obtenir des valeurs distinctes à partir du jeu de résultats. De plus, vous pouvez récupérer des colonnes supplémentaires pour un ensemble de résultats distinct.
SELECT SalesOrderID FROM Sales.SalesOrderDetail Group by SalesOrderID
Utilisation des caractères génériques dans la requête SQL
Supposons que vous souhaitiez rechercher les enregistrements spécifiques contenant des noms commençant par la chaîne spécifiée. Les développeurs utilisent un caractère générique pour rechercher les enregistrements correspondants.
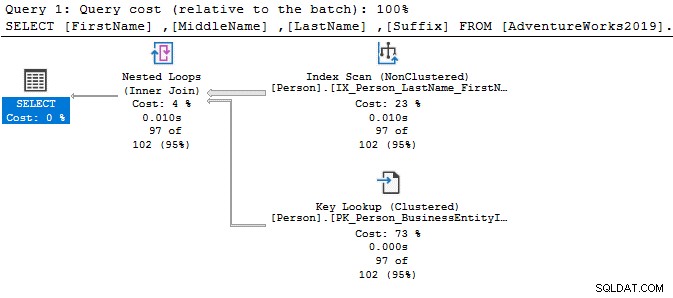
Dans la requête ci-dessous, il recherche la chaîne Ken dans la colonne du prénom. Cette requête récupère les résultats attendus de Ken dra et Ken neth. Mais, il fournit également des résultats inattendus, par exemple, Macken zie et Nken ge.
Dans le plan d'exécution, vous voyez l'analyse de l'index et la recherche de clé pour la requête ci-dessus.
Vous pouvez éviter le résultat inattendu en utilisant le caractère générique à la fin de la chaîne.
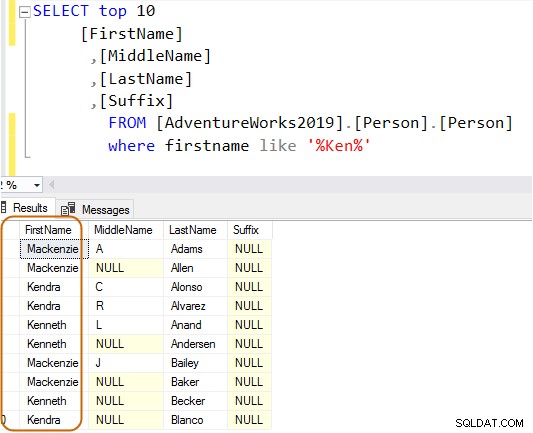
SELECT Top 10 [FirstName] ,[MiddleName] ,[LastName] ,[Suffix] FROM [AdventureWorks2019].[Person].[Person] Where firstname like 'Ken%'
Maintenant, vous obtenez le résultat filtré en fonction de vos besoins.
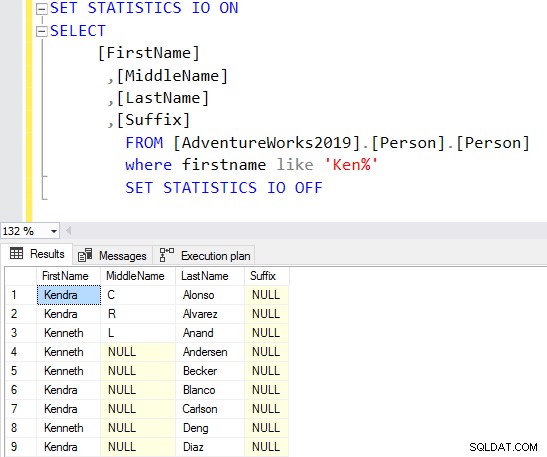
En utilisant le caractère générique au début, l'optimiseur de requête peut ne pas être en mesure d'utiliser l'index approprié. Comme le montre la capture d'écran ci-dessous, avec un caractère générique à la fin, l'optimiseur de requête suggère également un index manquant.
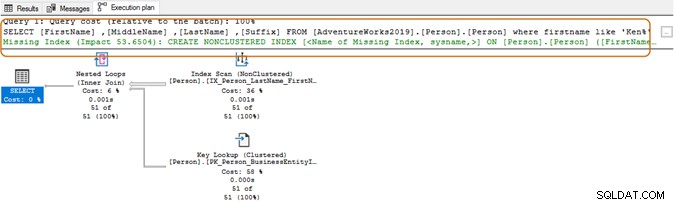
Ici, vous voudrez évaluer les exigences de votre application. Vous devriez essayer d'éviter d'utiliser un caractère générique dans les chaînes de recherche, car cela pourrait forcer l'optimiseur de requête à utiliser une analyse de table. Si la table est énorme, elle nécessiterait des ressources système plus importantes pour les E/S, le processeur et la mémoire, et pourrait entraîner des problèmes de performances pour votre requête SQL.
Utilisation des clauses WHERE et HAVING
Les clauses WHERE et HAVING sont utilisées comme filtres de lignes de données. La clause WHERE filtre les données avant d'appliquer la logique de regroupement, tandis que la clause HAVING filtre les lignes après les calculs agrégés.
Par exemple, dans la requête ci-dessous, nous utilisons un filtre de données dans la clause HAVING sans clause WHERE.
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail GROUP BY SalesOrderID HAVING SalesOrderID>30000 and SalesOrderID<55555 and SUM(UnitPrice* OrderQty)>1 Go
La requête suivante filtre d'abord les données dans la clause WHERE, puis utilise la clause HAVING pour le filtre de données agrégées.
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail where SalesOrderID>30000 and SalesOrderID<55555 GROUP BY SalesOrderID HAVING SUM(UnitPrice* OrderQty)>1000 Go
Je recommande d'utiliser la clause WHERE pour le filtrage des données et la clause HAVING pour votre filtre de données agrégées comme bonne pratique.
Utilisation des clauses IN et EXISTS
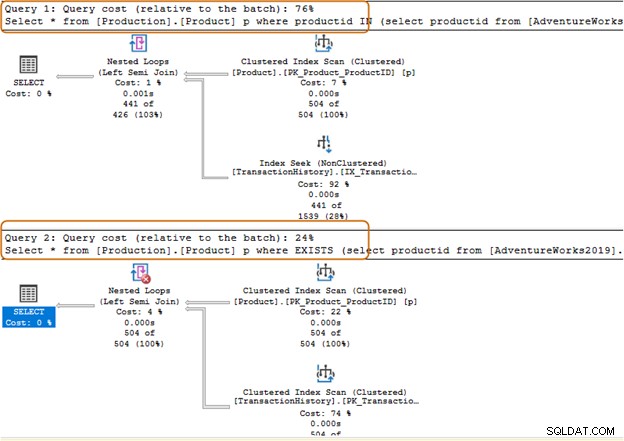
Vous devez éviter d'utiliser la clause IN-operator pour vos requêtes SQL. Par exemple, dans la requête ci-dessous, nous avons d'abord trouvé l'identifiant du produit dans la table [Production].[TransactionHistory]), puis nous avons recherché les enregistrements correspondants dans la table [Production].[Product].
Select * from [Production].[Product] p where productid IN (select productid from [AdventureWorks2019].[Production].[TransactionHistory]); Go
Dans la requête ci-dessous, nous avons remplacé la clause IN par une clause EXISTS.
Select * from [Production].[Product] p where EXISTS (select productid from [AdventureWorks2019].[Production].[TransactionHistory])
Maintenant, comparons les statistiques après avoir exécuté les deux requêtes.
La clause IN utilise 504 scans, tandis que la clause EXISTS utilise 1 scan pour la table [Production].[TransactionHistory]).
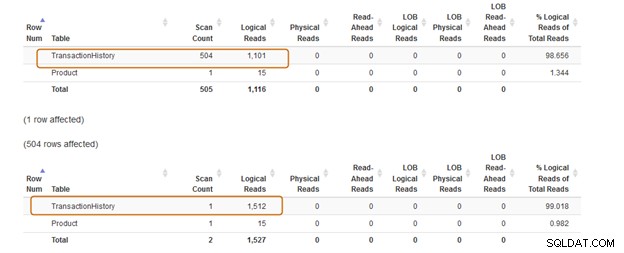
Le lot de requêtes de la clause IN coûte 74 %, tandis que le coût de la clause EXISTS est de 24 %. Par conséquent, vous devez éviter la clause IN, surtout si la sous-requête renvoie un grand ensemble de données.
Index manquants
Parfois, lorsque nous exécutons une requête SQL et recherchons le plan d'exécution réel dans SSMS, vous recevez une suggestion concernant un index susceptible d'améliorer votre requête SQL.
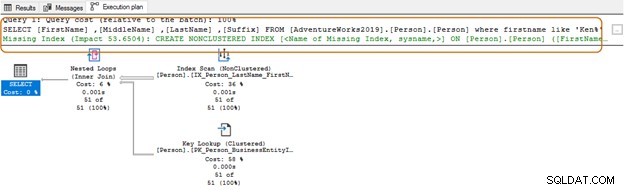
Vous pouvez également utiliser les vues de gestion dynamique pour vérifier les détails des index manquants dans votre environnement.
- sys.dm_db_missing_index_details
- sys.dm_db_missing_index_group_stats
- sys.dm_db_missing_index_groups
- sys.dm_db_missing_index_columns
Habituellement, les administrateurs de bases de données suivent les conseils de SSMS et créent les index. Cela pourrait améliorer les performances des requêtes pour le moment. Cependant, vous ne devez pas créer l'index directement en fonction de ces recommandations. Cela peut affecter les performances d'autres requêtes et ralentir vos instructions INSERT et UPDATE.
- Tout d'abord, passez en revue les index existants pour votre table SQL.
- Remarque :la surindexation et la sous-indexation nuisent toutes deux aux performances des requêtes.
- Appliquez les recommandations d'index manquantes ayant le plus d'impact après avoir examiné vos index existants et mettez-les en œuvre dans votre environnement inférieur. Si votre charge de travail fonctionne bien après la mise en œuvre du nouvel index manquant, cela vaut la peine de l'ajoutert.
Je vous suggère de vous référer à cet article pour obtenir des informations détaillées sur les bonnes pratiques d'indexation : 11 bonnes pratiques d'indexation SQL Server pour un meilleur réglage des performances.
Indices de requête
Les développeurs spécifient explicitement les indicateurs de requête dans leurs instructions t-SQL. Ces conseils de requête remplacent le comportement de l'optimiseur de requête et l'obligent à préparer un plan d'exécution basé sur votre conseil de requête. Les indicateurs de requête fréquemment utilisés sont NOLOCK, Optimize For et Recompile Merge/Hash/Loop. Ce sont des correctifs à court terme pour vos requêtes. Cependant, vous devez travailler sur l'analyse de votre requête, de vos index, de vos statistiques et de votre plan d'exécution pour une solution permanente.
Conformément aux meilleures pratiques, vous devez minimiser l'utilisation de tout indicateur de requête. Vous souhaitez utiliser les indicateurs de requête dans la requête SQL après en avoir compris les implications, et ne les utilisez pas inutilement.
Rappels d'optimisation des requêtes SQL
Comme nous en avons discuté, l'optimisation des requêtes SQL est une voie ouverte. Vous pouvez appliquer les meilleures pratiques et de petits correctifs qui peuvent grandement améliorer les performances. Tenez compte des conseils suivants pour un meilleur développement des requêtes :
- Regardez toujours les allocations de ressources système (disques, CPU, mémoire)
- Examinez vos indicateurs de trace de démarrage, vos index et vos tâches de maintenance de base de données
- Analysez votre charge de travail à l'aide d'événements étendus, d'un profileur ou d'outils de surveillance de base de données tiers
- Mettez toujours en œuvre toute solution (même si vous êtes sûr à 100 %) sur l'environnement de test en premier et analysez son impact ; une fois que vous êtes satisfait, planifiez les implémentations en production