Qu'est-ce que l'optimisation des requêtes dans SQL Server ? C'est un gros sujet. Chaque technique ou problème nécessite un article séparé pour couvrir les bases. Mais lorsque vous commencez tout juste à améliorer votre jeu avec des requêtes, vous avez besoin de quelque chose de plus simple sur lequel vous appuyer. C'est le but de cet article.
Vous pourriez dire que vos requêtes sont optimales, que tout fonctionne bien et que les utilisateurs sont satisfaits. Bien sûr, les performances ne font pas tout. Les résultats doivent également être corrects. Qu'il s'agisse d'une jointure, d'une sous-requête, d'un synonyme, d'un CTE, d'une vue ou autre, il doit fonctionner de manière acceptable.
Et à la fin de la journée, vous pouvez rentrer chez vous avec vos utilisateurs. Vous ne voulez pas rester au bureau à régler les requêtes lentes du jour au lendemain.
Avant de commencer, permettez-moi de vous assurer que le voyage ne sera pas difficile. Ce ne sera qu'une introduction. Nous aurons des exemples qui ne vous seront pas trop étrangers non plus. Enfin, lorsque vous serez prêt pour une étude plus approfondie, nous vous présenterons quelques liens que vous pourrez consulter.
Commençons.
1. L'optimisation des requêtes SQL commence par la conception et l'architecture
Surpris? L'optimisation des requêtes SQL n'est pas une réflexion après coup ou un pansement en cas de panne. Votre requête s'exécute aussi rapidement que votre conception le permet. Nous parlons de tableaux normalisés, des bons types de données, de l'utilisation d'index, de l'archivage des anciennes données et de toutes les meilleures pratiques auxquelles vous pouvez penser.
Une bonne conception de base de données fonctionne en synergie avec le bon matériel et les paramètres SQL Server. L'avez-vous conçu pour qu'il fonctionne sans problème pendant plusieurs années et qu'il se sente toujours neuf ? C'est un grand rêve, mais nous n'avons qu'un certain temps (généralement court) pour y penser.
Ce ne sera pas parfait le premier jour de la production, mais nous aurions dû couvrir les bases. Nous minimiserons la dette technique. Si vous travaillez avec une équipe, c'est super par rapport à un one-man show. Vous pouvez couvrir une grande partie des cloches et des sifflets.
Pourtant, que se passe-t-il si la base de données est en cours d'exécution et que vous touchez le mur des performances ? Voici quelques trucs et astuces d'optimisation des requêtes SQL.
2. Repérer les requêtes problématiques avec le rapport standard SQL Server
Lorsque vous codez, il est facile de repérer une longue série de code ou une procédure stockée. Vous pouvez le déboguer ligne par ligne. La ligne qui traîne est celle à corriger.
Mais que se passe-t-il si votre service d'assistance lance une douzaine de tickets parce qu'il est lent ? Les utilisateurs ne peuvent pas identifier l'emplacement exact dans le code, et le service d'assistance non plus. Le temps est votre pire ennemi.
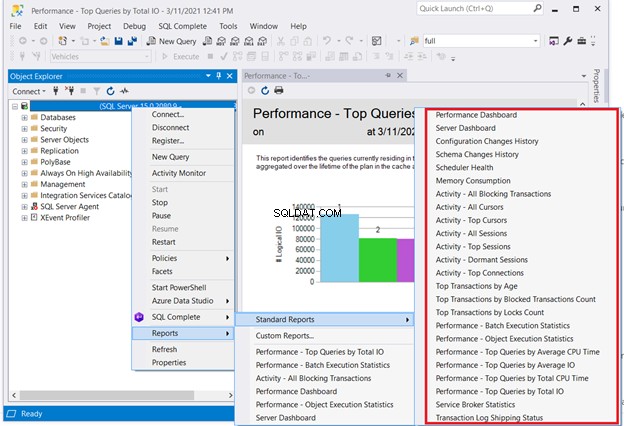
Une solution qui ne nécessitera pas de codage consiste à vérifier les rapports standard de SQL Server. Cliquez avec le bouton droit sur le serveur nécessaire dans SQL Server Management Studio> Rapports> Rapports standards . Notre point d'intérêt peut être le tableau de bord des performances ou Performances – Requêtes les plus fréquentes par nombre total d'E/S . Choisissez la première requête qui fonctionne mal. Ensuite, démarrez l'optimisation de la requête SQL ou le réglage des performances SQL à partir de là.
3. Réglage des requêtes SQL avec STATISTICS IO
Après avoir identifié la requête en question, vous pouvez commencer à vérifier les lectures logiques dans STATISTICS IO. C'est l'un des outils d'optimisation des requêtes SQL.
Il existe quelques points d'E/S, mais vous devez vous concentrer sur les lectures logiques. Plus les lectures logiques sont élevées, plus les performances de la requête sont problématiques.
En réduisant les 3 facteurs suivants, vous pouvez accélérer les requêtes de réglage des performances en SQL :
- lectures logiques élevées,
- lectures logiques LOB élevées,
- ou lectures logiques WorkTable/WorkFile élevées.
Pour obtenir des informations sur les lectures logiques, activez STATISTICS IO dans la fenêtre de requête de SQL Server Management Studio.
ACTIVER LES E/S STATISTIQUES
Vous pouvez obtenir la sortie dans l'onglet Messages une fois la requête terminée. La figure 2 affiche l'exemple de sortie :
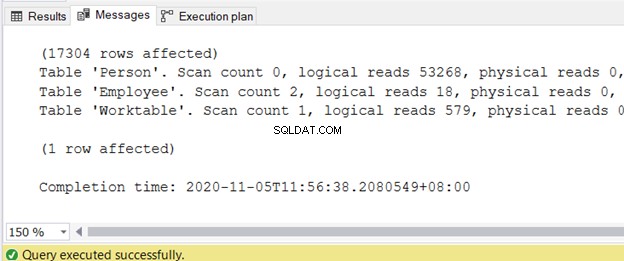
J'ai écrit un article séparé sur la réduction des lectures logiques dans 3 Nasty I/O Statistics qui retardent les performances des requêtes SQL. Consultez-le pour connaître les étapes exactes et les exemples de code avec des lectures logiques élevées et des moyens de les réduire.
4. Optimisation des requêtes SQL avec plans d'exécution
Les lectures logiques seules ne vous donneront pas une image complète. La série d'étapes choisies par l'optimiseur de requête racontera l'histoire de votre ensemble de résultats. Comment tout cela commence-t-il après l'exécution de la requête ?
La figure 3 ci-dessous est un diagramme de ce qui se passe après le déclenchement de l'exécution jusqu'au moment où vous obtenez le jeu de résultats.
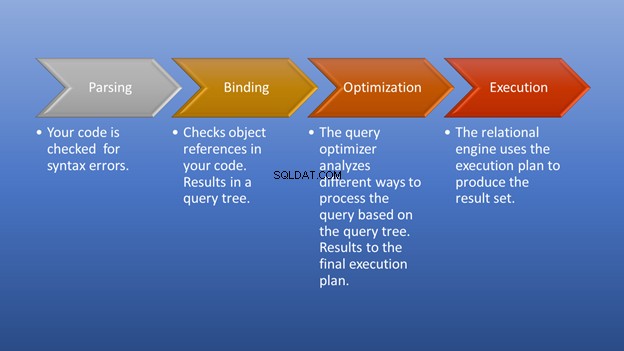
L'analyse et la liaison se produiront en un éclair. La partie géniale est l'étape d'optimisation, qui est notre objectif. À ce stade, l'optimiseur de requête joue un rôle central dans la sélection du meilleur plan d'exécution possible. Bien que cette partie nécessite certaines ressources, elle permet de gagner beaucoup de temps lorsqu'elle choisit un plan d'exécution efficace. Cela se produit de manière dynamique, car la base de données change au fil du temps. De cette façon, le programmeur peut se concentrer sur la façon de former le résultat final.
Chaque plan pris en compte par l'optimiseur de requête a son coût de requête. Parmi de nombreuses options, l'optimiseur choisira le plan avec le coût le plus raisonnable. Remarque :Le coût raisonnable n'est pas égal au moindre coût. Il doit également déterminer quel plan produira les résultats les plus rapides. Le plan le moins coûteux n'est pas toujours le plus rapide. Par exemple, l'optimiseur peut choisir d'utiliser plusieurs cœurs de processeur. Nous appelons cette exécution parallèle. Cela consommera plus de ressources mais s'exécutera plus rapidement par rapport à l'exécution en série.
Un autre point à considérer est les statistiques. L'optimiseur de requête s'en sert pour créer des plans d'exécution. Si les statistiques sont obsolètes, ne vous attendez pas à la meilleure décision de l'optimiseur de requête.
Lorsque le plan est décidé et que l'exécution se poursuit, vous verrez les résultats. Et maintenant ?
Inspecter le plan d'exécution des requêtes dans SQL Server
Lorsque vous formez une requête, vous voulez d'abord voir les résultats. Les résultats doivent être corrects. Quand c'est le cas, vous avez terminé.
C'est ça ?
Si vous manquez de temps et que le travail est en jeu, vous pouvez accepter cela. De plus, vous pouvez toujours revenir. Cependant, si d'autres problèmes surviennent, vous pouvez les oublier encore et encore. Et puis, le fantôme du passé vous traquera.
Maintenant, quelle est la meilleure chose à faire après avoir obtenu les bons résultats ?
Inspecter le plan d'exécution réel ou les statistiques de requête en direct !
Ce dernier est bon si votre requête s'exécute lentement et que vous voulez voir ce qui se passe chaque seconde pendant le traitement des lignes.
Parfois, la situation vous forcera à inspecter le plan immédiatement. Pour commencer, appuyez sur Control-M ou cliquez sur Inclure le plan d'exécution réel à partir de la barre d'outils de SQL Server Management Studio. Si vous préférez dbForge Studio pour SQL Server, accédez à Query Profiler - il fournit les mêmes informations + quelques cloches et sifflets que vous ne pouvez pas trouver dans SSMS.
Nous avons vu le plan d'exécution réel . Allons plus loin.
Y a-t-il un index manquant ou des recommandations d'index ?
Un index manquant est facile à repérer - vous recevez l'avertissement immédiatement.
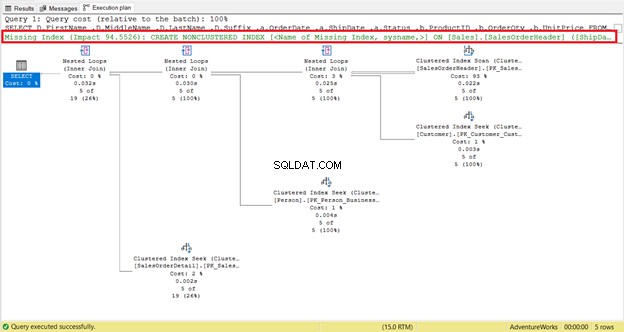
Pour obtenir un code instantané pour créer l'index, cliquez avec le bouton droit sur l'index manquant message (encadré en rouge). Sélectionnez ensuite Détails de l'index manquants . Une nouvelle fenêtre de requête avec le code pour créer l'index manquant apparaîtra. Créez l'index.
Cette partie est facile à suivre. C'est un bon point de départ pour obtenir une exécution plus rapide. Mais dans certains cas, il n'y aura aucun effet. Pourquoi? Certaines colonnes nécessaires à votre requête ne figurent pas dans l'index. Par conséquent, il reviendra à un balayage d'index clusterisé.
Vous devez réinspecter le plan d'exécution après avoir créé l'index pour voir si les colonnes incluses sont nécessaires. Ensuite, ajustez l'index en conséquence et relancez votre requête. Après cela, vérifiez à nouveau le plan d'exécution.
Mais que se passe-t-il s'il n'y a pas d'index manquant ?
Lire le plan d'exécution
Vous devez connaître quelques éléments de base pour démarrer :
- Opérateurs
- Propriétés
- Sens de lecture
- Avertissements
OPÉRATEURS
L'optimiseur de requête utilise une sorte de mini-programmes appelés opérateurs. Vous en avez vu quelques-uns dans la Figure 4 – Clustered Index Seek , Analyse d'index groupé , boucles imbriquées , et Sélectionner .
Pour obtenir une liste complète avec des noms, des icônes et des descriptions, vous pouvez consulter cette référence de Microsoft.
PROPRIÉTÉS
Les schémas graphiques ne suffisent pas pour comprendre ce qui se passe dans les coulisses. Vous devez approfondir les propriétés de chaque opérateur. Par exemple, l'analyse d'index en cluster dans la figure 4 a les propriétés suivantes :
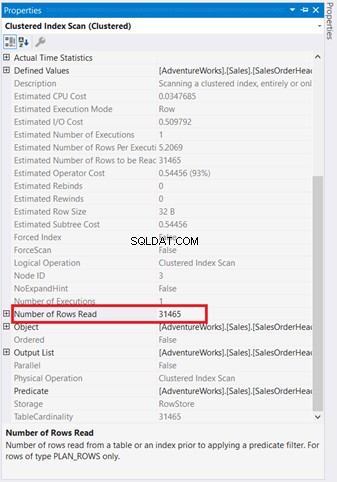
Si vous l'examinez attentivement, le balayage d'index groupé l'opérateur est terrible. Comme le montre la figure 5, il lit 31 465 lignes, mais le jeu de résultats final ne contient que 5 lignes. C'est pourquoi il existe une recommandation d'index dans la figure 4 pour réduire le nombre de lignes lues. Les lectures logiques de la requête sont également élevées et cela explique pourquoi.
Pour en savoir plus sur ces propriétés, consultez la liste des propriétés courantes des opérateurs et des propriétés du plan.
SENS DE LECTURE
Généralement, c'est comme lire un manga japonais - de droite à gauche. Suivez les flèches qui pointent vers la gauche. Voici un exemple simple de dbForge Studio pour SQL Server.
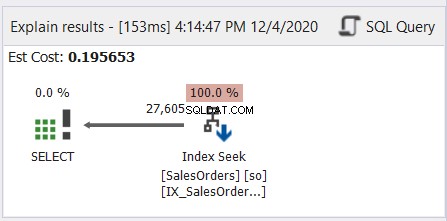
Comme le montre la figure 6, la flèche pointe vers la gauche de l'opérateur Index Seek à l'opérateur SELECT.
Cependant, la lecture de droite à gauche n'est pas toujours correcte. Voir Figure 7 avec un exemple de SSMS :
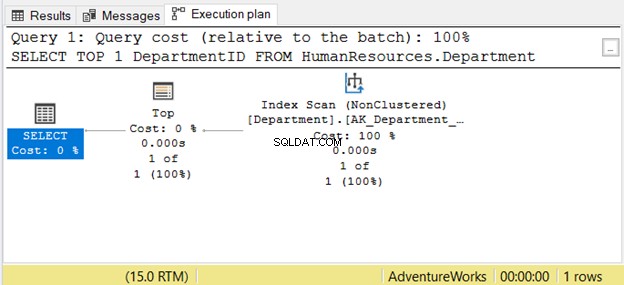
Si vous le lisez de droite à gauche, vous verrez que l'analyse de l'index la sortie de l'opérateur est 1 sur 1 ligne. Comment pourrait-il savoir qu'une seule ligne à récupérer ? C'est à cause du Top opérateur. Cela nous confondra si nous le lisons de droite à gauche.
Pour mieux comprendre ce cas, lisez-le comme "l'opérateur SELECT utilise Top pour récupérer 1 ligne à l'aide de Index Scan". C'est de gauche à droite.
Que devrions-nous utiliser ? De droite à gauche ou de gauche à droite ?
C'est un peu les deux - selon ce qui vous aide à comprendre le plan.
Alors que la flèche nous donne la direction du flux de données, son épaisseur nous donne quelques indications sur la taille des données. Reportons-nous à nouveau à la figure 4.
L'analyse d'index cluster aller à la boucle imbriquée a une flèche plus épaisse que les autres. Les propriétés détails de Analyse d'index dans la figure 5, dites-nous pourquoi il est épais (31 465 lignes lues pour un résultat final de 5 lignes).
AVERTISSEMENTS
Une icône d'avertissement apparaissant dans l'opérateur du plan d'exécution nous indique que quelque chose de mauvais s'est produit dans cet opérateur. Cela peut entraver l'optimisation de vos requêtes SQL en consommant plus de ressources.
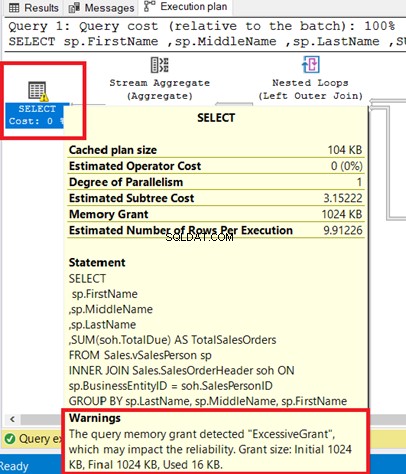
Vous pouvez voir l'avertissement dans l'opérateur SELECT. Passer la souris sur cet opérateur révèle le message d'avertissement. Une subvention excessive a provoqué cet avertissement.
Subvention excessive se produit lorsque moins de mémoire est utilisée que celle réservée à la requête. Pour plus d'informations, reportez-vous à cette documentation Microsoft.
La figure 8 montre la requête utilisée comme INNER JOIN d'une vue à une table. Vous pouvez supprimer l'avertissement en joignant les tables de base au lieu de la vue.
Maintenant que vous avez une idée de base de la lecture des plans d'exécution, comment définir ce qui ralentit votre requête ?
Connaître les 5 voleurs d'opérateurs de plan commun
Le retard dans l'exécution de votre requête est comme un crime. Vous devez chasser et arrêter ces voleurs.
1. Analyse d'index cluster ou non cluster
Le premier escroc que tout le monde découvre est Clustered ou Analyse d'index non clusterisé . Il est de notoriété publique dans l'optimisation des requêtes SQL que les analyses sont mauvaises et que les recherches sont bonnes. Nous en avons vu un dans la figure 4. En raison de l'index manquant, le balayage d'index clusterisé lit 31 465 pour obtenir 5 lignes.
Cependant, ce n'est pas toujours le cas. Considérez 2 requêtes sur la même table dans la figure 9. L'une aura une recherche et l'autre une analyse.
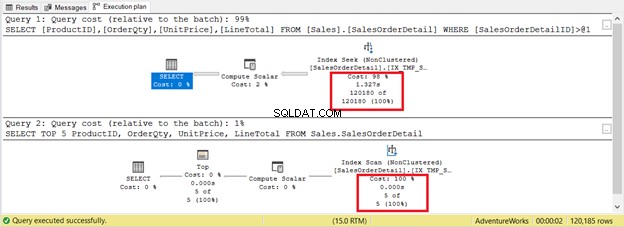
Si vous basez uniquement les critères sur le nombre d'enregistrements, l'analyse d'index gagne avec seulement 5 enregistrements contre 120 180. La recherche d'index prendra plus de temps à s'exécuter.
Voici un autre cas où la numérisation ou la recherche n'ont presque pas d'importance. Ils renvoient les 6 mêmes enregistrements de la même table. Les lectures logiques sont les mêmes et le temps écoulé est nul dans les deux cas. La table est très petite avec 6 enregistrements seulement. Inclure le plan d'exécution réel et exécutez les instructions ci-dessous.
-- Run this with Include Actual Execution Plan
USE AdventureWorks
GO
SET STATISTICS IO ON
GO
SELECT AddressTypeID, Name
FROM Person.AddressType
WHERE AddressTypeID >= 1
ORDER BY AddressTypeID DESC
Ensuite, enregistrez le plan d'exécution pour une comparaison ultérieure. Faites un clic droit sur le plan d'exécution> Enregistrer le plan d'exécution sous .
Maintenant, exécutez la requête ci-dessous.
SELECT AddressTypeID, Name
FROM Person.AddressType
ORDER BY AddressTypeID DESC
SET STATISTICS IO OFF
GO
Ensuite, cliquez avec le bouton droit sur le plan d'exécution et sélectionnez Comparer Showplan . Ensuite, sélectionnez le fichier que vous avez enregistré précédemment. Vous devriez avoir la même sortie que dans la figure 10 ci-dessous.
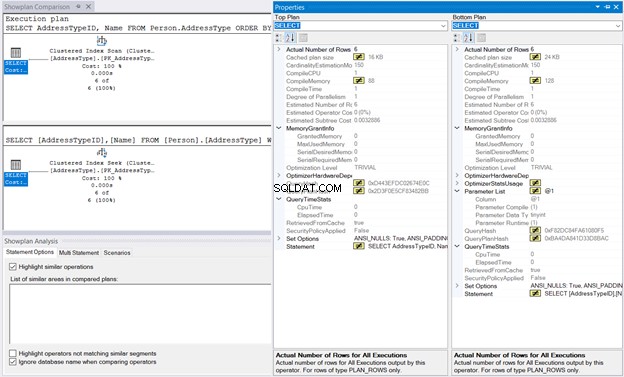
Le MemoryGrant et QueryTimeStats sont identiques. La mémoire de compilation de 128 Ko utilisé dans la Clustered Index Seek par rapport aux 88 Ko de l'analyse d'index cluster est presque négligeable. Sans ces chiffres à comparer, l'exécution sera la même.
2. Éviter les analyses de table
Cela se produit lorsque vous n'avez pas d'index. Au lieu de rechercher des valeurs à l'aide d'un index, SQL Server analysera les lignes une par une jusqu'à ce qu'il obtienne ce dont vous avez besoin dans votre requête. Cela traînera beaucoup sur les grandes tables. La solution simple consiste à ajouter l'index approprié.
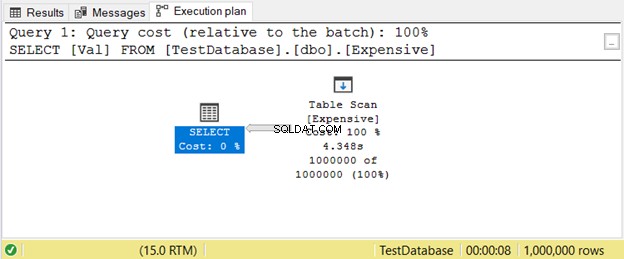
Voici un exemple de plan d'exécution avec Table Scan opérateur dans la figure 11.
3. Gestion des performances de tri
Comme il vient du nom, il change l'ordre des lignes. Cela peut être une opération coûteuse.
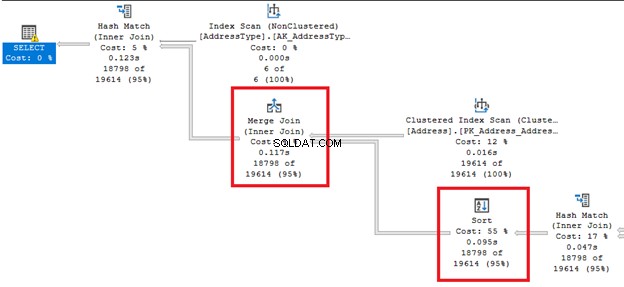
Regardez ces grosses flèches à droite et à gauche du Trier opérateur. Depuis que l'optimiseur de requête a décidé d'effectuer une jointure par fusion , un tri est requis. Notez également qu'il a le coût en pourcentage le plus élevé de tous les opérateurs (55 %).
Le tri peut être plus gênant si SQL Server doit trier les lignes plusieurs fois. Vous pouvez éviter cet opérateur si votre table est pré-triée en fonction de l'exigence de la requête. Ou vous pouvez diviser une seule requête en plusieurs.
4. Éliminer les recherches de clé
Dans la figure 4 précédente, SQL Server a recommandé d'ajouter un autre index. Je l'ai fait, mais ça ne m'a pas donné exactement ce que je voulais. Au lieu de cela, il m'a donné une recherche d'index au nouvel index associé à une Key Lookup opérateur.
Ainsi, le nouvel index a ajouté une étape supplémentaire.
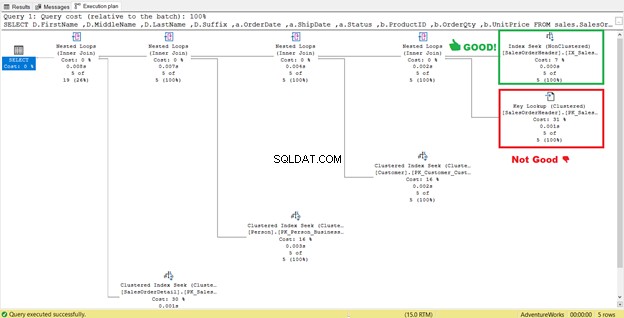
À quoi sert cette recherche de clé ? l'opérateur fait ?
Le processeur de requêtes a utilisé un nouvel index non clusterisé encadré en vert dans la figure 13. Comme notre requête nécessite des colonnes qui ne sont pas dans le nouvel index, elle doit obtenir ces données à l'aide d'une Key Lookup à partir de l'index clusterisé. Comment savons-nous ça? Passez votre souris sur Key Lookup révèle certaines de ses propriétés et prouve notre point.
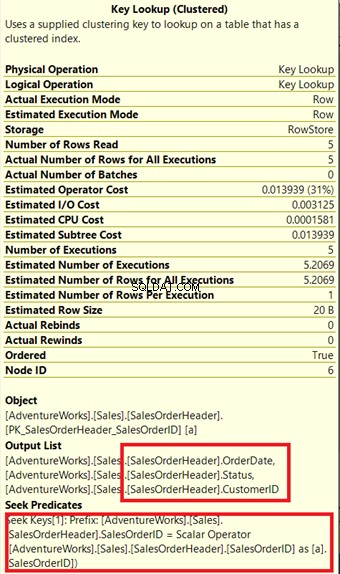
Dans la figure 14, notez la liste de sortie. Nous devons récupérer 3 colonnes en utilisant le PK_SalesOrderHeader_SalesOrderID index clusterisé. Pour supprimer cela, vous devez inclure ces colonnes dans le nouvel index. Voici le nouveau plan une fois ces colonnes incluses.
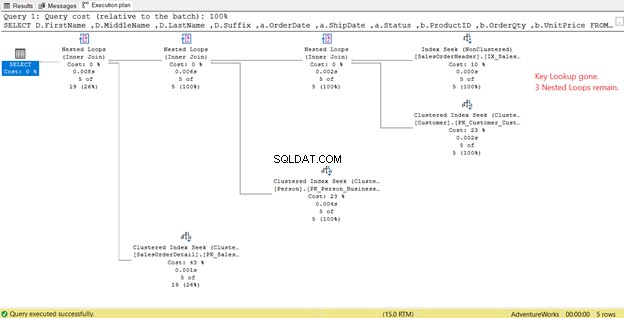
Dans la figure 14, nous avons vu 4 boucles imbriquées . Le quatrième est nécessaire pour la Key Lookup ajoutée . Mais après avoir ajouté 3 colonnes en tant que colonnes incluses dans le nouvel index, seules 3 boucles imbriquées restent, et la Key Lookup est retiré. Nous n'avons pas besoin d'étapes supplémentaires.
5. Parallélisme dans le plan d'exécution SQL Server
Jusqu'à présent, vous avez vu des plans d'exécution en exécution en série. Mais voici le plan qui tire parti de l'exécution parallèle. Cela signifie que plus d'un processeur est utilisé par l'optimiseur de requête pour exécuter la requête. Lorsque nous utilisons l'exécution parallèle, nous voyons le parallélisme opérateurs dans le plan, et d'autres changements aussi.
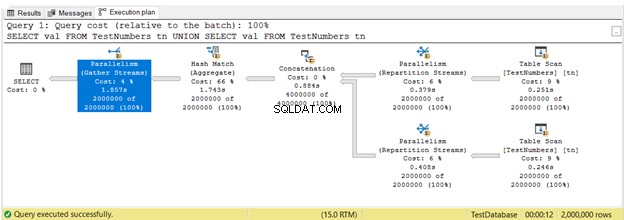
Dans la Figure 16, 3 Parallélisme opérateurs ont été utilisés. Notez également que le balayage de table l'icône de l'opérateur est un peu différente. Cela se produit lorsque l'exécution parallèle est utilisée.
Le parallélisme n'est pas intrinsèquement mauvais. Il augmente la vitesse des requêtes en utilisant plus de cœurs de processeur. Cependant, il utilise plus de ressources CPU. Lorsque beaucoup de vos requêtes utilisent des parallélismes, cela ralentit le serveur. Vous voudrez peut-être vérifier le seuil de coût pour le paramètre de parallélisme dans votre serveur SQL.
5. Meilleures pratiques pour l'optimisation des requêtes SQL
Jusqu'à présent, nous avons traité de l'optimisation des requêtes SQL avec des méthodes qui mettent au jour des problèmes difficiles à repérer. Mais il existe des moyens de le repérer dans le code. Voici quelques odeurs de code en SQL.
Utiliser SELECT *
Pressé? Ensuite, taper * peut être plus facile que de spécifier des noms de colonne. Cependant, il y a un hic. Les colonnes dont vous n'avez pas besoin retarderont votre requête.
Il y a une preuve. L'exemple de requête que j'ai utilisé pour la figure 15 est le suivant :
USE AdventureWorks
GO
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
Nous l'avons déjà optimisé. Mais changeons-le en SELECT *
USE AdventureWorks
GO
SELECT *
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
C'est plus court, mais vérifiez le plan d'exécution ci-dessous :
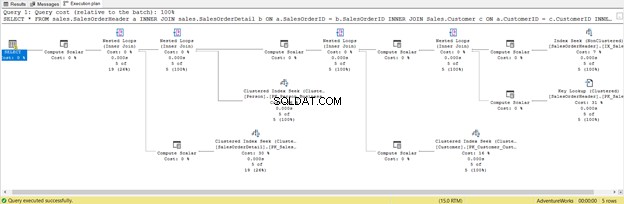
C'est la conséquence de l'inclusion de toutes les colonnes, même celles dont vous n'avez pas besoin. Il a renvoyé Key Lookup et beaucoup de Compute Scalar . En bref, cette requête a une charge importante et sera donc retardée. Notez également l'avertissement dans l'opérateur SELECT. Ce n'était pas là avant. Quel gâchis !
Fonctions dans une clause WHERE ou JOIN
Une autre odeur de code est d'avoir une fonction dans la clause WHERE. Considérez les 2 instructions SELECT suivantes ayant le même jeu de résultats. La différence se trouve dans la clause WHERE.
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE YEAR(a.ShipDate) = 2011
AND MONTH(a.ShipDate) = 7
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate BETWEEN '07/1/2011' AND '07/31/2011'
La première instruction SELECT utilise les fonctions de date YEAR et MONTH pour indiquer les dates d'expédition en juillet 2011. La deuxième instruction SELECT utilise l'opérateur BETWEEN avec des littéraux de date.
La première instruction SELECT aura un plan d'exécution similaire à la figure 4 mais sans la recommandation d'index. Le second aura un meilleur plan d'exécution similaire à la figure 15.
Celui qui est le mieux optimisé est évident.
Utilisation de caractères génériques
Dans quelle mesure les caractères génériques peuvent-ils affecter l'optimisation de nos requêtes SQL ? Prenons un exemple.
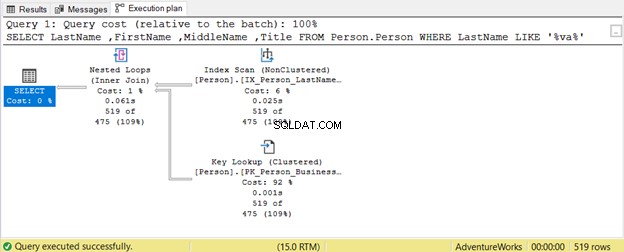
La requête essaie de rechercher la présence d'une chaîne dans Lastname dans n'importe quelle position. Par conséquent, Nom de famille COMME '%va%' . Ceci est inefficace sur les grandes tables car les lignes seront inspectées une par une pour la présence de cette chaîne. C'est pourquoi une analyse d'index est utilisé. Puisqu'aucun index n'inclut le Titre colonne, une recherche de clé est également utilisé.
Cela peut être résolu par la conception.
L'application d'appel l'exige-t-elle ? Ou suffira-t-il d'utiliser LIKE 'va%' ?
LIKE 'va%' utilise une recherche d'index car la table a un index sur lastname , prénom , et deuxième prénom .
Pouvez-vous également ajouter plus de filtres dans la clause WHERE pour réduire la lecture des enregistrements ?
Vos réponses à ces questions vous aideront à résoudre cette requête.
Conversion implicite
SQL Server effectue une conversion implicite en arrière-plan pour réconcilier les types de données lors de la comparaison des valeurs. Par exemple, il est pratique d'attribuer un nombre à une colonne de chaîne sans guillemets. Mais il y a un hic. L'effet est similaire lorsque vous utilisez une fonction dans une clause WHERE.
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
WHERE NationalIDNumber = 56920285
Le NationalIDNumner est NVARCHAR(15) mais est assimilé à un nombre. Il s'exécutera avec succès en raison de la conversion implicite. Mais notez le plan d'exécution de la figure 19 ci-dessous.
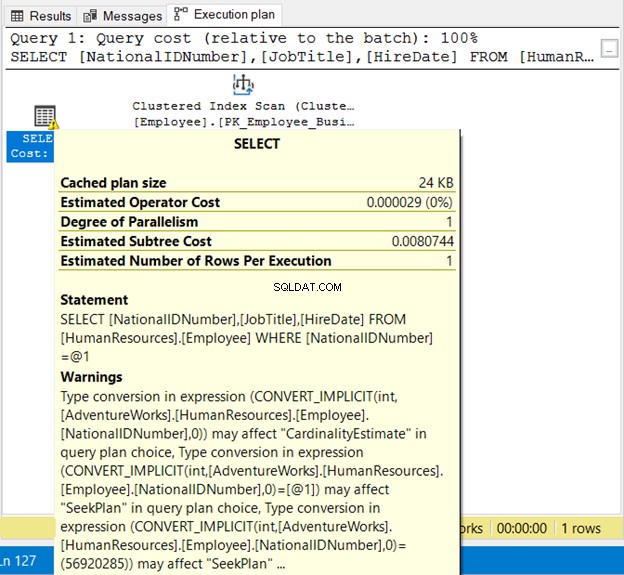
Nous voyons 2 mauvaises choses ici. Tout d'abord, l'avertissement. Ensuite, le balayage de l'index . L'analyse de l'index s'est produite en raison d'une conversion implicite. Ainsi, assurez-vous de mettre les chaînes entre guillemets ou de tester les valeurs littérales avec le même type de données que la colonne.
Points à retenir sur l'optimisation des requêtes SQL
C'est ça. Les bases de l'optimisation des requêtes SQL vous ont-elles fait vous sentir un peu prêt pour vos requêtes ? Faisons un récapitulatif.
- Si vous souhaitez optimiser vos requêtes, commencez par une bonne conception de la base de données.
- Si la base de données est déjà en production, repérez les requêtes problématiques à l'aide des rapports standard SQL Server.
- Découvrez l'ampleur de l'impact de la requête lente avec les lectures logiques de STATISTICS IO.
- Approfondissez l'histoire de votre requête lente avec les plans d'exécution.
- Regardez 4 odeurs de code qui ralentissent vos requêtes.
Il existe d'autres conseils d'optimisation des requêtes SQL pour accélérer l'exécution d'une requête lente. Comme je l'ai dit au début, c'est un gros sujet. Alors, faites-nous savoir dans la section Commentaires ce que nous avons manqué d'autre.
Et si vous aimez cet article, partagez-le sur vos plateformes de réseaux sociaux préférées.
Plus d'optimisation des requêtes SQL à partir des articles précédents
Si vous avez besoin de plus d'exemples, voici quelques articles utiles liés aux techniques d'optimisation des requêtes dans SQL Server.
- Les sous-requêtes nuisent-elles aux performances ? Consultez Le guide facile sur l'utilisation des sous-requêtes dans SQL Server .
- Utilisation de HierarchyID par rapport à la conception parent/enfant :qu'est-ce qui est le plus rapide ? Visitez Comment utiliser SQL Server HierarchyID à travers des exemples simples .
- Les requêtes de base de données de graphes peuvent-elles être plus performantes que leurs équivalents relationnels dans un système de recommandation en temps réel ? Découvrez Comment utiliser les fonctionnalités de la base de données de graphes SQL Server .
- Qu'est-ce qui est le plus rapide :COALESCE ou ISNULL ? Découvrez-le dans Les meilleures réponses aux 5 questions brûlantes sur la fonction SQL COALESCE .
- SELECT FROM View ou SELECT FROM Tables de base – Laquelle s'exécutera le plus rapidement ? Consultez Les 3 principaux conseils que vous devez connaître pour écrire des vues SQL plus rapidement .
- CTE par rapport aux tables temporaires par rapport aux sous-requêtes. Sachez lequel gagnera dans Tout ce que vous devez savoir sur SQL CTE en un seul endroit .
- Utiliser SQL SUBSTRING dans une clause WHERE – Un piège de performance ? Voyez si c'est vrai avec des exemples dans How to Parse Strings Like a Pro Using SQL SUBSTRING() Function ?
- SQL UNION ALL est plus rapide que UNION. Découvrez pourquoi dans Cheat Sheet SQL UNION avec 10 conseils simples et utiles .