SQL Server 2014 CTP1 est sorti depuis quelques semaines maintenant, et vous avez probablement vu beaucoup de presse sur les tables optimisées en mémoire et les index columnstore pouvant être mis à jour. Bien que ceux-ci méritent certainement l'attention, dans cet article, je voulais explorer la nouvelle amélioration du parallélisme SELECT … INTO. L'amélioration est l'un de ces changements de prêt-à-porter qui, à première vue, ne nécessitera pas de modifications importantes du code pour commencer à en bénéficier. Mes explorations ont été effectuées à l'aide de la version Microsoft SQL Server 2014 (CTP1) - 11.0.9120.5 (X64), Enterprise Evaluation Edition.
SÉLECTION PARALLÈLE … DANS
SQL Server 2014 introduit SELECT ... INTO en parallèle pour les bases de données et pour tester cette fonctionnalité, j'ai utilisé la base de données AdventureWorksDW2012 et une version de la table FactInternetSales qui contenait 61 847 552 lignes (j'étais responsable de l'ajout de ces lignes ; elles ne sont pas fournies avec la base de données par défaut).
Étant donné que cette fonctionnalité, à partir de CTP1, nécessite le niveau de compatibilité de la base de données 110, à des fins de test, j'ai défini la base de données sur le niveau de compatibilité 100 et exécuté la requête suivante pour mon premier test :
SELECT [ProductKey],
[OrderDateKey],
[DueDateKey],
[ShipDateKey],
[CustomerKey],
[PromotionKey],
[CurrencyKey],
[SalesTerritoryKey],
[SalesOrderNumber],
[SalesOrderLineNumber],
[RevisionNumber],
[OrderQuantity],
[UnitPrice],
[ExtendedAmount],
[UnitPriceDiscountPct],
[DiscountAmount],
[ProductStandardCost],
[TotalProductCost],
[SalesAmount],
[TaxAmt],
[Freight],
[CarrierTrackingNumber],
[CustomerPONumber],
[OrderDate],
[DueDate],
[ShipDate]
INTO dbo.FactInternetSales_V2
FROM dbo.FactInternetSales; La durée d'exécution de la requête était de 3 minutes et 19 secondes sur ma machine virtuelle de test et le plan d'exécution réel de la requête produit était le suivant :

SQL Server a utilisé un plan série, comme je m'y attendais. Notez également que ma table contenait un index columnstore non clusterisé qui a été analysé (j'ai créé cet index columnstore non clusterisé pour une utilisation avec d'autres tests, mais je vous montrerai également le plan d'exécution de la requête d'index columnstore clusterisé plus tard). Le plan n'utilisait pas le parallélisme et le Columnstore Index Scan utilisait le mode d'exécution de ligne au lieu du mode d'exécution par lots.
Ensuite, j'ai modifié le niveau de compatibilité de la base de données (et notez qu'il n'y a pas encore de niveau de compatibilité SQL Server 2014 dans CTP1):
USE [master]; GO ALTER DATABASE [AdventureWorksDW2012] SET COMPATIBILITY_LEVEL = 110; GO
J'ai supprimé la table FactInternetSales_V2, puis réexécuté mon original SELECT ... INTO opération. Cette fois, la durée d'exécution de la requête était de 1 minute et 7 secondes et le plan d'exécution réel de la requête était le suivant :
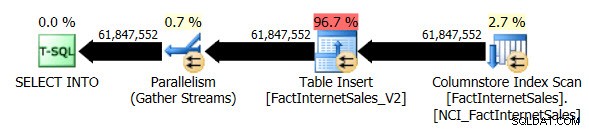
Nous avons maintenant un plan parallèle et le seul changement que j'ai dû faire était le niveau de compatibilité de la base de données pour AdventureWorksDW2012. Quatre processeurs virtuels sont alloués à ma machine virtuelle de test, et le plan d'exécution de la requête distribue les lignes sur quatre threads :

L'analyse d'index Columnstore non clusterisée, tout en utilisant le parallélisme, n'a pas utilisé le mode d'exécution par lots. Au lieu de cela, il a utilisé le mode d'exécution de ligne.
Voici un tableau pour montrer les résultats des tests jusqu'à présent :
| Type de numérisation | Niveau de compatibilité | SELECT parallèle … INTO | Mode d'exécution | Durée |
|---|---|---|---|---|
| Analyse de l'index Columnstore non clusterisé | 100 | Non | Ligne | 3:19 |
| Analyse de l'index Columnstore non clusterisé | 110 | Oui | Ligne | 1:07 |
Ainsi, comme test suivant, j'ai supprimé l'index columnstore non clusterisé et ré-exécuté le SELECT ... INTO requête utilisant à la fois le niveau de compatibilité de la base de données 100 et 110.
Le test de compatibilité de niveau 100 a duré 5 minutes et 44 secondes, et le plan suivant a été généré :
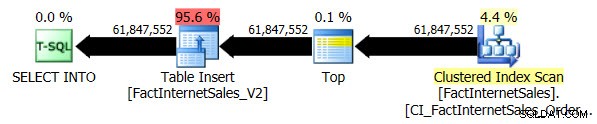
L'analyse de l'index clusterisé en série a pris 2 minutes et 25 secondes de plus que l'analyse de l'index Columnstore non clusterisé en série.
En utilisant le niveau de compatibilité 110, la requête a duré 1 minute et 55 secondes pour s'exécuter, et le plan suivant a été généré :

Semblable au test d'analyse parallèle d'index Columnstore non clusterisé, l'analyse parallèle d'index clusterisé a distribué des lignes sur quatre threads :
Le tableau suivant résume ces deux tests précités :
| Type de numérisation | Niveau de compatibilité | SELECT parallèle … INTO | Mode d'exécution | Durée |
|---|---|---|---|---|
| Analyse d'index en cluster | 100 | Non | Ligne (N/A) | 5:44 |
| Analyse d'index en cluster | 110 | Oui | Ligne (N/A) | 1:55 |
Alors je me suis interrogé sur les performances d'un index columnstore clusterisé (nouveau dans SQL Server 2014), j'ai donc supprimé les index existants et créé un index columnstore clusterisé sur la table FactInternetSales. J'ai également dû supprimer les huit contraintes de clé étrangère différentes définies sur la table avant de pouvoir créer l'index clustered columnstore.
La discussion devient quelque peu académique, puisque je compare SELECT ... INTO performances à des niveaux de compatibilité de base de données qui n'offraient pas d'index clustered columnstore en premier lieu - pas plus que les tests précédents pour les index columnstore non clusterisés au niveau de compatibilité de base de données 100 - et pourtant il est intéressant de voir et de comparer les caractéristiques de performances globales.
CREATE CLUSTERED COLUMNSTORE INDEX [CCSI_FactInternetSales] ON [dbo].[FactInternetSales] WITH (DROP_EXISTING = OFF); GO
Soit dit en passant, l'opération de création de l'index clustered columnstore sur une table de 61 847 552 millions de lignes a pris 11 minutes et 25 secondes avec quatre vCPU disponibles (dont l'opération les a tous exploités), 4 Go de RAM et un stockage invité virtuel sur les SSD OCZ Vertex. Pendant ce temps, les processeurs n'étaient pas indexés tout le temps, mais affichaient plutôt des pics et des creux (un échantillon de 60 secondes d'activité du processeur illustré ci-dessous) :
Après la création de l'index clustered columnstore, j'ai ré-exécuté les deux SELECT ... INTO essais. Le test de niveau de compatibilité 100 a pris 3 minutes et 22 secondes pour s'exécuter, et le plan était un plan en série comme prévu (je montre la version SQL Server Management Studio du plan depuis l'analyse de l'index Columnstore en cluster, à partir de SQL Server 2014 CTP1 , n'est pas encore entièrement reconnu par Plan Explorer) :

Ensuite, j'ai changé le niveau de compatibilité de la base de données à 110 et j'ai relancé le test, qui cette fois la requête a pris 1 minute et 11 secondes et avait le plan d'exécution réel suivant :

Le plan distribuait les lignes sur quatre threads et, tout comme l'index columnstore non clusterisé, le mode d'exécution de l'analyse de l'index columnstore clusterisé était la ligne et non le lot.
Le tableau suivant résume tous les tests de ce poste (par ordre de durée, de bas en haut) :
| Type de numérisation | Niveau de compatibilité | SELECT parallèle … INTO | Mode d'exécution | Durée |
|---|---|---|---|---|
| Analyse de l'index Columnstore non clusterisé | 110 | Oui | Ligne | 1:07 |
| Analyse d'index clustered Columnstore | 110 | Oui | Ligne | 1:11 |
| Analyse d'index en cluster | 110 | Oui | Ligne (N/A) | 1:55 |
| Analyse de l'index Columnstore non clusterisé | 100 | Non | Ligne | 3:19 |
| Analyse d'index clustered Columnstore | 100 | Non | Ligne | 3:22 |
| Analyse d'index en cluster | 100 | Non | Ligne (N/A) | 5:44 |
Quelques remarques :
- Je ne sais pas si la différence entre un
SELECT ... INTOL'opération sur un index columnstore non clusterisé par rapport à un index columnstore clusterisé est statistiquement significative. J'aurais besoin de faire plus de tests, mais je pense que j'attendrais pour les effectuer jusqu'à RTM. - Je peux dire en toute sécurité que le parallèle
SELECT ... INTOa surpassé de manière significative les équivalents en série dans un index clusterisé, un columnstore non clusterisé et des tests d'index clustered columnstore.
Il convient de mentionner que ces résultats concernent une version CTP du produit, et mes tests doivent être considérés comme quelque chose qui pourrait changer de comportement par RTM - donc j'étais moins intéressé par les durées autonomes par rapport à la façon dont ces durées se comparaient entre série et parallèle conditions.
Certaines fonctionnalités de performance nécessitent une refactorisation importante - mais pour le SELECT ... INTO amélioration, tout ce que j'avais à faire était d'augmenter le niveau de compatibilité de la base de données afin de commencer à voir les avantages, ce qui est certainement quelque chose que j'apprécie.