Selon Wikipedia, l'insertion en bloc est un processus ou une méthode fourni par un système de gestion de base de données pour charger plusieurs lignes de données dans une table de base de données. Si nous ajustons cette explication à l'instruction BULK INSERT, l'insertion en bloc permet d'importer des fichiers de données externes dans SQL Server.
Supposons que notre organisation dispose d'un fichier CSV de 1 500 000 lignes et que nous souhaitions l'importer dans une table particulière de SQL Server pour utiliser l'instruction BULK INSERT dans SQL Server. Nous pouvons trouver plusieurs méthodes pour gérer cette tâche. Il pourrait utiliser BCP (b ulk c copier p programme), l'Assistant d'importation et d'exportation SQL Server ou le package SQL Server Integration Service. Cependant, l'instruction BULK INSERT est beaucoup plus rapide et puissante. Un autre avantage est qu'il offre plusieurs paramètres aidant à déterminer les paramètres du processus d'insertion en bloc.
Commençons par un échantillon de base. Ensuite, nous passerons par des scénarios plus sophistiqués.
Préparation
Tout d'abord, nous avons besoin d'un exemple de fichier CSV. Nous téléchargeons un exemple de fichier CSV à partir du site Web E for Excel (une collection d'échantillons de fichiers CSV avec un numéro de ligne différent). Ici, nous allons utiliser 1 500 000 enregistrements de ventes.
Téléchargez un fichier zip, décompressez-le pour obtenir un fichier CSV et placez-le sur votre lecteur local.
Importer un fichier CSV dans la table SQL Server
Nous importons notre fichier CSV dans la table de destination sous la forme la plus simple. J'ai placé mon exemple de fichier CSV sur le lecteur C:. Nous créons maintenant une table pour y importer les données du fichier CSV :
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
L'instruction BULK INSERT suivante importe le fichier CSV dans la table Sales :
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Vous avez probablement noté les paramètres spécifiques de l'instruction d'insertion en bloc ci-dessus. Clarifions-les :
- PREMIER spécifie le point de départ de l'instruction d'insertion. Dans l'exemple ci-dessous, nous voulons ignorer les en-têtes de colonne, nous définissons donc ce paramètre sur 2.

- TERMINATEUR DE CHAMP définit le caractère qui sépare les champs les uns des autres. SQL Server détecte chaque champ de cette manière.
- ROWTERMINATOR ne diffère pas beaucoup de FIELDTERMINATOR. Il définit le caractère de séparation des lignes.
Dans l'exemple de fichier CSV, FIELDTERMINATOR est très clair et il s'agit d'une virgule (,). Pour détecter ce paramètre, ouvrez le fichier CSV dans Notepad++ et accédez à Affichage -> Afficher le symbole -> Afficher toutes les chartes. Les caractères CRLF se trouvent à la fin de chaque champ.
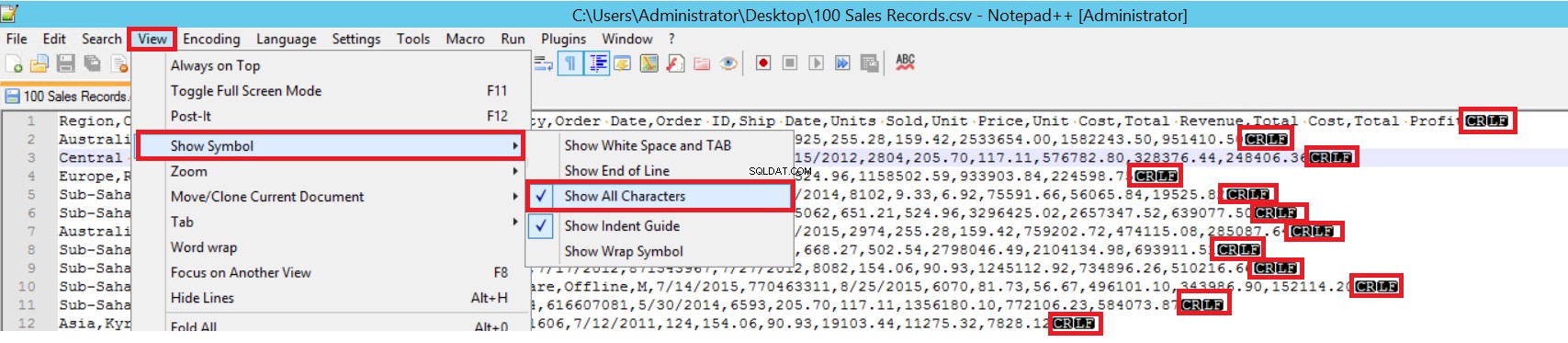
CR =retour chariot et LF =saut de ligne. Ils sont utilisés pour marquer un saut de ligne dans un fichier texte. L'indicateur est "\n" dans l'instruction d'insertion en bloc.
Une autre façon d'importer un fichier CSV dans une table avec insertion en bloc consiste à utiliser le paramètre FORMAT. Notez que ce paramètre est disponible uniquement dans SQL Server 2017 et versions ultérieures.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
C'était le scénario le plus simple où la table de destination et le fichier CSV ont un nombre égal de colonnes. Cependant, le cas où la table de destination a plus de colonnes, alors le fichier CSV est typique. Considérons-le.
Nous ajoutons une clé primaire à la table Sales pour rompre les mappages de colonnes d'égalité. Nous créons la table Sales avec une clé primaire et importons le fichier CSV via la commande d'insertion en bloc.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Mais cela produit une erreur :
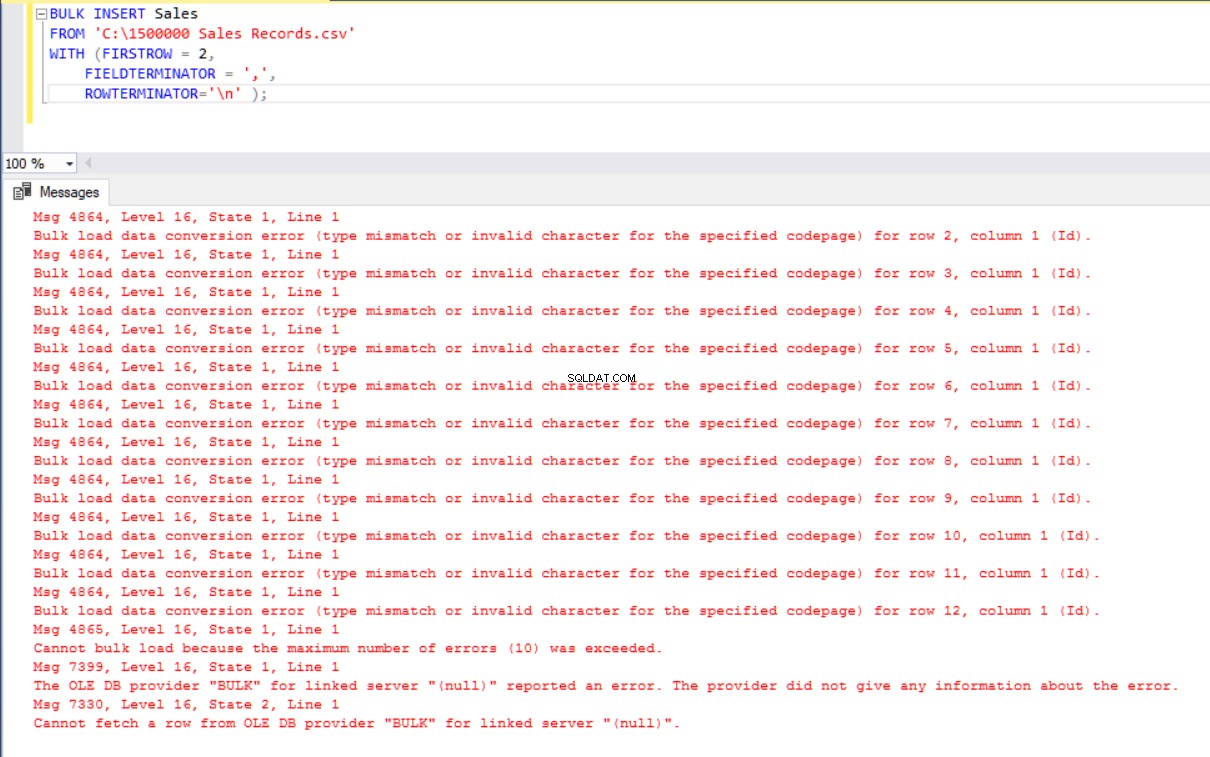
Pour surmonter l'erreur, nous créons une vue de la table Sales avec des colonnes de mappage dans le fichier CSV. Ensuite, nous importons les données CSV sur cette vue dans la table Sales :
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Séparez et chargez un gros fichier CSV dans un petit lot
SQL Server acquiert un verrou sur la table de destination lors de l'opération d'insertion en bloc. Par défaut, si vous ne définissez pas le paramètre BATCHSIZE, SQL Server ouvre une transaction et y insère l'intégralité des données CSV. Avec ce paramètre, SQL Server divise les données CSV en fonction de la valeur du paramètre.
Divisons l'ensemble des données CSV en plusieurs ensembles de 300 000 lignes chacun.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 ); Les données seront importées cinq fois par parties.
- Si votre instruction d'insertion en bloc n'inclut pas le paramètre BATCHSIZE, une erreur se produit et le serveur SQL annulera tout le processus d'insertion en bloc.
- Avec ce paramètre défini sur l'instruction d'insertion en bloc, SQL Server annule uniquement la partie où l'erreur s'est produite.
Il n'existe pas de valeur optimale ou optimale pour ce paramètre, car sa valeur peut changer en fonction des exigences de votre système de base de données.
Définissez le comportement en cas d'erreur
Si une erreur se produit dans certains scénarios de copie en bloc, nous pouvons soit annuler le processus de copie en bloc, soit le poursuivre. Le paramètre MAXERRORS nous permet de spécifier le nombre maximum d'erreurs. Si le processus d'insertion en bloc atteint cette valeur d'erreur maximale, il annule l'opération d'importation en bloc et annule. La valeur par défaut de ce paramètre est 10.
Par exemple, nous avons des types de données corrompus dans 3 lignes du fichier CSV. Le paramètre MAXERRORS est défini sur 2.

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2); Toute l'opération d'insertion en bloc sera annulée car il y a plus d'erreurs que la valeur du paramètre MAXERRORS.
Si nous modifions le paramètre MAXERRORS sur 4, l'instruction d'insertion en bloc ignorera ces lignes contenant des erreurs et insèrera les lignes structurées de données correctes. Le processus d'insertion en bloc sera terminé.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
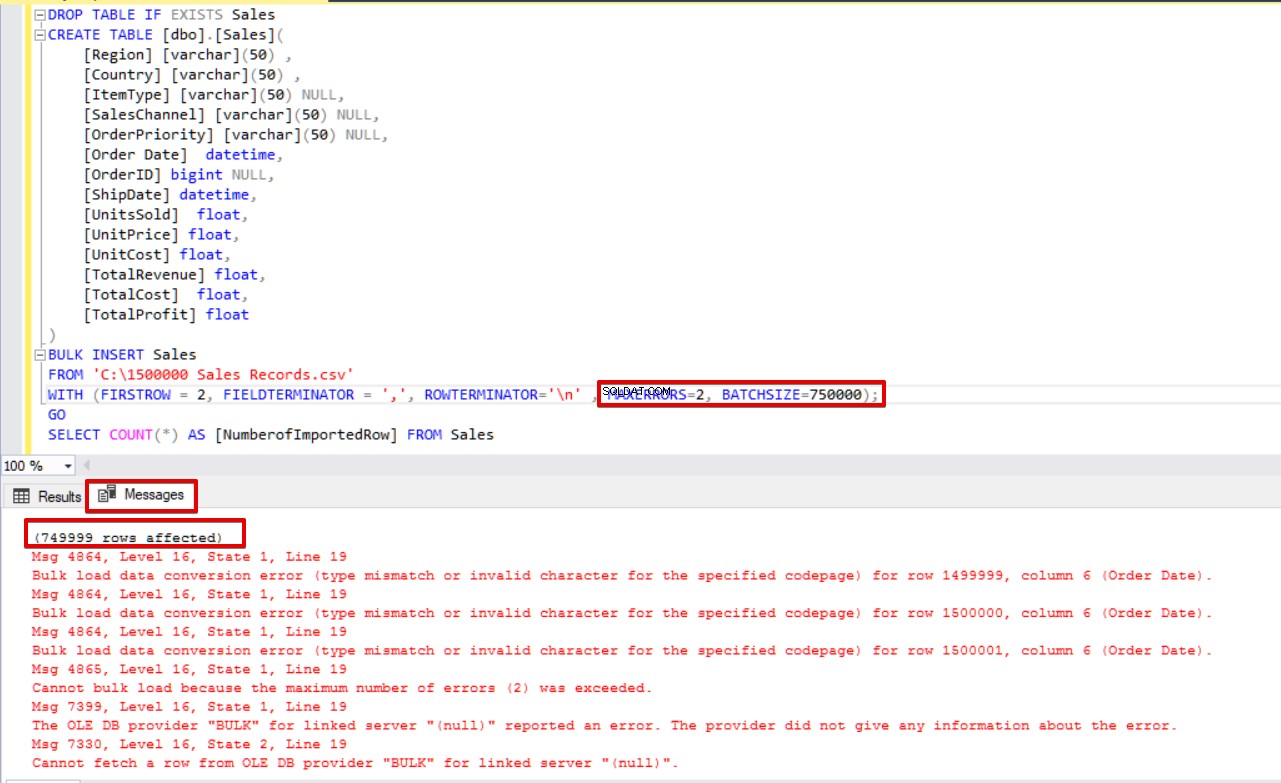
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales Si nous utilisons simultanément BATCHSIZE et MAXERRORS, le processus de copie en bloc n'annulera pas toute l'opération d'insertion. Cela n'annulera que la partie divisée.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales Regardez l'image ci-dessous qui montre le résultat de l'exécution du script :
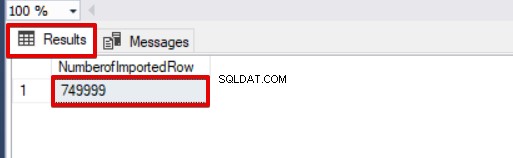
Autres options du processus d'insertion groupée
FIRE_TRIGGERS - active les déclencheurs dans la table de destination lors de l'opération d'insertion en masse
Par défaut, lors du processus d'insertion en bloc, les déclencheurs d'insertion spécifiés dans la table cible ne sont pas déclenchés. Néanmoins, dans certaines situations, nous pouvons vouloir les activer.
La solution utilise l'option FIRE_TRIGGERS dans les instructions d'insertion en bloc. Mais veuillez noter que cela peut affecter et diminuer les performances de l'opération d'insertion en masse. C'est parce que le déclencheur/les déclencheurs peuvent effectuer des opérations distinctes dans la base de données.
Au début, nous ne définissons pas le paramètre FIRE_TRIGGERS et le processus d'insertion en masse ne déclenchera pas le déclencheur d'insertion. Voir le script T-SQL ci-dessous :
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
DROP TABLE IF EXISTS SalesLog
CREATE TABLE SalesLog (OrderIDLog bigint)
GO
CREATE TRIGGER OrderLogIns ON Sales
FOR INSERT
AS
BEGIN
SET NOCOUNT ON
INSERT INTO SalesLog
SELECT OrderId from inserted
end
GO
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
SELECT Count(*) FROM SalesLogLorsque ce script s'exécute, le déclencheur d'insertion ne se déclenche pas car l'option FIRE_TRIGGERS n'est pas définie.
Ajoutons maintenant l'option FIRE_TRIGGERS à l'instruction d'insertion en bloc :
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n',
FIRE_TRIGGERS);
GO
SELECT Count(*) as [NumberOfRowsinTriggerTable] FROM SalesLog 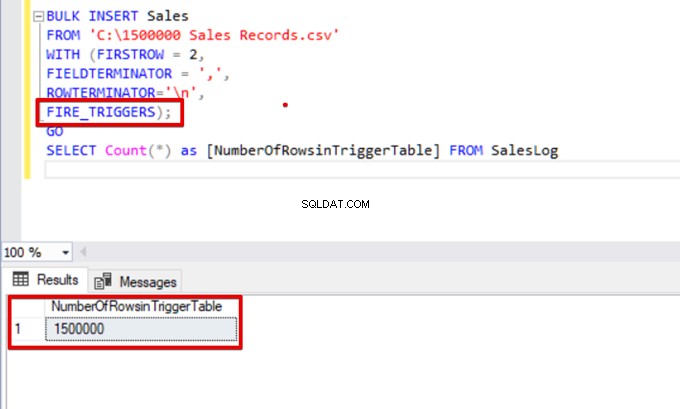
CHECK_CONSTRAINTS - active une contrainte de vérification lors de l'opération d'insertion en bloc
Les contraintes de vérification nous permettent d'appliquer l'intégrité des données dans les tables SQL Server. Le but de la contrainte est de vérifier les valeurs insérées, mises à jour ou supprimées en fonction de leur régulation syntaxique. Par exemple, la contrainte NOT NULL prévoit que la valeur NULL ne peut pas modifier une colonne spécifiée.
Ici, nous nous concentrons sur les contraintes et les interactions d'insertion en bloc. Par défaut, lors du processus d'insertion en bloc, toutes les contraintes de vérification et de clé étrangère sont ignorées. Mais il y a quelques exceptions.
Selon Microsoft, « les contraintes UNIQUE et PRIMARY KEY sont toujours appliquées. Lors de l'importation dans une colonne de caractères pour laquelle la contrainte NOT NULL est définie, BULK INSERT insère une chaîne vide lorsqu'il n'y a pas de valeur dans le fichier texte."
Dans le script T-SQL suivant, nous ajoutons une contrainte de vérification à la colonne OrderDate, qui contrôle la date de commande supérieure au 01.01.2016.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
ALTER TABLE [Sales] ADD CONSTRAINT OrderDate_Check
CHECK(OrderDate >'20160101')
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
GO
SELECT COUNT(*) AS [UnChekedData] FROM
Sales WHERE OrderDate <'20160101'Par conséquent, le processus d'insertion en bloc ignore le contrôle de contrainte de vérification. Cependant, SQL Server indique que la contrainte de vérification n'est pas approuvée :
SELECT is_not_trusted ,* FROM sys.check_constraints where name='OrderDate_Check'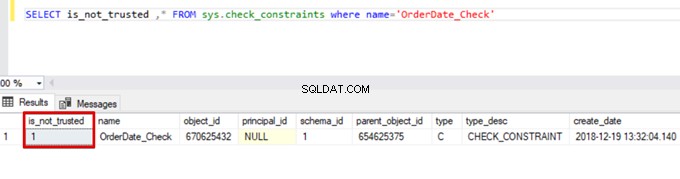
Cette valeur indique que quelqu'un a inséré ou mis à jour des données dans cette colonne en ignorant la contrainte de vérification. En même temps, cette colonne peut contenir des données incohérentes concernant cette contrainte.
Essayez d'exécuter l'instruction d'insertion en bloc avec l'option CHECK_CONSTRAINTS. Le résultat est simple :la contrainte de vérification renvoie une erreur en raison de données incorrectes.
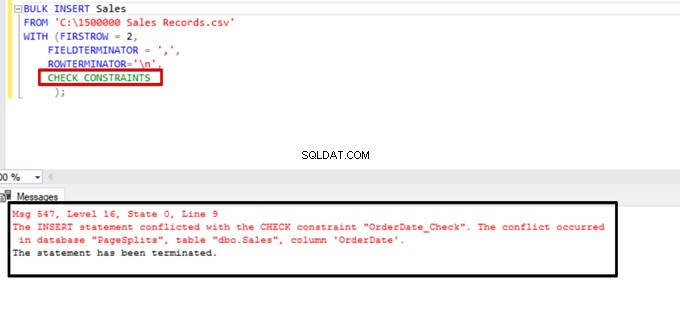
TABLOCK – améliorez les performances de plusieurs insertions en bloc dans une table de destination
L'objectif principal du mécanisme de verrouillage dans SQL Server est de protéger et de garantir l'intégrité des données. Dans le concept principal de l'article sur le verrouillage de SQL Server, vous pouvez trouver des détails sur le mécanisme de verrouillage.
Nous nous concentrerons sur les détails de verrouillage du processus d'insertion en masse.
Si vous exécutez l'instruction d'insertion en bloc sans l'option TABLELOCK, elle acquiert le verrou des lignes ou des tables en fonction de la hiérarchie des verrous. Mais dans certains cas, nous pouvons vouloir exécuter plusieurs processus d'insertion en bloc sur une table de destination et ainsi réduire le temps d'opération.
Tout d'abord, nous exécutons simultanément deux instructions d'insertion en bloc et analysons le comportement du mécanisme de verrouillage. Ouvrez deux fenêtres de requête dans SQL Server Management Studio et exécutez simultanément les instructions d'insertion en bloc suivantes.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
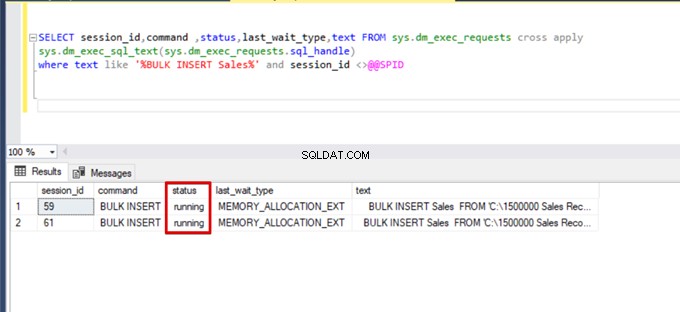
);Exécutez la requête DMV (Dynamic Management View) suivante - elle permet de surveiller l'état du processus d'insertion en bloc :
SELECT session_id,command ,status,last_wait_type,text FROM sys.dm_exec_requests cross apply
sys.dm_exec_sql_text(sys.dm_exec_requests.sql_handle)
where text like '%BULK INSERT Sales%' and session_id <>@@SPID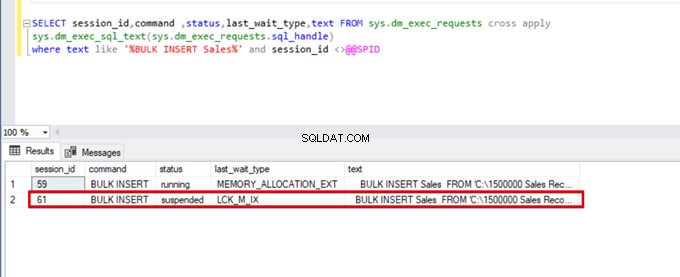
Comme vous pouvez le voir dans l'image ci-dessus, session 61, l'état du processus d'insertion en bloc est suspendu en raison d'un verrouillage. Si nous vérifions le problème, la session 59 verrouille la table de destination des insertions en bloc. Ensuite, la session 61 attend la libération de ce verrou pour continuer le processus d'insertion en masse.
Maintenant, nous ajoutons l'option TABLOCK aux instructions d'insertion en bloc et exécutons les requêtes.
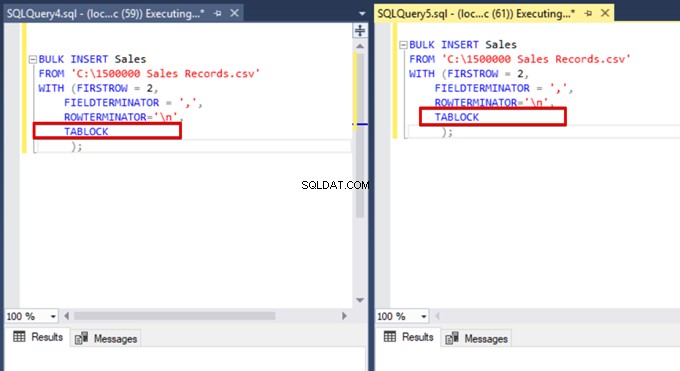
Lorsque nous exécutons à nouveau la requête de surveillance DMV, nous ne voyons aucun processus d'insertion en bloc suspendu, car SQL Server utilise un type de verrou particulier appelé verrou de mise à jour en bloc (BU). Ce type de verrou permet de traiter simultanément plusieurs opérations d'insertion en bloc sur la même table. Cette option réduit également la durée totale du processus d'insertion en masse.
Lorsque nous exécutons la requête suivante pendant le processus d'insertion en bloc, nous pouvons surveiller les détails de verrouillage et les types de verrouillage :
SELECT dm_tran_locks.request_session_id,
dm_tran_locks.resource_database_id,
DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
CASE
WHEN resource_type = 'OBJECT'
THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
ELSE OBJECT_NAME(partitions.OBJECT_ID)
END AS ObjectName,
partitions.index_id,
indexes.name AS index_name,
dm_tran_locks.resource_type,
dm_tran_locks.resource_description,
dm_tran_locks.resource_associated_entity_id,
dm_tran_locks.request_mode,
dm_tran_locks.request_status
FROM sys.dm_tran_locks
LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
LEFT JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
WHERE resource_associated_entity_id > 0
AND resource_database_id = DB_ID()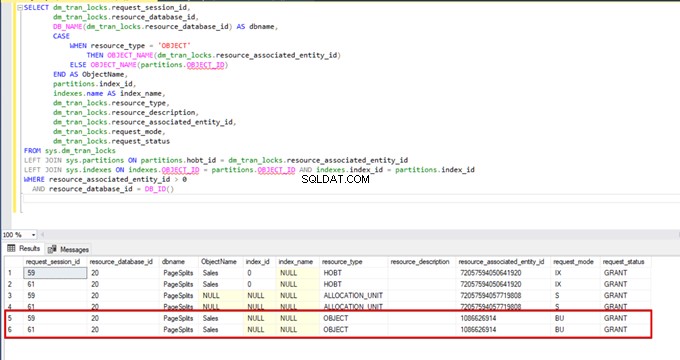
Conclusion
L'article actuel a exploré tous les détails de l'opération d'insertion en bloc dans SQL Server. Notamment, nous avons mentionné la commande BULK INSERT et ses paramètres et options. De plus, nous avons analysé divers scénarios proches de problèmes réels.
Outil utile :
dbForge Data Pump - un complément SSMS pour remplir les bases de données SQL avec des données sources externes et migrer les données entre les systèmes.



