Il n'y a aucune différence.
Raison :
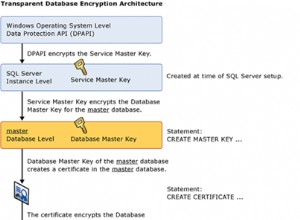
Les livres en ligne indiquent "
COUNT ( { [ [ ALL | DISTINCT ] expression ] | * } )"
"1" est une expression non nulle :c'est donc la même chose que COUNT(*) .L'optimiseur le reconnaît pour ce qu'il est :trivial.
Identique à EXISTS (SELECT * ... ou EXISTS (SELECT 1 ...
Exemple :
SELECT COUNT(1) FROM dbo.tab800krows
SELECT COUNT(1),FKID FROM dbo.tab800krows GROUP BY FKID
SELECT COUNT(*) FROM dbo.tab800krows
SELECT COUNT(*),FKID FROM dbo.tab800krows GROUP BY FKID
Même IO, même plan, les travaux
Edit, août 2011
Question similaire sur DBA.SE.
Edit, décembre 2011
COUNT(*) est spécifiquement mentionné dans ANSI-92 (recherchez "Scalar expressions 125 ")
Cas :
a) Si COUNT(*) est spécifié, alors le résultat est la cardinalité de T.
Autrement dit, la norme ANSI le reconnaît comme saignant évident ce que vous voulez dire. COUNT(1) a été optimisé par les fournisseurs de SGBDR parce que de cette superstition. Sinon, il serait évalué selon ANSI
b) Sinon, soit TX le tableau à une seule colonne qui résulte de l'application de l'
à chaque ligne de T et de l'élimination des valeurs nulles. Si une ou plusieurs valeurs nulles sont éliminées, alors une condition de complétion est levée :avertissement-