Depuis la sortie de SQL Server 2017 pour Linux, Microsoft a pratiquement changé tout le jeu. Cela a ouvert un tout nouveau monde de possibilités pour leur célèbre base de données relationnelle, offrant ce qui n'était jusque-là disponible que dans l'espace Windows.
Je sais qu'un DBA puriste me dirait tout de suite que la version Linux SQL Server 2019 prête à l'emploi présente plusieurs différences, en termes de fonctionnalités, par rapport à son homologue Windows, telles que :
- Aucun agent SQL Server
- Aucun FileStream
- Aucune procédure stockée étendue du système (par exemple, xp_cmdshell)
Cependant, je suis devenu assez curieux pour penser "et s'ils peuvent être comparés, au moins dans une certaine mesure, à des choses que les deux peuvent faire?" J'ai donc appuyé sur la gâchette de quelques machines virtuelles, préparé quelques tests simples et collecté des données à vous présenter. Voyons comment les choses se passent !
Considérations initiales
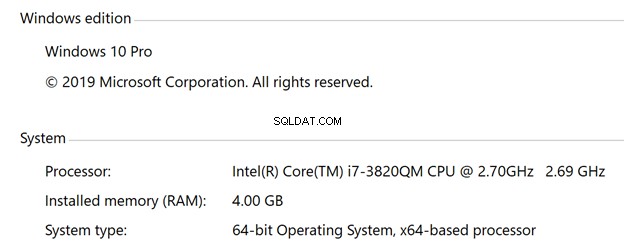
Voici les spécifications de chaque VM :
- Windows
- Système d'exploitation Windows 10
- 4 processeurs virtuels
- 4 Go de RAM
- SSD de 30 Go
- Linux
- Serveur Ubuntu 20.04 LTS
- 4 processeurs virtuels
- 4 Go de RAM
- SSD de 30 Go


Pour la version SQL Server, j'ai choisi la toute dernière version pour les deux systèmes d'exploitation :SQL Server 2019 Developer Edition CU10
Dans chaque déploiement, la seule chose activée était l'initialisation instantanée du fichier (activée par défaut sous Linux, activée manuellement sous Windows). En dehors de cela, les valeurs par défaut sont restées pour le reste des paramètres.
- Sous Windows, vous pouvez choisir d'activer l'initialisation instantanée des fichiers avec l'assistant d'installation.
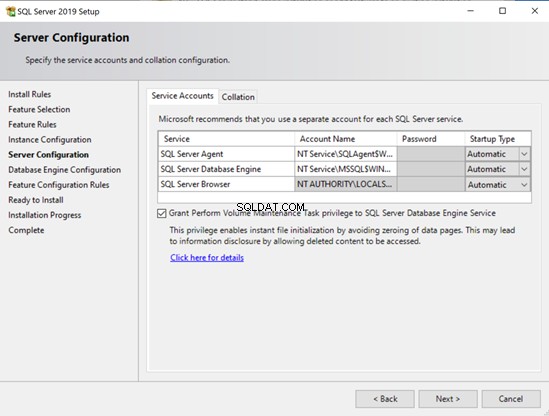
Cet article ne couvrira pas la spécificité du travail d'initialisation instantanée des fichiers sous Linux. Cependant, je vous laisse un lien vers l'article dédié que vous pourrez lire plus tard (notez que cela devient un peu lourd sur le plan technique).
Que comprend le test ?
- Dans chaque instance SQL Server 2019, j'ai déployé une base de données de test et créé une table avec un seul champ (un NVARCHAR(MAX)).
- À l'aide d'une chaîne de 1 000 000 caractères générée aléatoirement, j'ai effectué les étapes suivantes :
- *Insérez un nombre X de lignes dans le tableau de test.
- Mesurez le temps qu'il a fallu pour remplir l'instruction INSERT.
- Mesurez la taille des fichiers MDF et LDF.
- Supprimez toutes les lignes du tableau de test.
- **Mesurez le temps qu'il a fallu pour terminer l'instruction DELETE.
- Mesurez la taille du fichier LDF.
- Supprimer la base de données de test.
- Créez à nouveau la base de données de test.
- Répéter le même cycle.
* X a été effectué pour 1 000, 5 000, 10 000, 25 000 et 50 000 lignes.
**Je sais qu'une instruction TRUNCATE fait le travail de manière plus efficace, mais mon but ici est de prouver à quel point chaque journal de transactions est géré pour l'opération de suppression dans chaque système d'exploitation.
Vous pouvez accéder au site Web que j'ai utilisé pour générer la chaîne aléatoire si vous souhaitez approfondir.
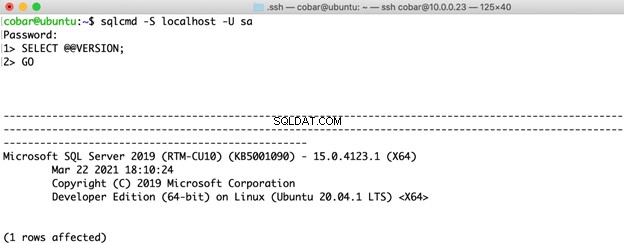
Voici les sections du code TSQL que j'ai utilisées pour les tests dans chaque système d'exploitation :
Codes TSQL Linux
Création de bases de données et de tables
DROP DATABASE IF EXISTS test
CREATE DATABASE test
ON
(FILENAME= '/var/opt/mssql/data/test.mdf', NAME = test, FILEGROWTH = 128MB)
LOG ON
(FILENAME= '/var/opt/mssql/data/test_log.ldf',NAME = test_log, FILEGROWTH = 64MB);
CREATE TABLE test.dbo.ubuntu(
long_string NVARCHAR(MAX) NOT NULL
)
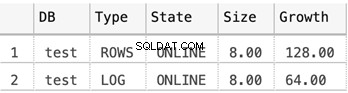
Taille des fichiers MDF et LDF pour la base de données de test
SELECT
DB_NAME(database_id) AS 'DB',
type_desc AS 'Type',
state_desc AS 'State',
CONVERT(DECIMAL(10,2),size*8/1024) AS 'Size',
CONVERT(DECIMAL(10,2),growth*8/1024) AS 'Growth'
FROM sys.master_files
WHERE DB_NAME(database_id) = 'test'
La capture d'écran ci-dessous montre la taille des fichiers de données lorsque rien n'est stocké dans la base de données :
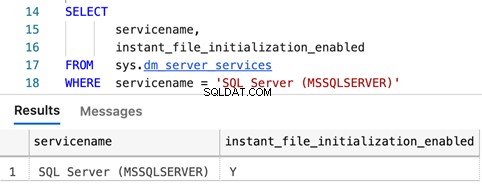
Requêtes pour déterminer si l'initialisation instantanée du fichier est activée
SELECT
servicename,
instant_file_initialization_enabled
FROM sys.dm_server_services
WHERE servicename = 'SQL Server (MSSQLSERVER)'

Codes TSQL Windows
Création de bases de données et de tables
DROP DATABASE IF EXISTS test
CREATE DATABASE test
ON
(FILENAME= 'S:\Program Files\Microsoft SQL Server\MSSQL15.WINDOWS\MSSQL\DATA\test.mdf', NAME = test, FILEGROWTH = 128MB)
LOG ON
(FILENAME= ''S:\Program Files\Microsoft SQL Server\MSSQL15.WINDOWS\MSSQL\DATA\test_log.ldf',NAME = test_log, FILEGROWTH = 64MB);
CREATE TABLE test.dbo.windows(
long_string NVARCHAR(MAX) NOT NULL
)
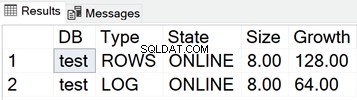
Taille des fichiers MDF et LDF pour la base de données de test
SELECT
DB_NAME(database_id) AS 'DB',
type_desc AS 'Type',
state_desc AS 'State',
CONVERT(DECIMAL(10,2),size*8/1024) AS 'Size',
CONVERT(DECIMAL(10,2),growth*8/1024) AS 'Growth'
FROM sys.master_files
WHERE DB_NAME(database_id) = 'test'
La capture d'écran suivante montre la taille des fichiers de données lorsque rien n'est stocké dans la base de données :
Requête pour déterminer si l'initialisation instantanée du fichier est activée
SELECT
servicename,
instant_file_initialization_enabled
FROM sys.dm_server_services
WHERE servicename = 'SQL Server (MSSQLSERVER)'
Script pour exécuter l'instruction INSERT :
@limit -> ici j'ai précisé le nombre de lignes à insérer dans la table de test
Pour Linux, puisque j'ai exécuté le script en utilisant SQLCMD, j'ai mis la fonction DATEDIFF à la toute fin. Cela me permet de savoir combien de secondes l'exécution complète prend (pour la variante Windows, j'aurais pu simplement jeter un coup d'œil au minuteur dans SQL Server Management Studio).
La chaîne entière de 1 000 000 caractères remplace "XXXX". Je le mets comme ça uniquement pour bien le présenter dans ce post.
SET NOCOUNT ON
GO
DECLARE @StartTime DATETIME;
DECLARE @i INT;
DECLARE @limit INT;
SET @StartTime = GETDATE();
SET @i = 0;
SET @limit = 1000;
WHILE(@i < @limit)
BEGIN
INSERT INTO test.dbo.ubuntu VALUES('XXXX');
SET @i = @i + 1
END
SELECT DATEDIFF(SECOND,@StartTime,GETDATE()) AS 'Elapsed Seconds';
Script pour exécuter l'instruction DELETE
SET NOCOUNT ON
GO
DECLARE @StartTime DATETIME;
SET @StartTime = GETDATE();
DELETE FROM test.dbo.ubuntu;
SELECT DATEDIFF(SECOND,@StartTime,GETDATE()) AS 'Elapsed Seconds';
Les résultats obtenus
Toutes les tailles sont exprimées en Mo. Toutes les mesures de temps sont exprimées en secondes.
| INSÉRER l'heure | 1 000 enregistrements | 5 000 enregistrements | 10 000 enregistrements | 25 000 enregistrements | 50 000 enregistrements |
| Linux | 4 | 23 | 43 | 104 | 212 |
| Windows | 4 | 28 | 172 | 531 | 186 |
| Taille (MDF) | 1 000 enregistrements | 5 000 enregistrements | 10 000 enregistrements | 25 000 enregistrements | 50 000 enregistrements |
| Linux | 264 | 1032 | 2056 | 5128 | 10184 |
| Windows | 264 | 1032 | 2056 | 5128 | 10248 |
| Taille (LDF) | 1 000 enregistrements | 5 000 enregistrements | 10 000 enregistrements | 25 000 enregistrements | 50 000 enregistrements |
| Linux | 104 | 264 | 360 | 552 | 148 |
| Windows | 136 | 328 | 392 | 456 | 584 |
| DELETE Time | 1 000 enregistrements | 5 000 enregistrements | 10 000 enregistrements | 25 000 enregistrements | 50 000 enregistrements |
| Linux | 1 | 1 | 74 | 215 | 469 |
| Windows | 1 | 63 | 126 | 357 | 396 |
| SUPPRIMER Taille (LDF) | 1 000 enregistrements | 5 000 enregistrements | 10 000 enregistrements | 25 000 enregistrements | 50 000 enregistrements |
| Linux | 136 | 264 | 392 | 584 | 680 |
| Windows | 200 | 328 | 392 | 456 | 712 |
Informations clés
- La taille du MDF était à peu près constante tout au long du test, variant légèrement à la toute fin (mais rien de trop fou).
- Les timings pour les INSERTs étaient meilleurs sous Linux pour la plupart, sauf à la toute fin lorsque Windows "a remporté la manche".
- La taille du fichier journal des transactions était mieux gérée sous Linux après chaque série d'INSERTs.
- Les timings pour DELETE étaient meilleurs sous Linux pour la plupart, sauf à la toute fin où Windows "a remporté la manche" (je trouve curieux que Windows ait également remporté la dernière manche INSERT).
- La taille des fichiers journaux des transactions après chaque cycle de suppressions était à peu près à égalité en termes de hauts et de bas entre les deux.
- J'aurais aimé tester avec 100 000 lignes, mais je manquais un peu d'espace disque, alors je l'ai plafonné à 50 000.
Conclusion
Sur la base des résultats obtenus à partir de ce test, je dirais qu'il n'y a aucune raison valable d'affirmer que la variante Linux fonctionne de manière exponentielle mieux que son homologue Windows. Bien sûr, il ne s'agit en aucun cas d'un test formel sur lequel vous pouvez vous baser pour prendre une telle décision. Cependant, l'exercice lui-même était assez intéressant pour moi.
Je suppose que SQL Server 2019 pour Windows prend parfois un peu de retard (pas beaucoup) en raison du rendu de l'interface graphique en arrière-plan, ce qui ne se produit pas du côté Ubuntu Server de la clôture.
Si vous comptez beaucoup sur des fonctionnalités et des capacités exclusives à Windows (du moins au moment d'écrire ces lignes), alors allez-y par tous les moyens. Sinon, vous ne ferez pas un mauvais choix en optant pour l'un plutôt que l'autre.