Cet article traite des bases de la recherche sémantique, y compris une présentation complète de la recherche sémantique :partir de zéro et terminer avec une fonctionnalité prête à l'emploi.
De plus, les lecteurs vont découvrir certaines des fonctionnalités de recherche très utiles mais peu connues disponibles dans SQL Server, comme la recherche sémantique, que nous allons démontrer avec quelques exemples de base.
Cet article souligne également l'importance de la recherche sémantique pour une forme d'analyse spécifique qui ne peut pas être effectuée avec une recherche ordinaire.
Qu'est-ce que la recherche sémantique ?
Voyons d'abord ce qu'est exactement la recherche sémantique et en quoi elle diffère de la recherche en texte intégral.
Définition Microsoft
Selon la documentation de Microsoft, la recherche sémantique fournit un aperçu approfondi des documents non structurés.
Définition alternative
La recherche sémantique est une technologie ou une fonctionnalité de recherche spéciale utilisée pour effectuer une recherche complète ou une analyse comparative principalement dans des données ou des documents non structurés, tels que des documents MS Word, à condition que les données non structurées soient stockées dans la base de données SQL Server.
Compatibilité
La recherche sémantique est uniquement compatible avec SQL Server 2012 et les versions ultérieures.
N'oubliez pas que la recherche sémantique n'est pas compatible avec la base de données SQL Azure ou les solutions cloud d'entrepôt de données Azure.
Cela signifie que vous devez travailler avec une machine virtuelle sur Azure ou sur une instance SQL Server sur site pour utiliser cette fonctionnalité puissante.
Recherche sémantique vs recherche en texte intégral
Selon la documentation de Microsoft, la recherche en texte intégral vous permet d'interroger les mots d'un document ; la recherche sémantique permet d'interroger la signification du document.
La recherche sémantique et la recherche en texte intégral représentent une fonctionnalité conjointe offerte par Microsoft SQL Server, et vous pouvez choisir de les installer lors de l'installation de votre instance SQL Server ou ultérieurement, en ajoutant de nouvelles fonctionnalités à votre instance SQL existante.
Prérequis
Passons en revue les conditions préalables à l'utilisation générale de la recherche sémantique ainsi que certaines des choses requises pour suivre la ou les procédures pas à pas de cet article.
Recherche en texte intégral installée
Il est obligatoire de savoir comment configurer la recherche en texte intégral puisque la recherche en texte intégral et la recherche sémantique sont toutes deux proposées en tant que fonctionnalité conjointe.
Veuillez vous référer à l'article Implémentation de la recherche en texte intégral dans SQL Server 2016 pour les débutants afin de configurer la recherche en texte intégral, qui est une condition préalable à l'installation de la recherche sémantique dans SQL Server.
Cet article suppose que vous avez installé la recherche en texte intégral sur votre instance SQL Server.
dbForge Studio pour SQL Server
L'utilisation de la recherche sémantique (dans la procédure pas à pas de cet article) nécessite que les données non structurées soient stockées dans la base de données SQL Server, et dans cet article, nous l'avons fait en utilisant dbForge Studio pour SQL Server plutôt que d'enregistrer directement les données non structurées dans SQL Server.
SQL Server 2016
Nous utilisons SQL Server 2016 dans cet article, mais les étapes devraient presque être les mêmes pour toute autre version compatible.
Configurer la recherche sémantique
Pour utiliser la recherche sémantique ou la recherche sémantique statistique, vous pouvez l'installer lors de l'installation de la recherche en texte intégral ou ultérieurement, en ajoutant la recherche en texte intégral et la recherche sémantique en tant que nouvelle fonctionnalité.
Vérification de la recherche en texte intégral
Veuillez vérifier l'état d'installation de la recherche en texte intégral et de la recherche sémantique en exécutant le script suivant sur la base de données principale :
-- Full-Text Search and Semantic Search status
SELECT SERVERPROPERTY('IsFullTextInstalled') as [Full-Text-Search-and-Semantic-Search-Installed];
GO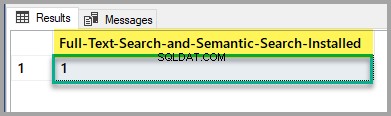
Si la sortie est 1, alors vous êtes prêt à partir, mais si c'est 0, veuillez vous référer à l'article mentionné ci-dessus pour installer la fonction de recherche en texte intégral et de recherche sémantique à l'aide de la configuration de SQL Server.
Installer la base de données de statistiques de langage sémantique
Installez la base de données de statistiques de langage sémantique en recherchant Microsoft® SQL Server® 2016 Semantic Language Statistics sur Internet ou en cliquant sur le lien suivant.
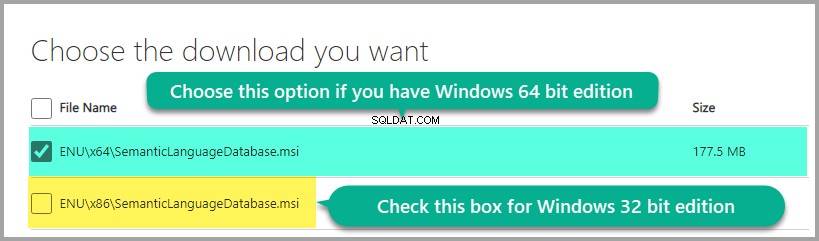
Sélection du téléchargement en fonction de votre édition Windows :
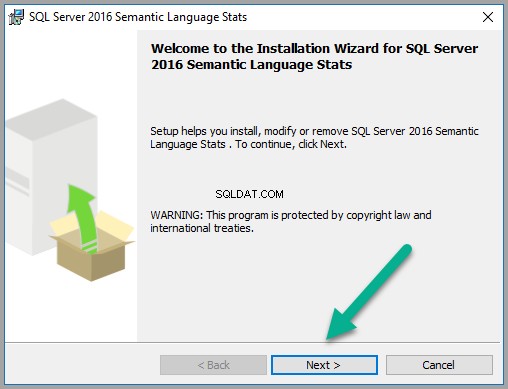
Installez la base de données des langues :
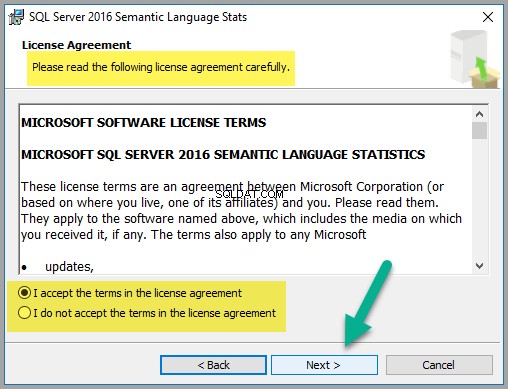
Cliquez sur Suivant pour continuer si vous êtes d'accord avec les termes du contrat de licence :
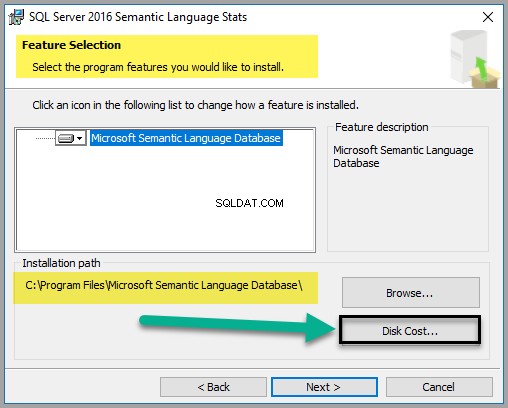
Laissez les options par défaut telles quelles, mais il est recommandé de vérifier le coût du disque comme indiqué ci-dessous :
Bien que le fichier n'occupe qu'environ 747 Mo d'espace (au moment de la rédaction de cet article), vérifiez le coût du disque pour vous assurer que vous disposez de suffisamment d'espace :
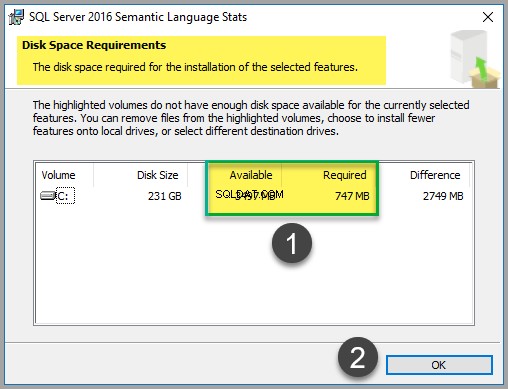
Une fois que vous avez terminé la vérification du coût du disque, cliquez sur OK puis cliquez sur Suivant .
Il vous sera demandé d'installer le fichier, veuillez cliquer sur Installer (si cela vous intéresse) :
Cliquez sur Terminer une fois l'installation terminée avec succès, ce qui devrait ressembler à la capture d'écran ci-dessous :
Localisez le dossier dans lequel la base de données de langage sémantique a été installée par défaut (C:\Program Files\Microsoft Semantic Language Database) :
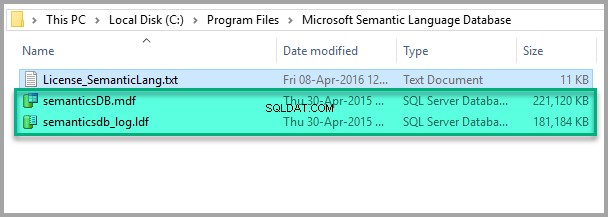
Tout semble bon, alors copiez le fichier Data and Log dans le dossier Data de votre instance SQL, comme indiqué ci-dessous :
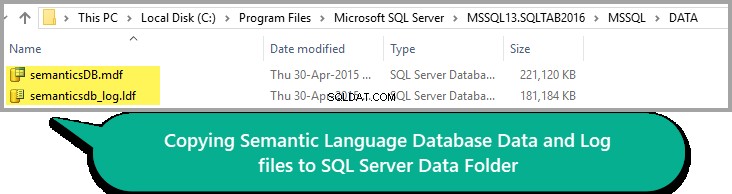
N'oubliez pas que le chemin du dossier DATA peut varier en fonction de votre version de SQL Server.
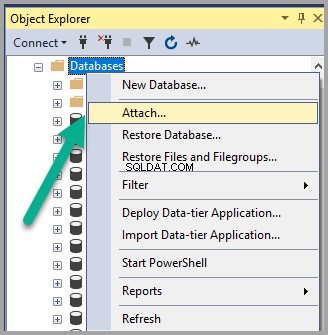
Attacher la base de données de langage sémantique à l'instance SQL
Cliquez avec le bouton droit sur les bases de données nœud sous Object Explorer dans SSMS (SQL Server Management Studio) et cliquez sur Joindre :
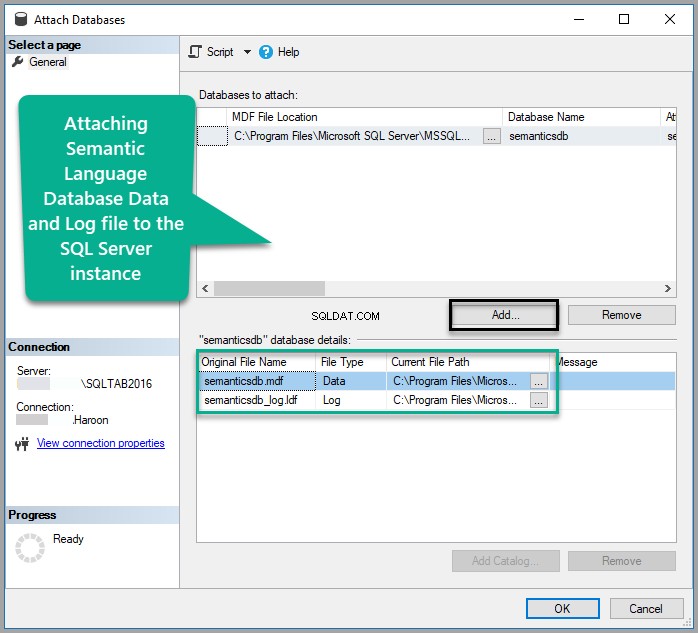
Ajouter Semanticsdb.mdf et cliquez sur OK :
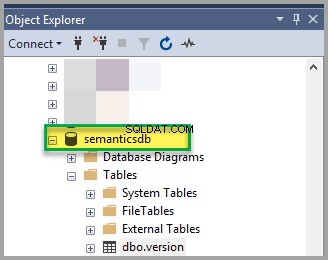
Afficher la base de données :
Enregistrer la base de données sémantique
Tapez le script suivant sur la base de données principale pour enregistrer la base de données de statistiques sémantiques sur les langues :
-- Register Semantic Language Statistics Database
EXEC sp_fulltext_semantic_register_language_statistics_db @dbname = N'semanticsdb';
GOVérifiez l'état de la base de données sémantique
Vérifiez l'état de la base de données de statistiques de langage sémantique en exécutant le script suivant sur la base de données principale :
-- Check Semantic Language Statistics Database status
SELECT * FROM sys.fulltext_semantic_language_statistics_database;
GOLa sortie ne doit pas être vide et serait la suivante :

N'oubliez pas que les valeurs ci-dessus peuvent différer sur votre machine, ce qui est normal tant que vous voyez une ligne, cela signifie que la base de données de statistiques de langage sémantique a été installée avec succès sur votre instance SQL.
Utiliser la recherche sémantique
Une fois la recherche sémantique configurée, nous sommes prêts à l'utiliser dans SQL Server.
Scénario de recherche sémantique
Nous allons stocker les documents des employés (échantillons) au format texte enrichi dans la base de données SQL Server pour être recherchés et comparés ultérieurement à l'aide de la recherche sémantique.
Configurer une base de données EmployeesSample
Créez un exemple de base de données avec une seule table en exécutant le script T-SQL sur la base de données principale comme suit :
-- (1) Setup sample database
Create DATABASE EmployeesSample;
GO
USE EmployeesSample
-- (2) Create EmployeesForSemanticSearch table
CREATE TABLE [dbo].[EmployeesForSemanticSearch](
[EmpID] [int] NOT NULL,
[DocumentName] [varchar](200) NULL,
[EmpDocument] [varbinary](max) NULL,
[EmpDocumentType] [varchar](200) NULL,
CONSTRAINT [PK_EmployeesForSemanticSearch_EmpID] PRIMARY KEY CLUSTERED
(
[EmpID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GOVérifiez l'exemple de base de données
Exécutez le script suivant uniquement pour vérifier l'exemple de table de base de données :
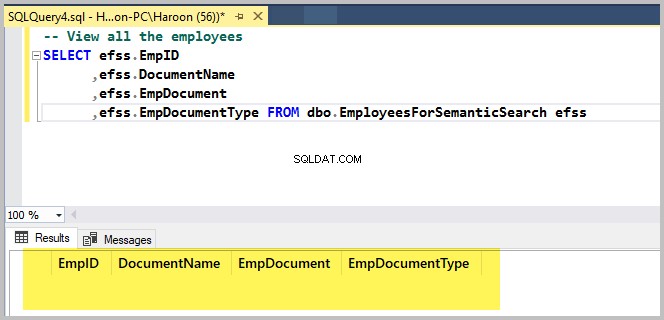
-- View all the employees
SELECT efss.EmpID
,efss.DocumentName
,efss.EmpDocument
,efss.EmpDocumentType FROM dbo.EmployeesForSemanticSearch efssLe résultat est le suivant :
Ajouter le premier fichier de texte enrichi à l'aide de dbForge Studio pour SQL Server
Nous allons ajouter des données binaires aux tables, qui sont représentées par des fichiers de texte enrichi, en utilisant dbForge Studio for SQL Server .
Ouvrez l'exemple de base de données EmployeesSample dans dbForge Studio pour SQL Server.
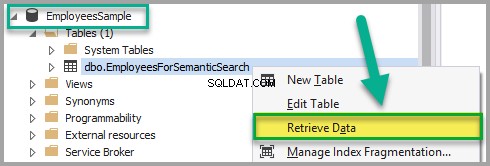
Cliquez avec le bouton droit sur EmployeesForSemanticSearch table et cliquez sur Récupérer les données :
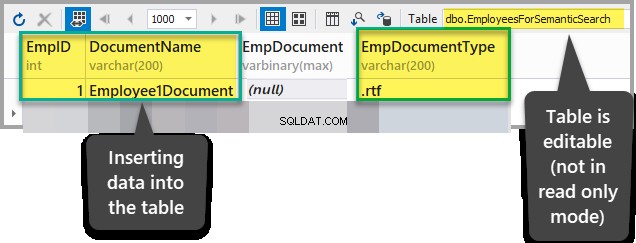
Ajoutez les données suivantes à EmployeesForSemanticSearch table sauf pour EmpDocument colonne après s'être assuré que la table n'est pas en mode lecture seule :
EmpID :1
Nom du document :Employee1Document
EmpDocument :(null)
EmpDocumentType :.rtf
Insérez un document au format RTF dans EmpDocument colonne en ajoutant le texte suivant dans le tableau (en cliquant sur les points de suspension et en ajoutant les données) :
This is a research based article and it is a new research which is in process but this is superb in the field of research.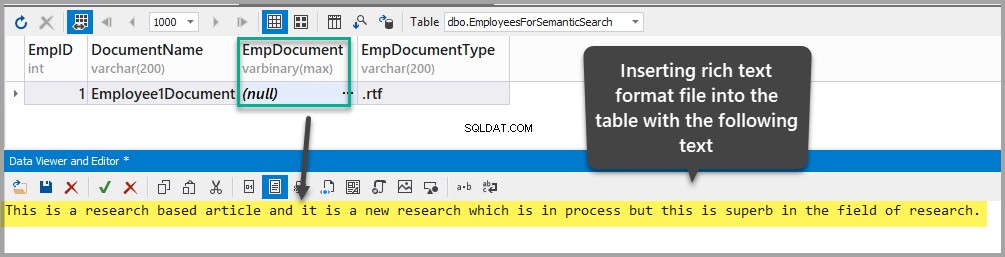
Enregistrez le document sous Employee1Document.rtf dans n'importe quel dossier Windows approprié :
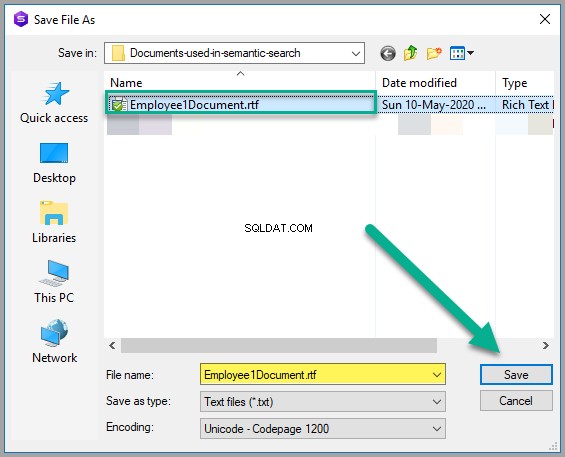
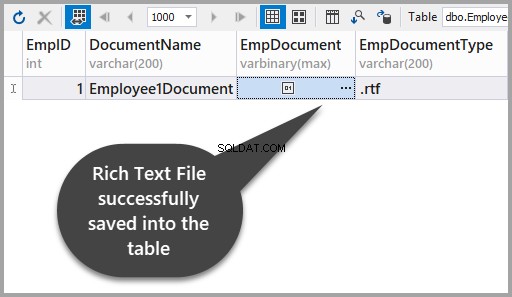
Veuillez appliquer les modifications pour vérifier que vous avez correctement stocké un fichier texte enrichi dans le tableau :
Ajouter le deuxième fichier de texte enrichi à l'aide de dbForge Studio pour SQL Server
Ensuite, ajoutez un autre fichier texte enrichi au EmployeesForSemanticSearch tableau de la même manière que ci-dessus en utilisant les informations suivantes :
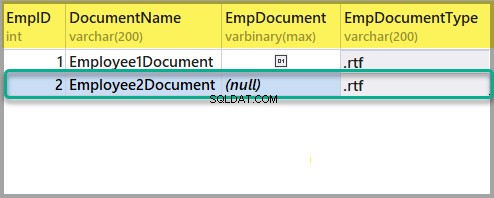
EmpID : 2
Nom du document :Employee2Document
EmpDocument :(null)
EmpDocumentType :.rtf
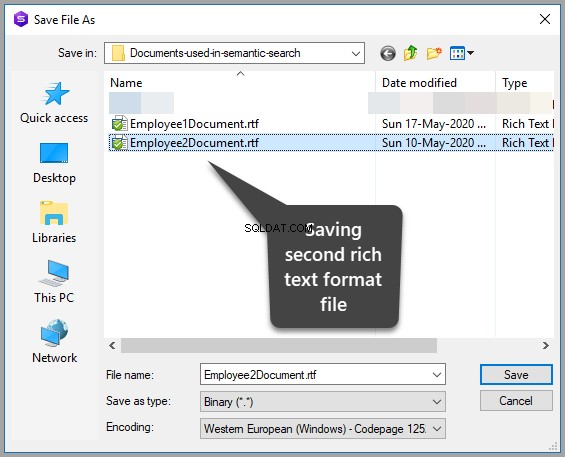
Ajoutez un autre fichier texte enrichi avec le texte suivant :
This is an article which is about facts and figures with little research in it it talks about fact and figures just facts and figures.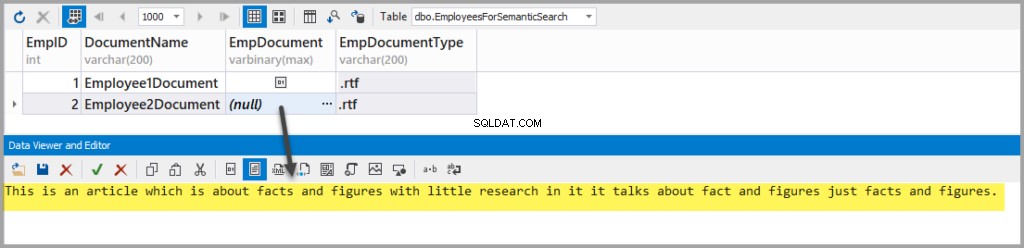
Enregistrez le document dans le même dossier comme suit :
Enregistrez les données en actualisant le tableau puis confirmez les modifications que vous venez d'effectuer en cliquant sur oui :
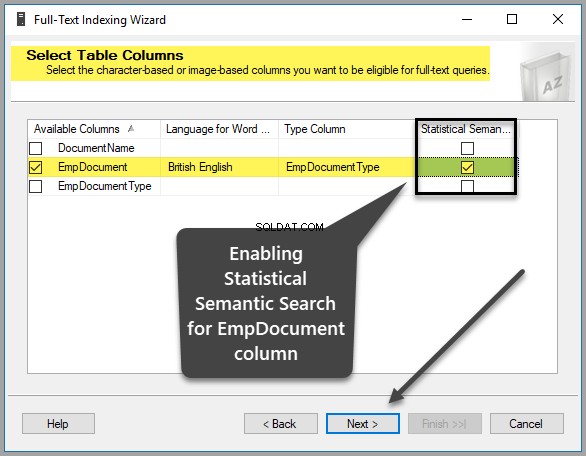
Créer un index unique, un index de texte intégral et un index sémantique à l'aide de l'assistant
De retour dans SSMS (SQL Server Management Studio), cliquez avec le bouton droit sur la table et cliquez sur Index de texte intégral puis cliquez sur Définir l'index de texte intégral… comme indiqué ci-dessous :
Ensuite, vous devez sélectionner un index unique, qui est en fait sélectionné par défaut, car nous avons créé EmpID colonne de clé primaire plus tôt comme indiqué ci-dessous, par conséquent, cliquez sur Suivant pour continuer :
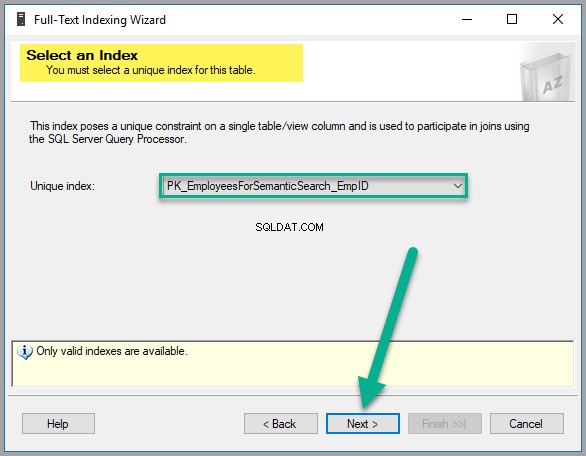
Veuillez sélectionner EmpDocument à partir des colonnes disponibles , anglais britannique comme Langage pour Word Breaker , EmpDocumentType en tant que colonne de type et cochez la recherche sémantique statistique case dans la même ligne comme suit :
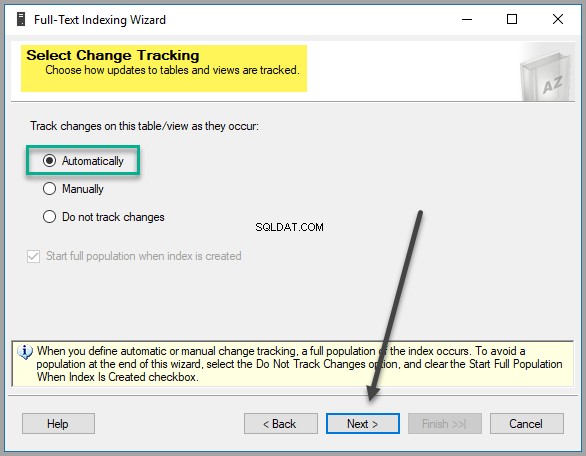
Sélectionnez l'option de suivi des modifications en laissant les paramètres par défaut, sauf si vous avez une bonne raison de modifier ces paramètres :
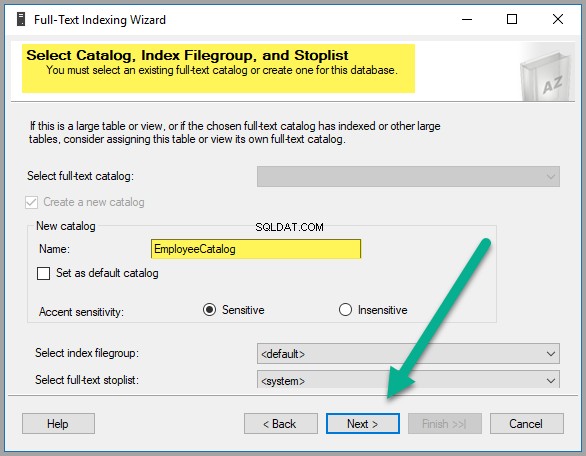
Créer un nouveau catalogue en tant que Catalogue des employés :
Cliquez sur Suivant encore :
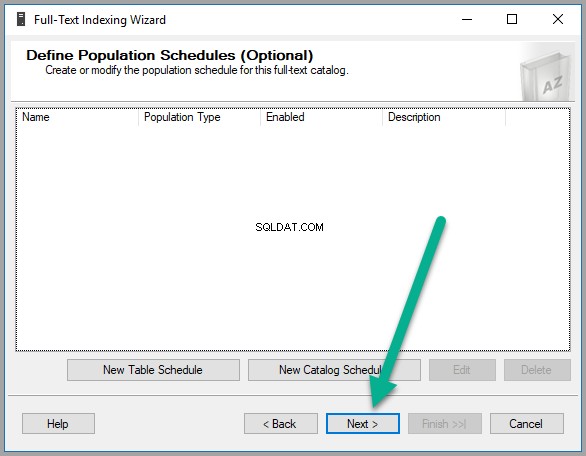
Enfin, après quelques clics supplémentaires (Cliquez sur Suivant ), la table requise est prête à être interrogée par la recherche sémantique :
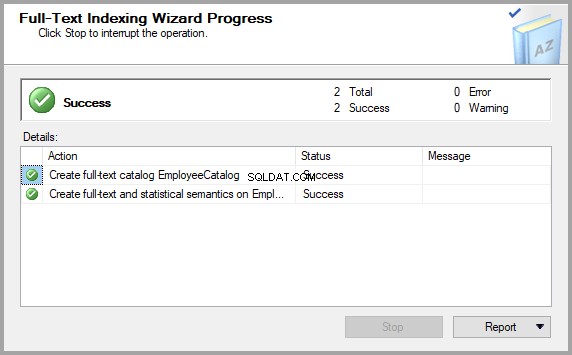
Vérifier si la recherche sémantique est activée pour une table
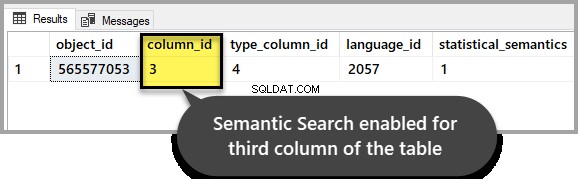
Veuillez vérifier si la recherche sémantique reste intacte pour la table qui vous intéresse en exécutant le script suivant sur l'exemple de base de données :
-- Check if Semantic Search is enabled for a database, table, and column
SELECT * FROM sys.fulltext_index_columns WHERE object_id = OBJECT_ID('EmployeesForSemanticSearch')
GOLe résultat doit indiquer qu'il a été activé pour la troisième colonne, comme nous l'avons configuré au début de la procédure pas à pas :
Exemple 1 :Utilisation du score de recherche sémantique pour trouver un document pertinent
Nous pouvons maintenant utiliser la recherche sémantique pour comparer deux documents afin de trouver un mot-clé d'intérêt et son score relatif, ce qui nous aide à nous diriger vers des documents plus pertinents.
Si nous sommes intéressés à voir le document où le mot "recherche ” est mentionné plus souvent que l'autre document, alors nous devons garder un œil sur le score de chacun des documents lorsque nous exécutons le script T-SQL suivant :
-- Using Semantic Search to find the score for the word research in both documents
SELECT TOP (100) DOC_TBL.EmpID, DOC_TBL.EmpDocumentType,KEYP_TBL.keyphrase,
KEYP_TBL.score
FROM
EmployeesForSemanticSearch AS DOC_TBL
INNER JOIN SEMANTICKEYPHRASETABLE
(
EmployeesForSemanticSearch,
EmpDocument
) AS KEYP_TBL
ON DOC_TBL.EmpID = KEYP_TBL.document_key
WHERE KEYP_TBL.keyphrase = 'research'
ORDER BY KEYP_TBL.Score DESC;Le résultat de la requête ci-dessus est le suivant :
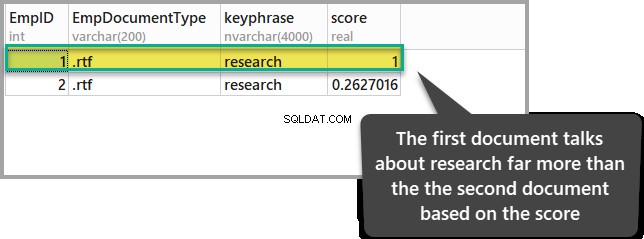
Le document avec le score le plus élevé montre qu'il a plus de pertinence par rapport à l'autre document en ce qui concerne notre point d'intérêt (recherche).
Exemple 2 :Utilisation du score de recherche sémantique pour trouver un document pertinent
Nous pouvons également trouver le document où le mot "fait" domine par rapport à tout autre document en exécutant le script ci-dessous :
-- Using Semantic Search to find the score for the word fact in both documents
SELECT TOP (100) DOC_TBL.EmpID, DOC_TBL.EmpDocumentType,KEYP_TBL.keyphrase,
KEYP_TBL.score
FROM
EmployeesForSemanticSearch AS DOC_TBL
INNER JOIN SEMANTICKEYPHRASETABLE
(
EmployeesForSemanticSearch,
EmpDocument
) AS KEYP_TBL
ON DOC_TBL.EmpID = KEYP_TBL.document_key
WHERE KEYP_TBL.keyphrase = 'fact'
ORDER BY KEYP_TBL.Score DESC;Les résultats sont les suivants :
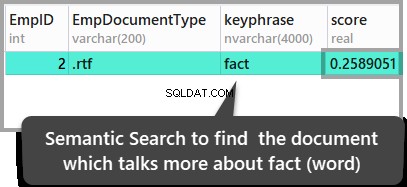
Les résultats ci-dessus conduisent à la conclusion que le deuxième document stocké est le seul document où le mot fait est mentionné, mais si vous souhaitez vérifier ces résultats, ouvrez les documents stockés pour les consulter.
Toutes nos félicitations! Vous avez non seulement appris à configurer la recherche sémantique dans SQL Server, mais vous avez également acquis une expérience pratique de l'utilisation de la recherche sémantique.
Choses à faire
Maintenant que vous pouvez configurer et rédiger des requêtes de recherche sémantique de base, essayez ce qui suit pour améliorer encore vos compétences :
- Essayez d'ajouter un autre document qui parle de recherche puis exécutez le script du premier exemple pour voir quel document est le document le plus pertinent en comparant leurs scores.
- En gardant cet article à l'esprit, ajoutez un autre document où le mot fait est mentionné plusieurs fois, puis exécutez le T-SQL dans l'exemple 2 de cet article pour voir si les résultats restent les mêmes ou changent.
- Essayez d'utiliser la recherche sémantique en ajoutant plus de documents et de texte aux documents existants et nouveaux, puis en trouvant les documents qui correspondent aux mots qui vous intéressent.
- Explorez les exemples plus loin pour découvrir par vous-même si la recherche sémantique est sensible ou insensible à la casse (Astuce :vous pouvez légèrement modifier les exemples).