L'utilisation du cluster Galera est un excellent moyen de créer un environnement hautement disponible pour MySQL ou MariaDB. Il s'agit d'un environnement de cluster sans partage qui peut être mis à l'échelle même au-delà de 12 à 15 nœuds. Galera a cependant certaines limites. Il brille dans les environnements à faible latence et même s'il peut être utilisé sur le WAN, les performances sont limitées par la latence du réseau. Les performances de Galera peuvent également être affectées si l'un des nœuds commence à se comporter de manière incorrecte. Par exemple, une charge excessive sur l'un des nœuds peut le ralentir, entraînant un traitement plus lent des écritures et cela aura un impact sur tous les autres nœuds du cluster. D'autre part, il est tout à fait impossible de gérer une entreprise sans analyser vos données. Une telle analyse nécessite généralement l'exécution de requêtes lourdes, ce qui est assez différent d'une charge de travail OLTP. Dans cet article de blog, nous discuterons d'un moyen simple d'exécuter des requêtes analytiques pour les données stockées dans Galera Cluster pour MySQL ou MariaDB, d'une manière qui n'affecte pas les performances du cluster principal.
Comment exécuter des requêtes analytiques sur Galera Cluster ?
Comme nous l'avons dit, exécuter des requêtes longues directement sur un cluster Galera est faisable, mais ce n'est peut-être pas une si bonne idée. Selon le matériel, cela peut être une solution acceptable (si vous utilisez un matériel puissant et que vous n'exécuterez pas une charge de travail analytique multithread) mais même si l'utilisation du processeur ne sera pas un problème, le fait que l'un des nœuds aura une charge de travail mixte ( OLTP et OLAP) poseront à eux seuls des problèmes de performances. Les requêtes OLAP supprimeront les données requises pour votre charge de travail OLTP du pool de mémoire tampon, ce qui ralentira vos requêtes OLTP. Heureusement, il existe un moyen simple mais efficace de séparer la charge de travail analytique des requêtes régulières :un esclave de réplication asynchrone.
L'esclave de réplication est une solution très simple - tout ce dont vous avez besoin est juste un autre hôte qui peut être provisionné et la réplication asynchrone doit être configurée à partir de Galera Cluster vers ce nœud. Avec la réplication asynchrone, l'esclave n'aura aucun impact sur le reste du cluster. Peu importe s'il est fortement chargé, utilise un matériel différent (moins puissant), il continuera simplement à se répliquer à partir du cluster principal. Dans le pire des cas, l'esclave de réplication commencera à être à la traîne, mais il vous appartiendra ensuite d'implémenter une réplication multithread ou, éventuellement, d'augmenter l'échelle de l'esclave de réplication.
Une fois que l'esclave de réplication est opérationnel, vous devez exécuter les requêtes les plus lourdes dessus et décharger le cluster Galera. Cela peut être fait de plusieurs manières, en fonction de votre configuration et de votre environnement. Si vous utilisez ProxySQL, vous pouvez facilement diriger les requêtes vers l'esclave analytique en fonction de l'hôte source, de l'utilisateur, du schéma ou même de la requête elle-même. Sinon, il appartiendra à votre application d'envoyer les requêtes analytiques au bon hébergeur.
La configuration d'un esclave de réplication n'est pas très complexe, mais cela peut toujours être délicat si vous ne maîtrisez pas MySQL et des outils comme xtrabackup. L'ensemble du processus consisterait à configurer le référentiel sur un nouveau serveur et à installer la base de données MySQL. Ensuite, vous devrez provisionner cet hôte en utilisant les données du cluster Galera. Vous pouvez utiliser xtrabackup pour cela, mais d'autres outils comme mydumper/myloader ou même mysqldump fonctionneront également (tant que vous les exécutez correctement). Une fois les données là, vous devrez configurer la réplication entre un nœud Galera maître et l'esclave de réplication. Enfin, vous devrez reconfigurer votre couche proxy pour inclure le nouvel esclave et acheminer le trafic vers celui-ci ou apporter des modifications à la manière dont votre application se connecte à la base de données afin de rediriger une partie de la charge vers l'esclave de réplication.
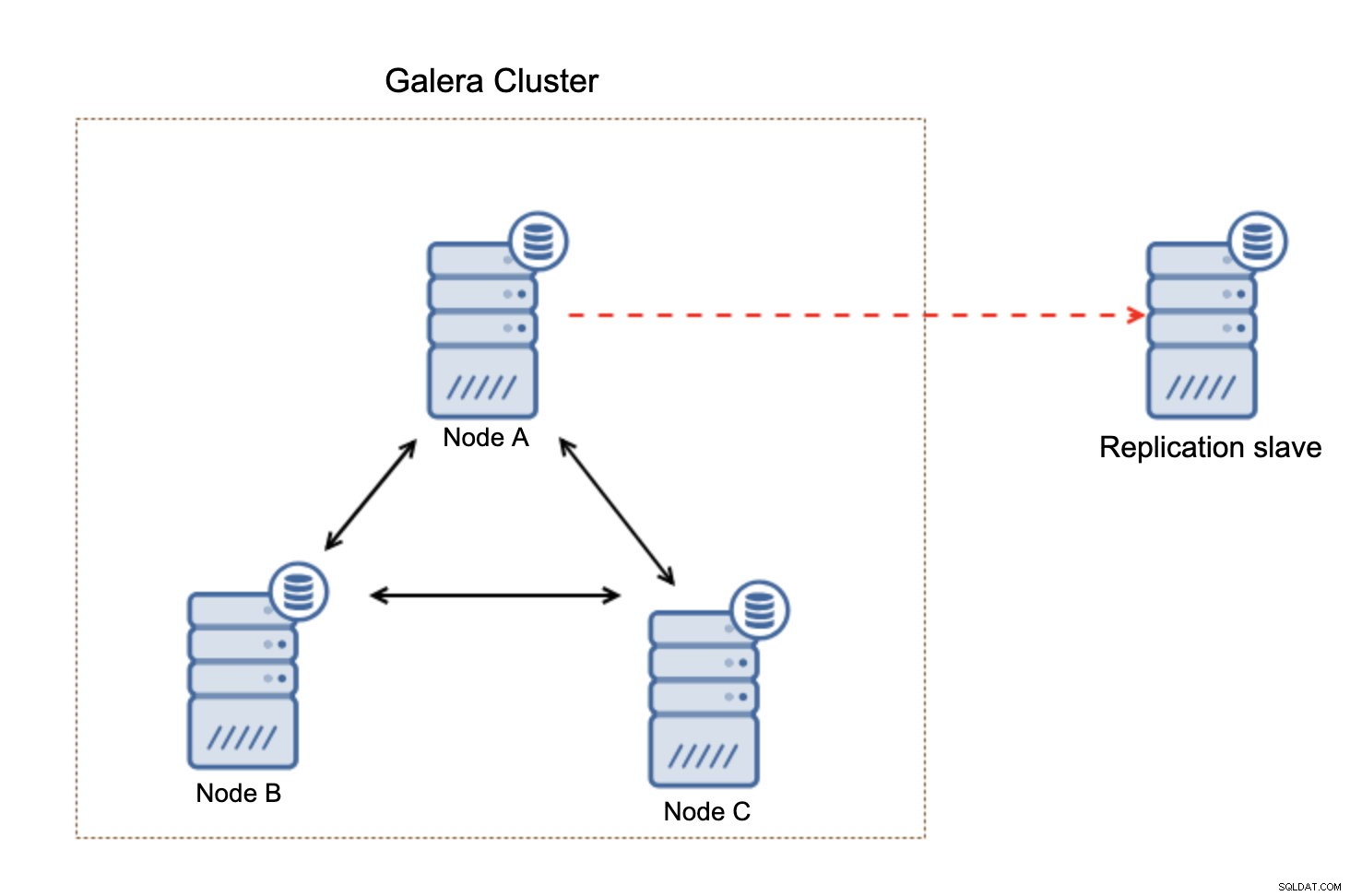
Ce qu'il est important de garder à l'esprit, c'est que cette configuration n'est pas résiliente. Si le nœud Galera "maître" tombe en panne, le lien de réplication sera rompu et une action manuelle sera nécessaire pour asservir la réplique à un autre nœud maître du cluster Galera.
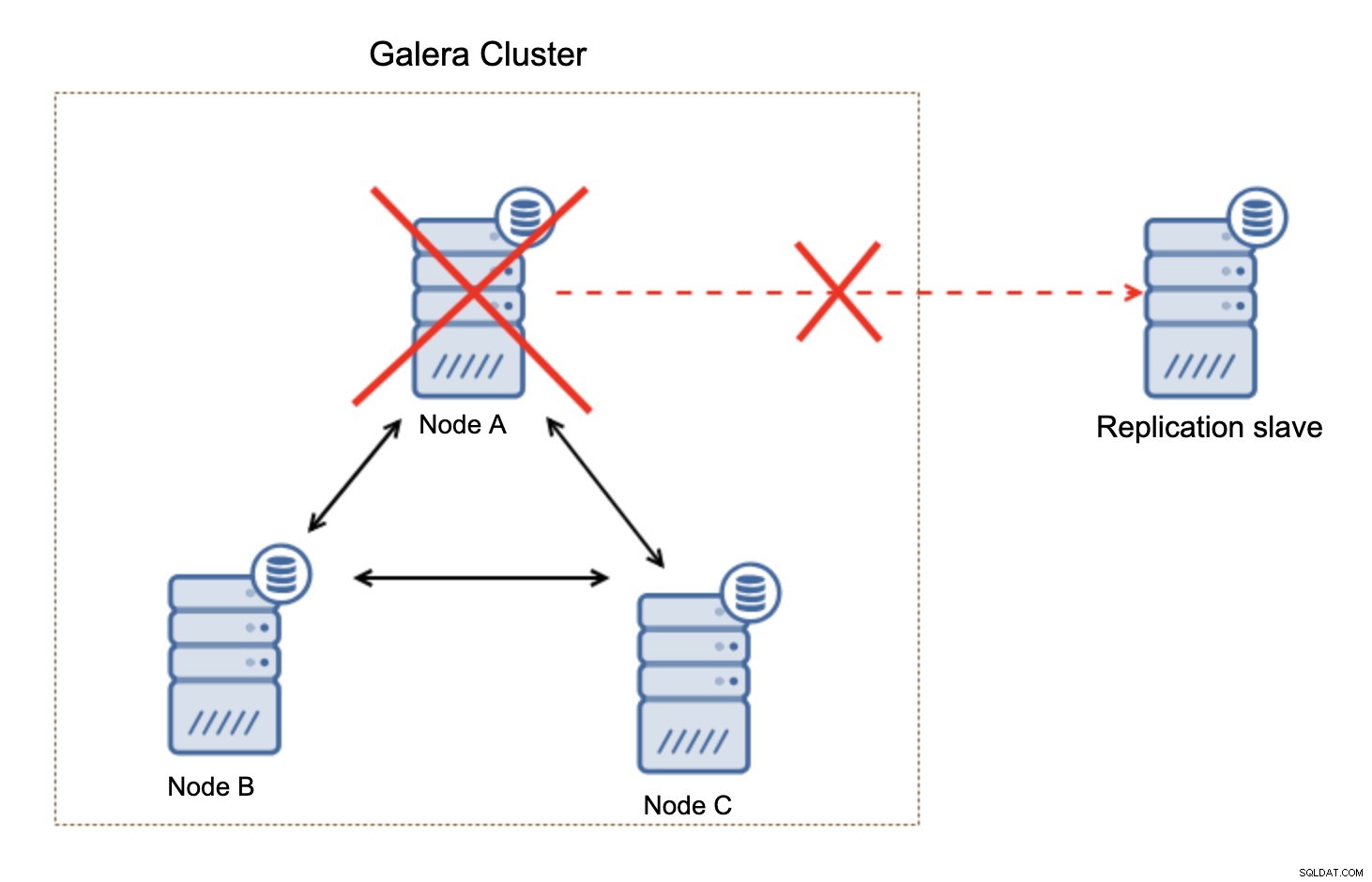
Ce n'est pas un gros problème, surtout si vous utilisez la réplication avec GTID (Global Transaction ID) mais vous devez identifier que la réplication est cassée et ensuite prendre l'action manuelle.
Comment configurer l'esclave asynchrone de Galera Cluster à l'aide de ClusterControl ?
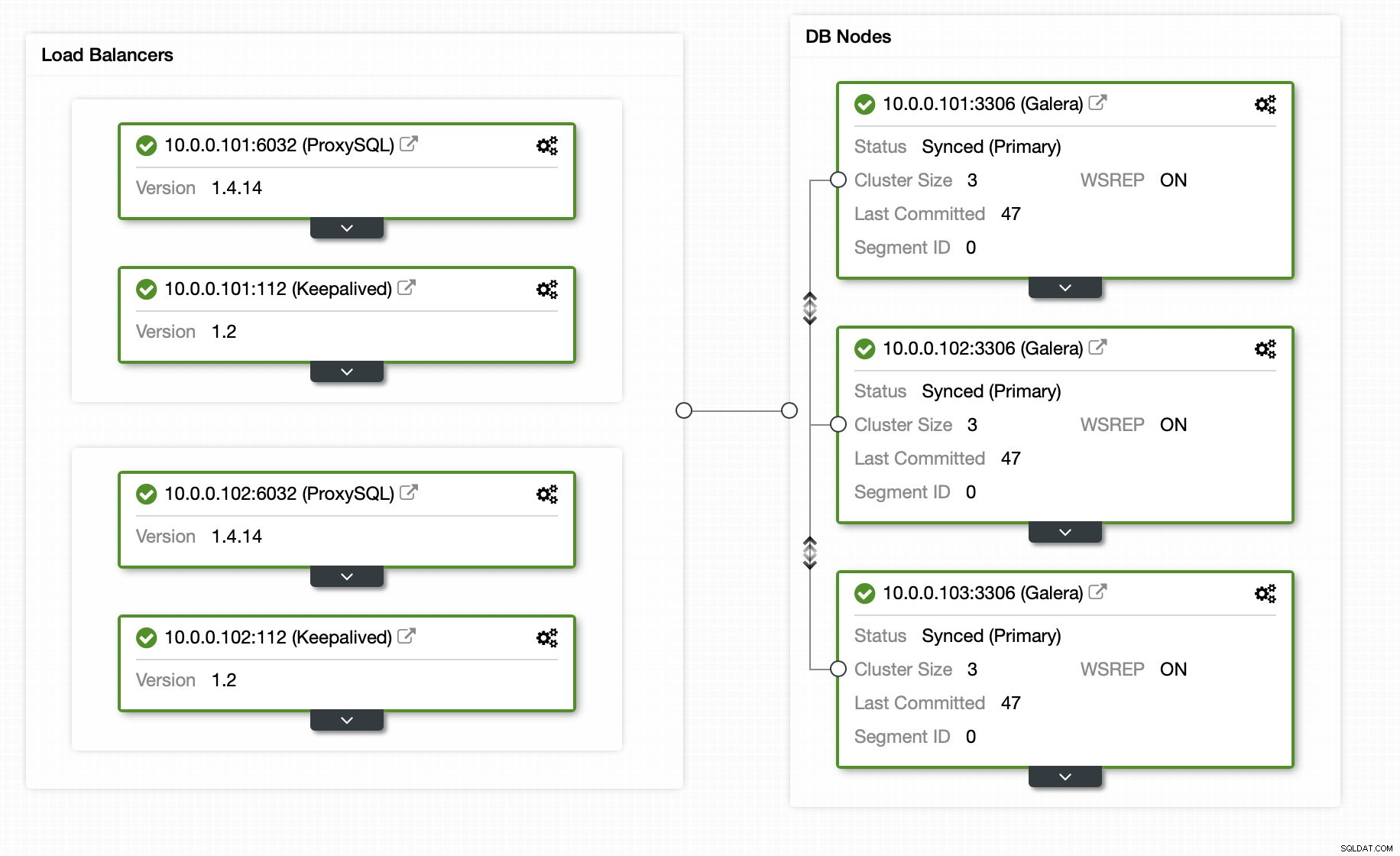
Heureusement, si vous utilisez ClusterControl, l'ensemble du processus peut être automatisé et ne nécessite qu'une poignée de clics. L'état initial a déjà été configuré à l'aide de ClusterControl - un cluster Galera à 3 nœuds avec 2 nœuds ProxySQL et 2 nœuds Keepalived pour une haute disponibilité de la base de données et de la couche proxy.
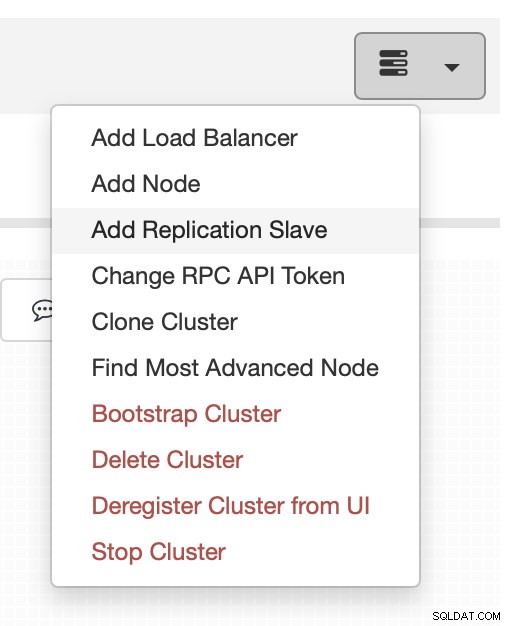
L'ajout de l'esclave de réplication est à portée de clic :
La réplication nécessite évidemment l'activation des journaux binaires. Si vous n'avez pas activé les binlogs sur vos nœuds Galera, vous pouvez également le faire à partir du ClusterControl. N'oubliez pas que l'activation des journaux binaires nécessitera un redémarrage du nœud pour appliquer les modifications de configuration.
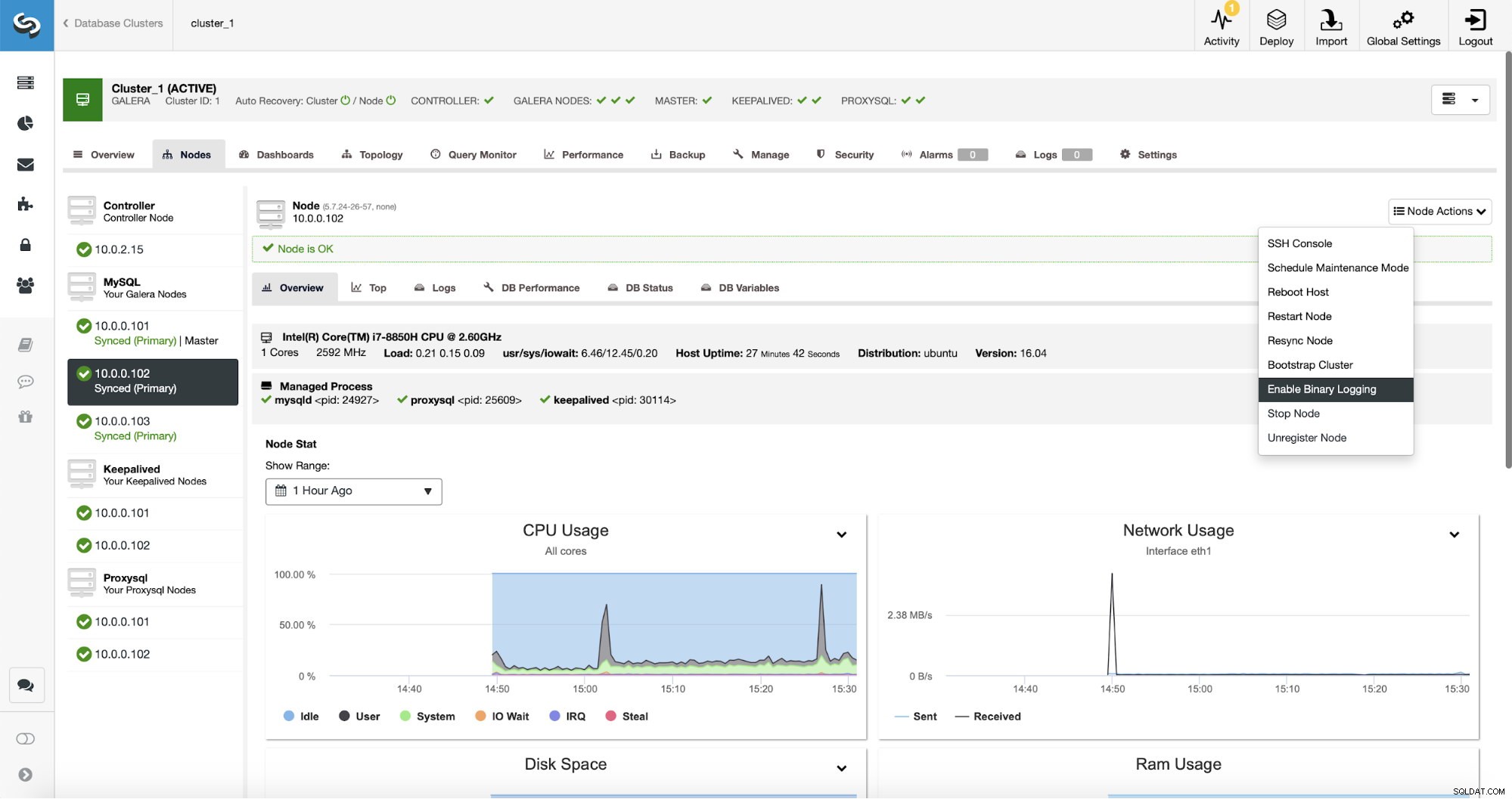
Même si un nœud du cluster a des journaux binaires activés (marqués comme "Maître" sur la capture d'écran ci-dessus), il est toujours bon d'activer la journalisation binaire sur au moins un nœud supplémentaire. ClusterControl peut automatiquement basculer l'esclave de réplication après avoir détecté que le nœud maître Galera est tombé en panne, mais pour cela, un autre nœud maître avec les journaux binaires activés est requis ou il n'aura rien sur lequel basculer.
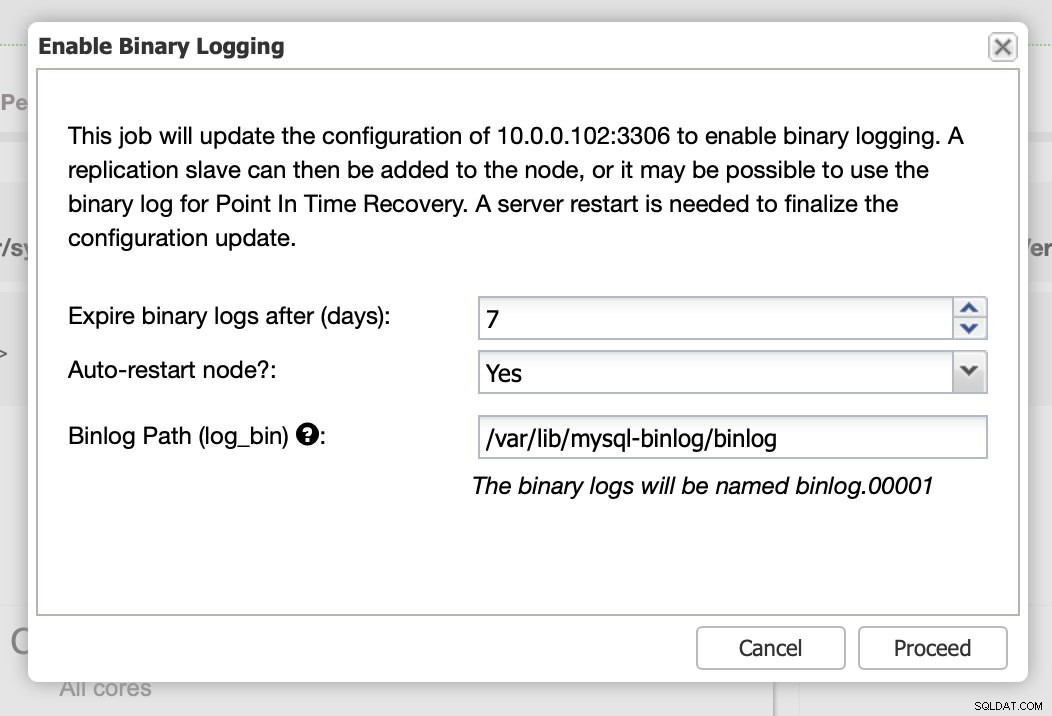
Comme nous l'avons indiqué, l'activation des journaux binaires nécessite un redémarrage. Vous pouvez soit l'exécuter immédiatement, soit simplement apporter les modifications de configuration et effectuer le redémarrage à un autre moment.
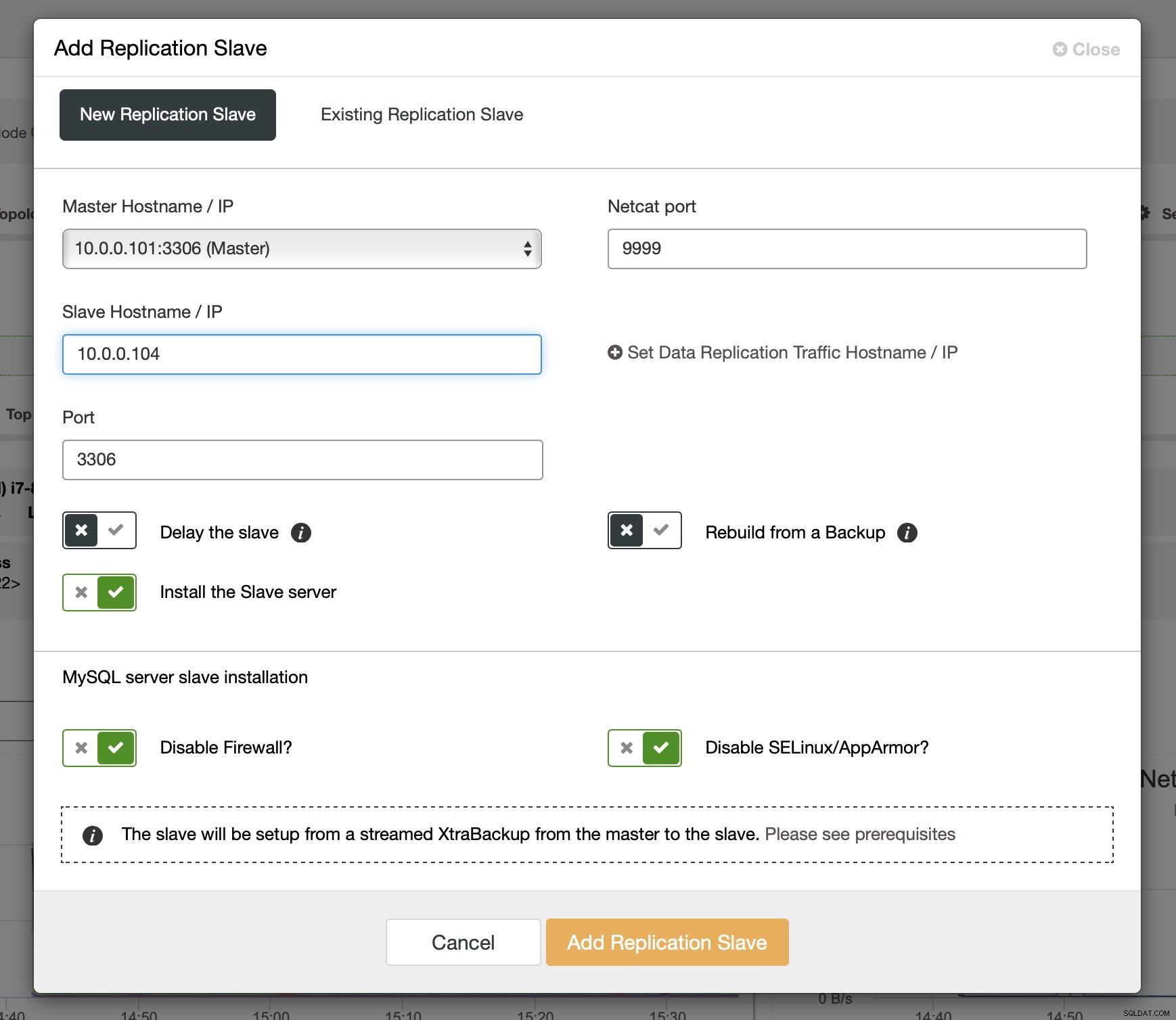
Une fois les binlogs activés sur certains des nœuds Galera, vous pouvez procéder à l'ajout de l'esclave de réplication. Dans la boîte de dialogue, vous devez choisir l'hôte maître, transmettre le nom d'hôte ou l'adresse IP de l'esclave. Si vous avez des sauvegardes récentes à portée de main (ce que vous devriez faire), vous pouvez en utiliser une pour provisionner l'esclave. Sinon, ClusterControl le provisionnera à l'aide de xtrabackup - toutes les données de base récentes seront transmises à l'esclave, puis la réplication sera configurée.
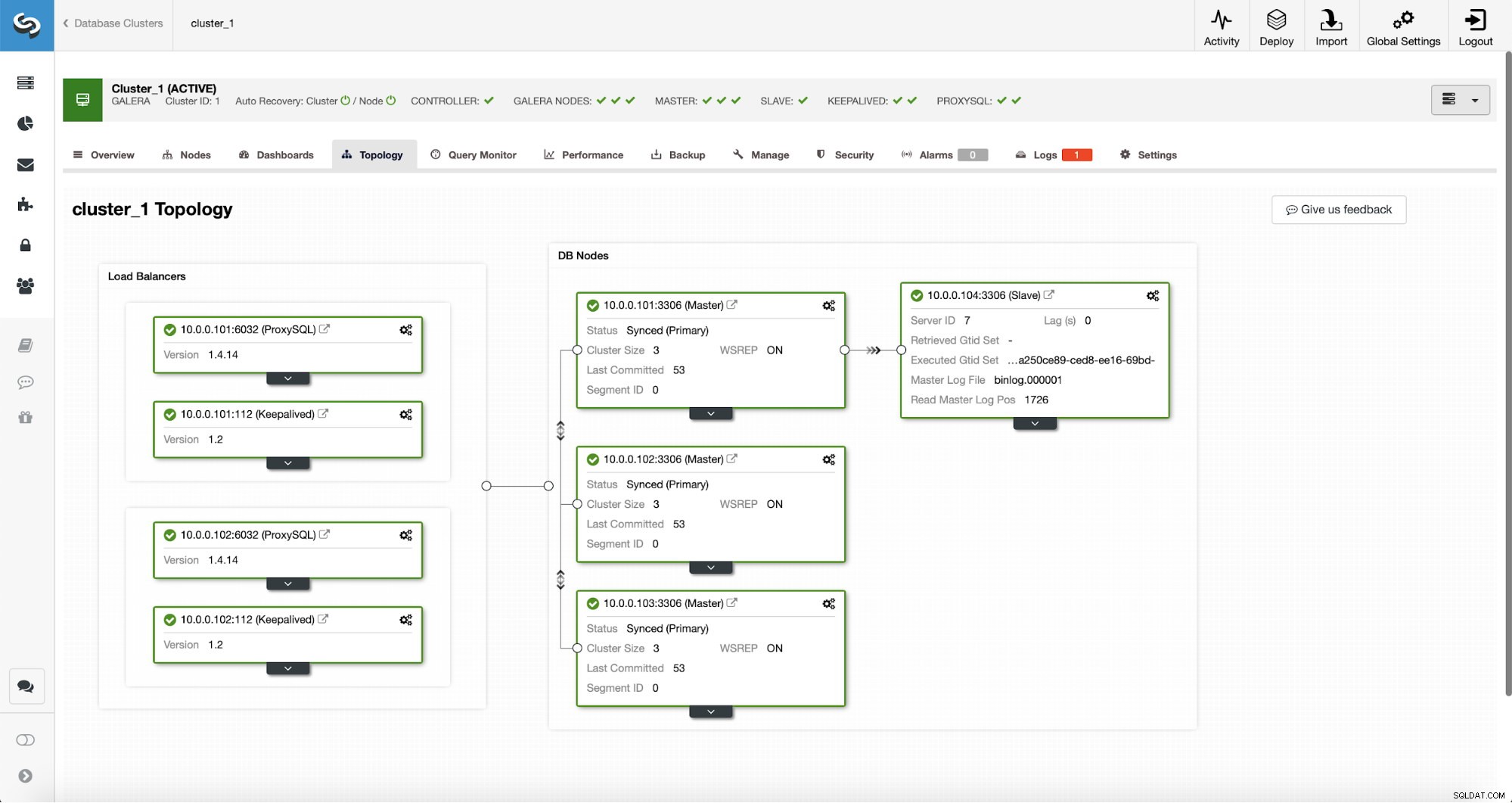
Une fois la tâche terminée, un esclave de réplication a été ajouté au cluster. Comme indiqué précédemment, si le 10.0.0.101 meurt, un autre hôte du cluster Galera sera choisi comme maître et ClusterControl asservira automatiquement 10.0.0.104 sur un autre nœud.
Comme nous utilisons ProxySQL, nous devons le configurer. Nous allons ajouter un nouveau serveur dans ProxySQL.
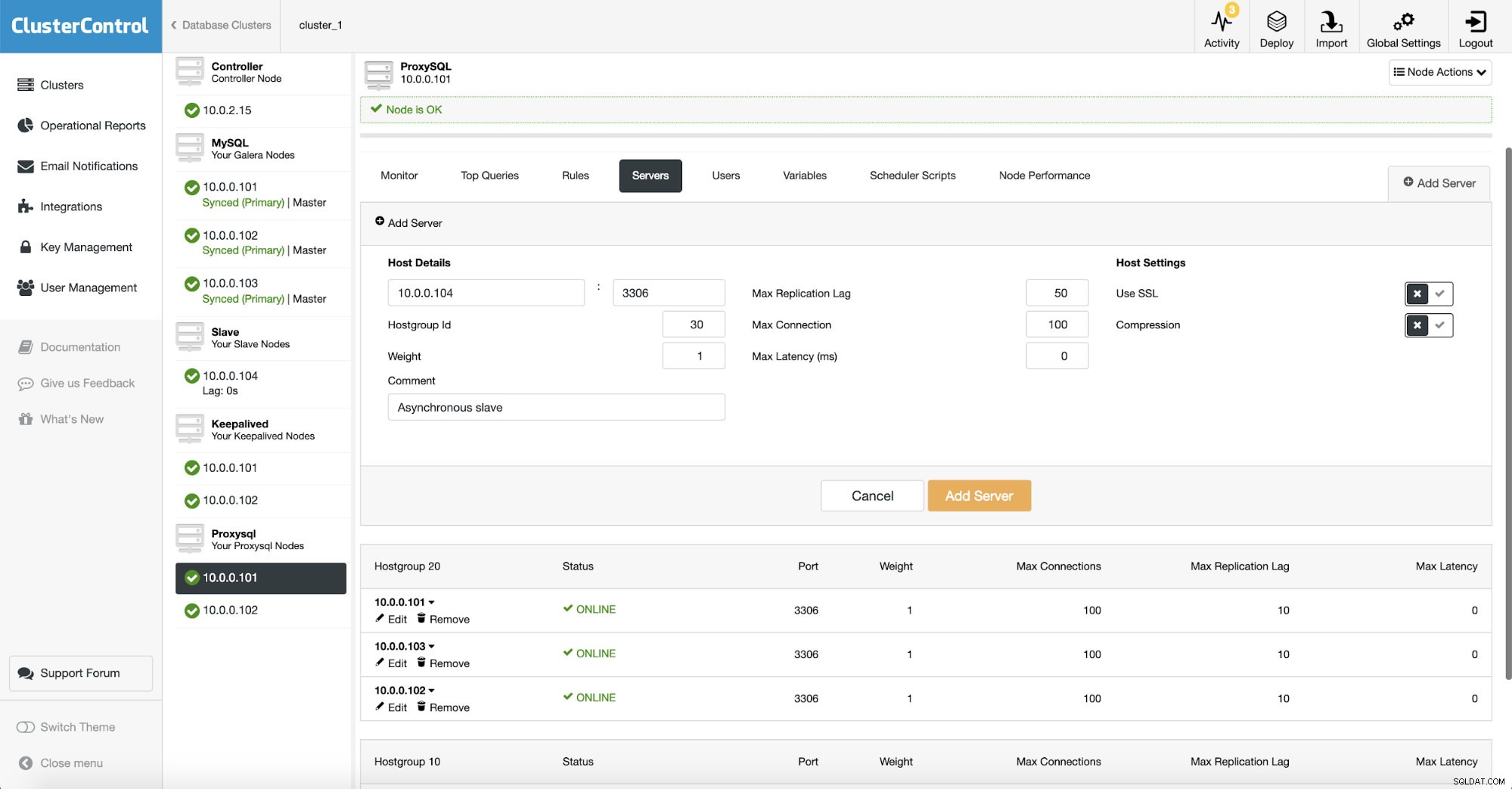
Nous avons créé un autre groupe d'hôtes (30) où nous mettons notre esclave asynchrone. Nous avons également augmenté le "Max Replication Lag" à 50 secondes par rapport à la valeur par défaut de 10. C'est aux besoins de votre entreprise de décider à quel point l'esclave d'analyse peut être en retard avant qu'il ne devienne un problème.
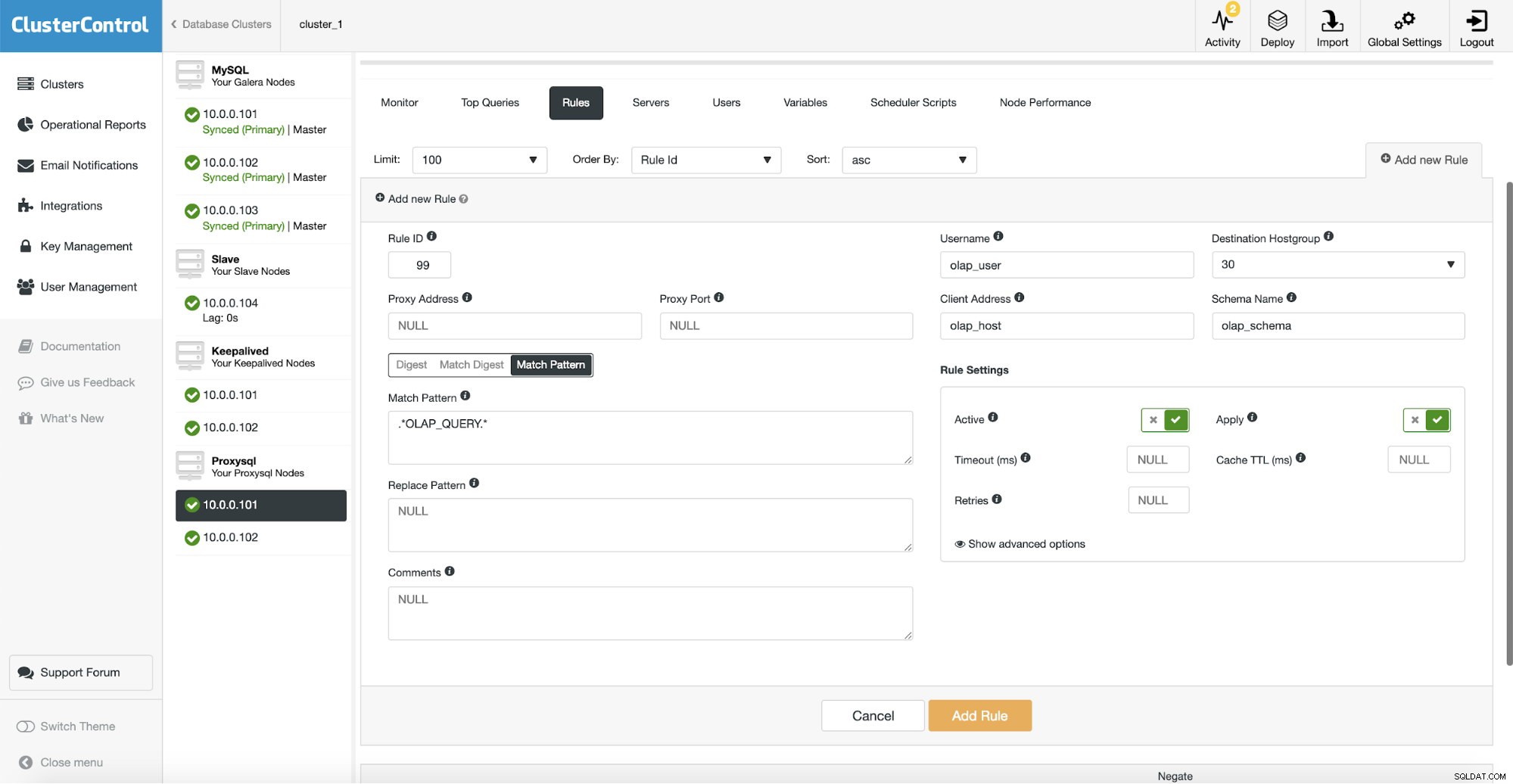
Après cela, nous devons configurer une règle de requête qui correspondra à notre trafic OLAP et l'acheminer vers le groupe d'hôtes OLAP (30). Sur la capture d'écran ci-dessus, nous avons rempli plusieurs champs - ce n'est pas obligatoire. En règle générale, vous devrez en utiliser un, deux au maximum. La capture d'écran ci-dessus sert d'exemple afin que nous puissions facilement voir que vous pouvez faire correspondre les requêtes en utilisant le schéma (si vous avez un schéma séparé avec des données analytiques), le nom d'hôte/IP (si les requêtes OLAP sont exécutées à partir d'un hôte particulier), l'utilisateur (si l'application utilise utilisateur particulier pour les requêtes analytiques. Vous pouvez également faire correspondre les requêtes directement en transmettant une requête complète ou en les marquant avec des commentaires SQL et laisser ProxySQL acheminer toutes les requêtes avec une chaîne "OLAP_QUERY" vers notre groupe d'hôtes analytique.
Comme vous pouvez le constater, grâce à ClusterControl, nous avons pu déployer un esclave de réplication sur Galera Cluster en quelques clics seulement. Certains diront que MySQL n'est pas la base de données la plus appropriée pour la charge de travail analytique et nous avons tendance à être d'accord. Vous pouvez facilement étendre cette configuration à l'aide de ClickHouse et en configurant une réplication d'un esclave asynchrone vers une banque de données en colonnes ClickHouse pour de bien meilleures performances des requêtes analytiques. Nous avons décrit cette configuration dans l'un des articles de blog précédents.