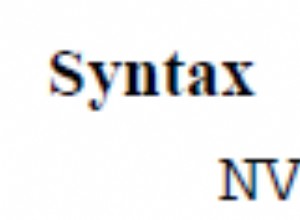Vous trouverez ci-dessous cinq options pour renvoyer des lignes contenant des lettres majuscules dans SQL Server.
Exemple de données
Supposons que nous ayons un tableau avec les données suivantes :
SELECT c1 FROM t1;Résultat :
+----------------+ | c1 | |----------------| | CAFÉ | | Café | | café | | 1café | | eCafé | | James Bond 007 | | JB 007 | | 007 | | NULL | | | | É | | É 123 | | é | | é 123 | | ø | | Ø | +----------------+
Nous pouvons utiliser les méthodes suivantes pour renvoyer les lignes contenant des lettres majuscules.
Option 1 :Comparer avec LOWER() Chaîne
Nous pouvons utiliser le LOWER() fonction pour comparer la valeur d'origine à son équivalent en minuscule :
SELECT c1 FROM t1
WHERE LOWER(c1) COLLATE Latin1_General_CS_AS <> c1;Résultat :
+----------------+ | c1 | |----------------| | CAFÉ | | Café | | eCafé | | James Bond 007 | | JB 007 | | É | | É 123 | | Ø | +----------------+
En utilisant le différent de (<> ) opérateur (vous pouvez également utiliser != au lieu de <> si vous préférez), nous renvoyons uniquement les lignes qui sont différentes de leurs équivalents en minuscules. La raison pour laquelle nous faisons cela est que, si une valeur est identique à son équivalent en minuscules, alors elle était déjà en minuscules au départ (et nous ne voulons pas la renvoyer).
Nous utilisons également COLLATE Latin1_General_CS_AS pour spécifier explicitement un classement sensible à la casse (et sensible aux accents). Sans cela, vous pourriez obtenir des résultats inattendus, selon le classement utilisé sur votre système.
Option 2 : Comparer avec les caractères réels
Une autre option consiste à utiliser le LIKE opérateur et spécifiez les caractères majuscules réels que nous voulons faire correspondre :
SELECT c1 FROM t1
WHERE c1 LIKE '%[ABCDEFGHIJKLMNOPQRSTUVWXYZ]%'
COLLATE Latin1_General_CS_AS;Résultat :
+----------------+ | c1 | |----------------| | CAFÉ | | Café | | eCafé | | James Bond 007 | | JB 007 | +----------------+
Dans ce cas, moins de lignes sont renvoyées que dans l'exemple précédent. C'est parce que je n'ai pas spécifié de caractères comme É et Ø , qui ont été renvoyés dans l'exemple précédent. Notre résultat contient É mais cette ligne n'a été renvoyée que parce qu'elle contient également d'autres caractères majuscules qui font correspondance.
Par conséquent, cette option est plus limitée que la précédente, mais elle vous offre plus de contrôle sur les caractères que vous souhaitez faire correspondre.
Option 3 :Comparer à une plage de caractères
Nous pouvons également spécifier la plage de caractères que nous voulons faire correspondre :
SELECT * FROM t1
WHERE c1 LIKE '%[A-Z]%'
COLLATE Latin1_General_100_BIN2;Résultat :
+----------------+ | c1 | |----------------| | CAFÉ | | Café | | eCafé | | James Bond 007 | | JB 007 | +----------------+
Dans ce cas, j'ai utilisé une collation binaire (Latin1_General_100_BIN2 ). J'ai fait cela parce que les classements binaires trient chaque cas séparément (comme ceci :AB....YZ...ab...yz ).
D'autres classements ont tendance à mélanger les lettres majuscules et minuscules (comme ceci :AaBb...YyZz ), qui correspondrait donc à la fois aux caractères majuscules et minuscules.
Option 4 : Rechercher la première instance d'un caractère majuscule
Une autre façon de le faire est d'utiliser le PATINDEX() fonction :
SELECT * FROM t1
WHERE PATINDEX('%[ABCDEFGHIJKLMNOPQRSTUVWXYZ]%', c1
COLLATE Latin1_General_CS_AS) > 0;Résultat :
+----------------+ | c1 | |----------------| | CAFÉ | | Café | | eCafé | | James Bond 007 | | JB 007 | +----------------+
Dans cet exemple, nous spécifions les caractères exacts que nous voulons faire correspondre, et donc dans ce cas, nous n'avons pas obtenu les lignes avec des caractères like É et Ø (autre que celui qui contient également d'autres caractères correspondants).
L'un des avantages de cette technique est que nous pouvons l'utiliser pour ignorer le premier caractère (ou le nombre de caractères spécifié) si nous le souhaitons :
SELECT * FROM t1
WHERE PATINDEX('%[ABCDEFGHIJKLMNOPQRSTUVWXYZ]%', c1
COLLATE Latin1_General_CS_AS) > 1;Résultat :
Time: 0.472s +-------+ | c1 | |-------| | eCafé | +-------+
Par conséquent, nous pouvons renvoyer toutes les lignes contenant des caractères majuscules, mais dont le premier caractère n'est pas en majuscule.
C'est parce que PATINDEX() renvoie la position de départ de la première occurrence du motif (dans notre cas, le motif est une liste de caractères majuscules). Si la position de départ de la première occurrence est supérieure à 1, alors le premier caractère n'est pas dans notre liste de caractères majuscules.
Option 5 :Rechercher la première instance en fonction d'une plage
Nous pouvons également utiliser PATINDEX() avec une plage :
SELECT * FROM t1
WHERE PATINDEX('%[A-Z]%', c1
COLLATE Latin1_General_100_BIN2) > 1;Résultat :
+-------+ | c1 | |-------| | eCafé | +-------+
J'ai de nouveau utilisé un classement binaire (comme avec l'autre exemple de plage).