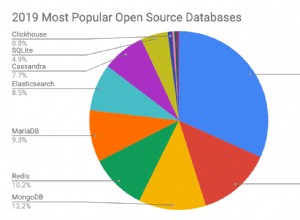
Brent Ozar, Microsoft Certified Master, a récemment discuté du parallélisme dans SQL Server, en particulier des types d'attente CXPACKET et CXCONSUMER dans son dernier volet de la série d'automne des journées de formation aux bases de données de Quest. De sa manière humoristique et accessible habituelle, Brent a démystifié les concepts de parallélisme et expliqué comment le gérer lorsque vous voyez trop de statistiques d'attente CXPACKET et CXCONSUMER.
Tout d'abord, qu'est-ce que le parallélisme et pourquoi SQL Server exécute-t-il les requêtes en parallèle ?
En termes simples, SQL Server reconnaît automatiquement qu'une requête particulière a une charge de travail importante et détermine que le travail peut être effectué plus efficacement sur plusieurs processeurs que sur un seul. Il s'agit généralement d'une décision intelligente, mais elle peut rencontrer des problèmes lorsque SQL Server n'équilibre pas la charge entre les threads effectuant la tâche.
Comprendre les types d'attente CXPACKET et CXCONSUMER
CXPACKET et CXCONSUMER sont des types d'attente qui indiquent que le travail n'est pas également équilibré. Lorsque vous verrez ces statistiques d'attente sur votre serveur, vous saurez que SQL Server exécute des requêtes en parallèle, mais ne fait pas un excellent travail pour les répartir sur les processeurs disponibles.
Chaque professionnel des bases de données connaît le concept de « coût » pour exprimer le coût d'exécution d'une requête en termes de consommation de ressources. Ces "argent de requête" sont une mesure approximative du travail et un signal important indiquant si la requête s'exécutera en parallèle ou non. Une requête peu coûteuse n'aura pas besoin de s'exécuter en parallèle, mais une requête coûteuse le fera. L'objectif est d'exécuter la requête aussi rapidement et efficacement que possible afin que la suivante puisse commencer. SQL Server désigne un thread en tant que planificateur, et ce thread, que Brent considérait comme le "robot overlord", attribuera des parties de la charge de travail parallèle aux threads de travail, ou les "robot minions".

Le parallélisme et le seigneur des robots
Brent a plongé dans une démo pour montrer comment cela fonctionne. À l'aide de la base de données Stack Overflow, il a créé une recherche de base de données à faible coût qui était très rapide en raison de la présence d'un index. Le plan d'exécution était assez simple et ne nécessitait pas de parallélisme pour s'exécuter.
Mais, lorsqu'il a introduit une recherche pour quelque chose qui n'était pas dans l'index, les choses ont changé en forçant une recherche clé pour chaque ligne de l'index clusterisé de la table. SQL Server a reconnu que cela représenterait beaucoup de travail, il a donc introduit le parallélisme et l'a indiqué comme tel avec une icône sur le plan d'exécution. Si le plan d'exécution était en trois dimensions, vous seriez en mesure de voir les multiples threads empilés, mais comme ce n'est pas le cas, vous devez afficher les statistiques pour voir des informations telles que les lectures logiques effectuées par chaque thread CPU.
Cependant, SQL Server n'a attribué cette tâche qu'à quelques threads, pas à tous. Brent a expliqué que tout ce qui se passe au-delà de l'icône parallèle se produit uniquement sur les processeurs assignés. Ainsi, les threads qui ont effectué les lectures initiales sont désormais les seuls à effectuer également les recherches de clé. Le suzerain du robot n'a demandé qu'à quelques sbires d'effectuer l'ensemble de la tâche au lieu de demander à tous les sbires de participer.
Il a poursuivi en expliquant que SQL Server doit rendre compte de ce que font les threads ainsi que suivre ce que fait le suzerain du robot. Au début, tout ce travail était représenté par une seule statistique d'attente, mais cela n'avait aucun sens car quoi qu'il arrive, le suzerain doit encore attendre pendant que tous les threads fonctionnent. Ainsi, un nouveau type d'attente a été introduit - c'était CXCONSUMER et il suit ce que fait le thread du planificateur/overlord, tandis que CXPACKET suit ce que font les threads worker/minion.
Brent est revenu sur la requête pour la rendre encore plus complexe en ajoutant un tri. Maintenant, il devient encore plus clair que le parallélisme cause un problème plutôt que de rendre l'opération plus efficace. Le travail est devenu encore plus déséquilibré entre les quelques threads de travail, et certains manquent de mémoire et se répandent sur le disque. Il a ajouté une jointure, alourdissant encore plus les cœurs de travail qui ne reçoivent aucune aide de ceux qui ne travaillent pas. Les statistiques de CXPACKET ont continué à grimper.
Que pouvez-vous faire dans cette situation ? La décision de parallélisme se produit au niveau du serveur et non au niveau de la requête, il va donc falloir quelques modifications de configuration.
Évaluer les configurations clés
Nous avons déjà appris que si le coût de la requête est supérieur à un certain niveau, cela entraîne la parallélisation de SQL Server. Les petites requêtes sont limitées à un seul thread. Mais qu'est-ce qui contrôle le seuil ? C'est une propriété appelée Cost Threshold for Parallelism (CTFP). Par défaut, si le plan d'exécution détermine que le coût est supérieur à 5 dollars de requête, la requête sera parallélisée. Bien qu'il n'y ait aucune indication sur la façon de le définir, Brent recommande un nombre supérieur à 50. Cela éliminera le parallélisme pour les requêtes triviales.
Une autre configuration est le degré maximal de parallélisme (MAXDOP) qui décrit le nombre de threads que SQL Server attribuera à la requête. La valeur par défaut ici est zéro, ce qui signifie que SQL Server peut utiliser tous les processeurs disponibles, jusqu'à 64, pour exécuter la requête. La définition de l'option MAXDOP sur 1 limite SQL Server à l'utilisation d'un seul processeur, ce qui force en fait un plan série à exécuter la requête. SQL Server recommandera une valeur MAXDOP basée sur le nombre de cœurs de serveur dont vous disposez, mais généralement, un MAXDOP inférieur est logique car il n'y aura pas beaucoup de fois où tous les cœurs seront nécessaires.
Brent a apporté des ajustements à ces deux configurations et a de nouveau exécuté sa requête. Cette fois, nous avons pu voir que davantage de cœurs étaient engagés dans l'opération parallèle. Les statistiques d'attente de CXPACKET étaient plus faibles, ce qui signifiait que la charge était mieux équilibrée sur plus de cœurs qu'auparavant.
Conseils pour lutter contre les statistiques d'attente CXPACKET et CXCONSUMER
Brent recommande les étapes suivantes si vous voyez des statistiques d'attente CXPACKET et CXCONSUMER excessives :
- Définissez le CTFP et le MAXDOP selon les meilleures pratiques du secteur, puis laissez ces paramètres cuire pendant quelques jours. Cela efface le cache du plan et oblige SQL Server à reconstruire les plans d'exécution des requêtes (réévaluer le coût).
- Apportez des améliorations à l'index qui réduiront les temps pendant lesquels les requêtes sont parallèles pour effectuer des analyses et des tris. Laissez les nouveaux index cuire, puis recherchez les requêtes qui font encore beaucoup de travail.
- Ajustez ces requêtes et laissez-les cuire pendant quelques jours.
- Enfin, si le parallélisme est toujours un problème sérieux, commencez à rechercher les requêtes spécifiques présentant des problèmes de parallélisme.
Pour encore plus d'informations, vous pouvez suivre l'intégralité de la session de formation de Brent sur les statistiques d'attente CXPACKET et CXCONSUMER à la demande ci-dessous.