Présentation
Dans cet article, nous verrons comment différents types d'index dans les tables à mémoire optimisée SQL Server affectent les performances. Nous examinerons des exemples de la manière dont différents types d'index peuvent affecter les performances des tables optimisées en mémoire.
Pour faciliter la discussion sur le sujet, nous utiliserons un exemple assez volumineux. Pour des raisons de simplicité, cet exemple présentera différentes répliques d'une même table, sur lesquelles nous exécuterons différentes requêtes. Ces répliques utiliseront des index différents, voire aucun index (à l'exception, bien sûr, des clés primaires - PK).
Notez que l'objectif réel de cet article n'est pas de comparer les performances entre les tables sur disque et les tables optimisées en mémoire dans SQL Server en soi. Son objectif est d'examiner comment les index affectent les performances dans les tables optimisées en mémoire. Cependant, afin d'avoir une image complète des expériences, les délais sont également fournis pour les requêtes de table sur disque correspondantes et les accélérations sont calculées en utilisant la configuration la plus optimale des tables sur disque comme lignes de base.
Scénario
Les exemples de données pour notre scénario sont basés sur un seul tableau défini comme suit :
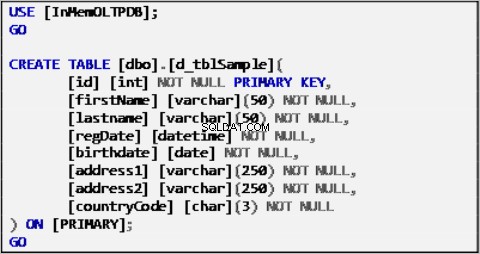
Liste 1 :Exemple de tableau de sources de données.
Le tableau ci-dessus a été rempli avec des exemples de données et servira de source de données pour le reste des tableaux.
Ainsi, sur la base du tableau ci-dessus, nous créons les 9 variantes de tableau suivantes et les remplissons avec les mêmes exemples de données :
- 3 tables sur disque :
- d_tblSample1
- Index clusterisé sur la colonne "id" - clé primaire (PK)
- d_tblSample2
- Index clusterisé sur la colonne "id" (PK)
- Index non clusterisé sur la colonne "countryCode"
- d_tblSample3
- Index clusterisé sur la colonne "id" (PK)
- Index non clusterisés sur la colonne "regDate"
- Index non clusterisés sur la colonne "countryCode"
- d_tblSample1
- 3 tables optimisées en mémoire (ensemble 1 :index de hachage) :
- m1_tblSample1
- Index de hachage non clusterisé sur la colonne "id" - clé primaire (PK)
- m1_tblSample2
- Index de hachage non clusterisé sur la colonne "id" (PK)
- Index de hachage sur la colonne "countryCode"
- m1_tblSample3
- Index de hachage non clusterisé sur la colonne "id" (PK)
- Index de hachage sur la colonne "regDate"
- Index de hachage sur la colonne "countryCode"
- 3 tables optimisées en mémoire (ensemble 2 :index non clusterisés) :
- m2_tblSample1
- Index non clusterisé sur la colonne "id" - clé primaire (PK)
- m2_tblSample2
- Index non clusterisé sur la colonne "id" (PK)
- Index non clusterisé sur la colonne "countryCode"
- m2_tblSample3
- Index non clusterisé sur la colonne "id" (PK)
- Index non clusterisé sur la colonne "regDate"
- Index non clusterisé sur la colonne "countryCode"
- m2_tblSample1
- m1_tblSample1
Dans les listes ci-dessous, vous pouvez trouver les définitions des tableaux ci-dessus.
La logique du scénario est que nous effectuons différentes opérations de base de données sur des variations de la même table (mais avec des index différents) et observons comment les performances sont affectées dans chaque cas.
Définitions
Tables basées sur disque
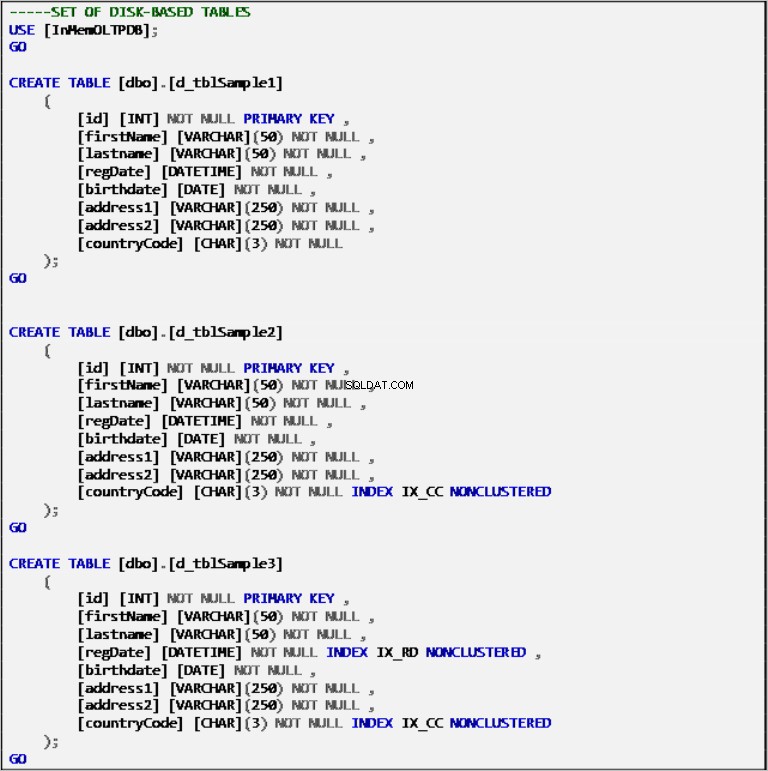
Liste 2 :Définition des tables basées sur le disque.
Tables à mémoire optimisée (ensemble 1 :index de hachage)

Liste 3 :Tables optimisées en mémoire – Ensemble 1 (index de hachage).
Tables à mémoire optimisée (ensemble 2 :index non clusterisés)

Liste 4 :Tables à mémoire optimisée – Ensemble 2 (index non clusterisés).
Ensuite, nous remplissons toutes les tables ci-dessus avec les mêmes exemples de données, soit au total 5 millions d'enregistrements dans chaque table.
Voici le résultat de la commande count pour chaque ensemble de tables :
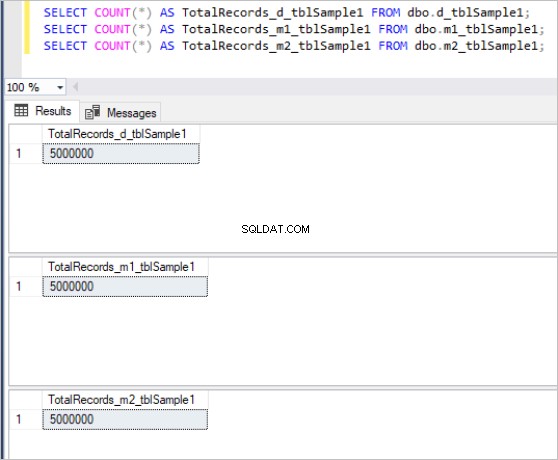
Figure 1 :Nombre total d'enregistrements pour le premier ensemble de tables.
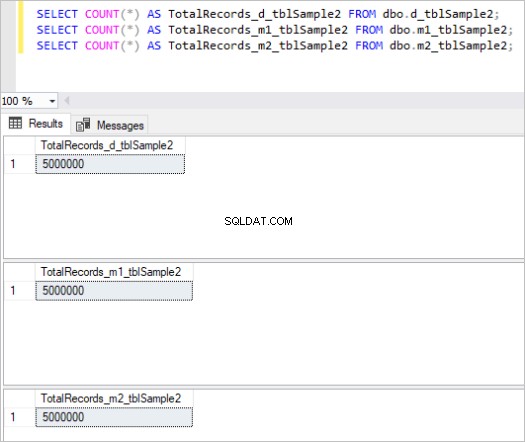
Figure 2 :Nombre total d'enregistrements pour le deuxième ensemble de tables.
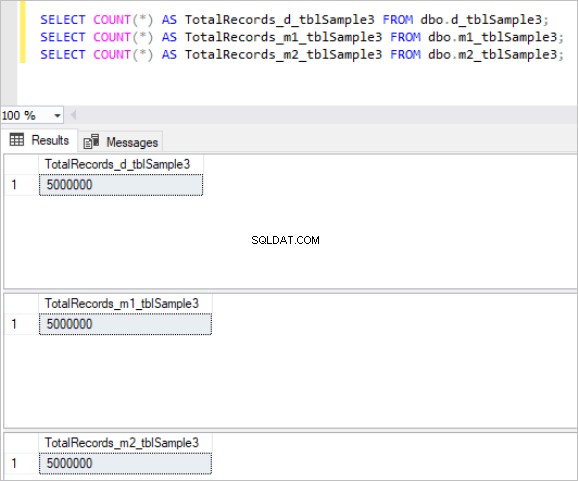
Figure 3 :Nombre total d'enregistrements pour le troisième ensemble de tables.
Requêtes et exécutions de scénarios
Maintenant, nous allons exécuter un ensemble de requêtes sur les tables ci-dessus et voir comment chaque table fonctionne.
Ces requêtes effectuent les opérations suivantes :
- Requête 1 :Agrégation (GROUP BY)
- Requête 2 :Recherche d'index sur les prédicats d'égalité
- Requête 3 :Recherche d'index sur les prédicats d'égalité et d'inégalité
Le plan est d'exécuter les requêtes comme ci-dessous :
Requête 1 – Exécution sur les tables suivantes :
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1 (pas d'index sur les colonnes cibles)
- m2_tblSample1 (pas d'index sur les colonnes cibles)
Requête 2 – Exécution sur les tables suivantes :
- d_tblSample2
- m1_tblSample2
- m2_tblSample2
- m1_tblSample1 (pas d'index sur les colonnes cibles)
- m2_tblSample1 (pas d'index sur les colonnes cibles)
Requête 3 – Exécution sur les tables suivantes :
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1 (pas d'index sur les colonnes cibles)
- m2_tblSample1 (pas d'index sur les colonnes cibles)
Remarque :Même si la définition de d_tblSample1 La table basée sur disque est incluse dans les définitions de table ci-dessus, elle n'est pas utilisée dans les requêtes fournies dans cet article. La raison en est que, dans chaque scénario, la configuration la plus optimale possible pour la table sur disque est utilisée, car nous voulons que notre ligne de base soit aussi rapide que possible lorsque nous la comparons aux performances des tables optimisées en mémoire. À cette fin, le d_tblSample1 le tableau est juste présenté à titre informatif.
Vous trouverez ci-dessous les scripts T-SQL pour les trois requêtes ainsi que les mécanismes de mesure du temps d'exécution.

Liste 5 :Requête 1 – Agrégation (avec index).
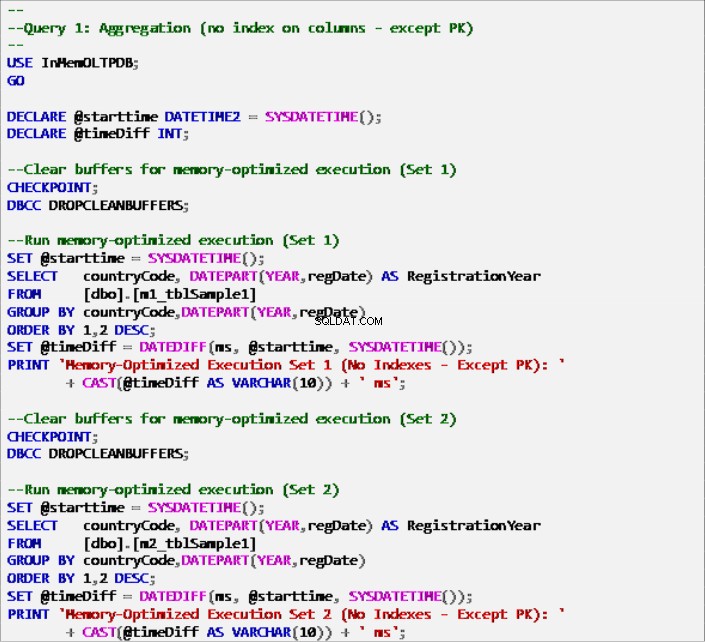
Liste 6 :Requête 1 – Agrégation (sans index – Sauf la clé primaire).
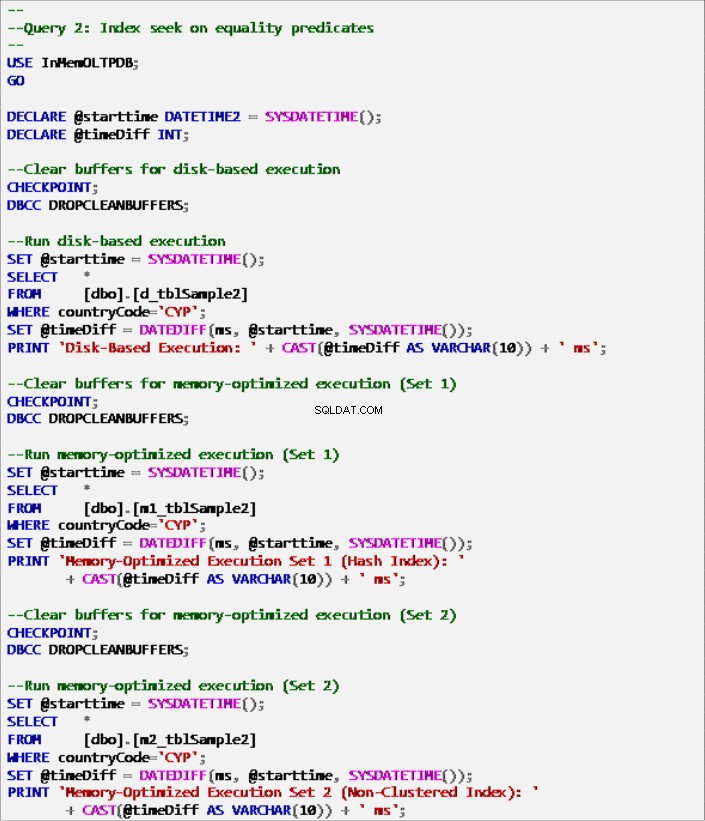
Liste 7 :Requête 2 – Recherche d'index sur les prédicats d'égalité (avec index).

Liste 8 :Requête 2 – Recherche d'index sur les prédicats d'égalité (sans index, à l'exception de la clé primaire).
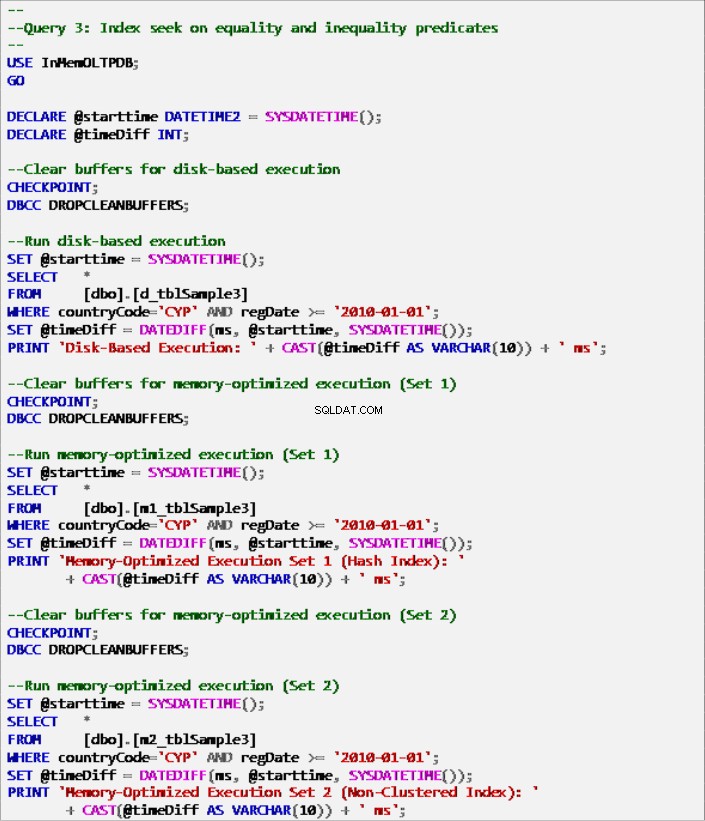
Liste 9 :Requête 3 – Recherche d'index sur les prédicats d'égalité et d'inégalité (avec index).

Liste 10 :Requête 3 – Recherche d'index sur les prédicats d'égalité et d'inégalité (sans index – sauf la clé primaire).
Les captures d'écran ci-dessous montrent le résultat de chaque exécution de requête :
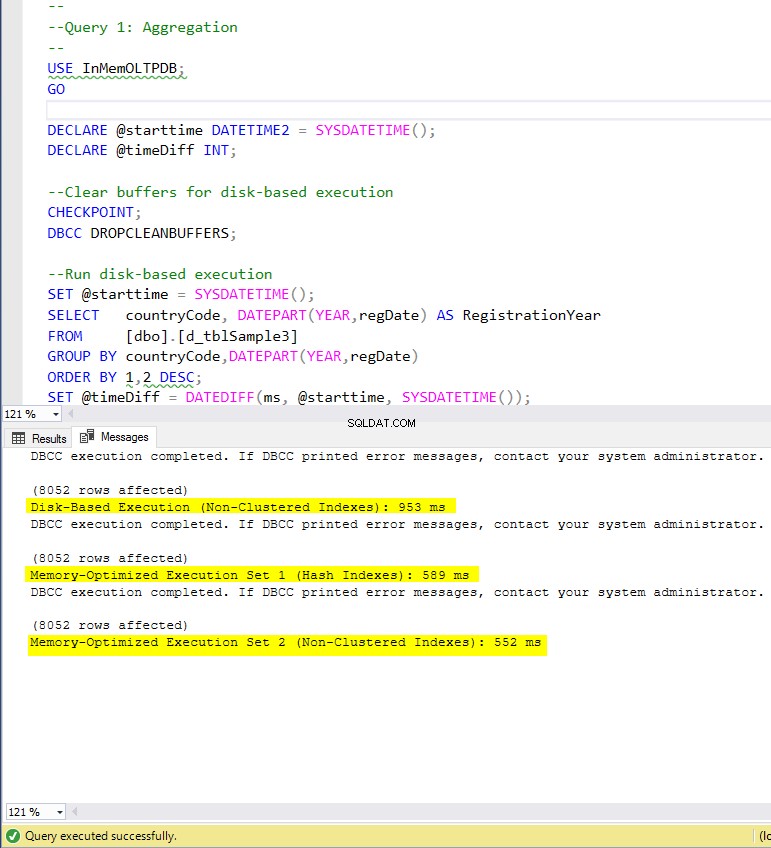
Figure 4 : Temps d'exécution de la requête 1 (avec index).
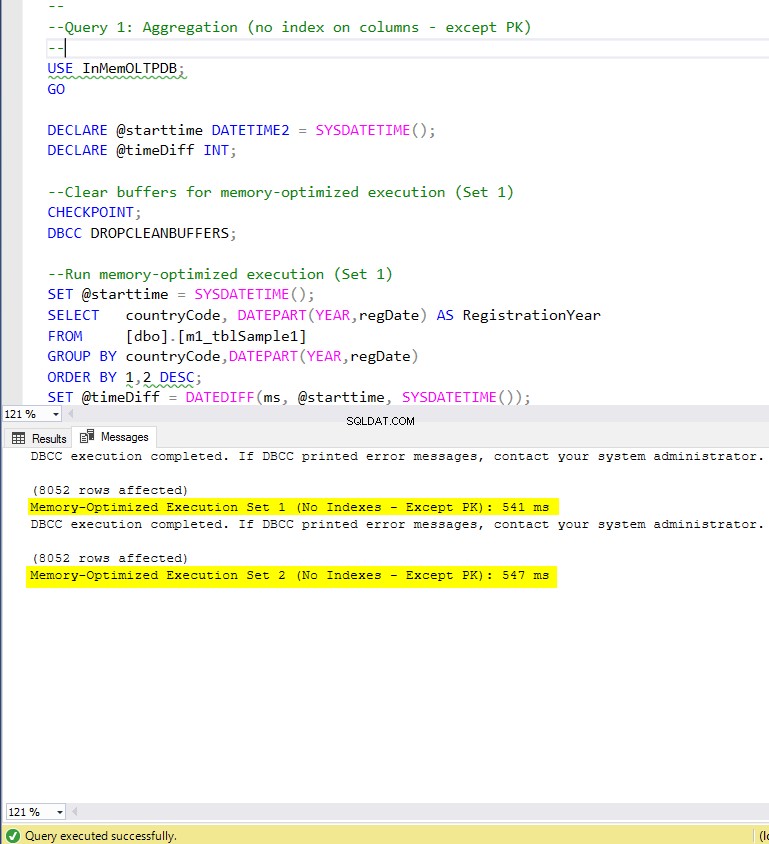
Figure 5 : Temps d'exécution de la requête 1 (sans index, à l'exception de PK).
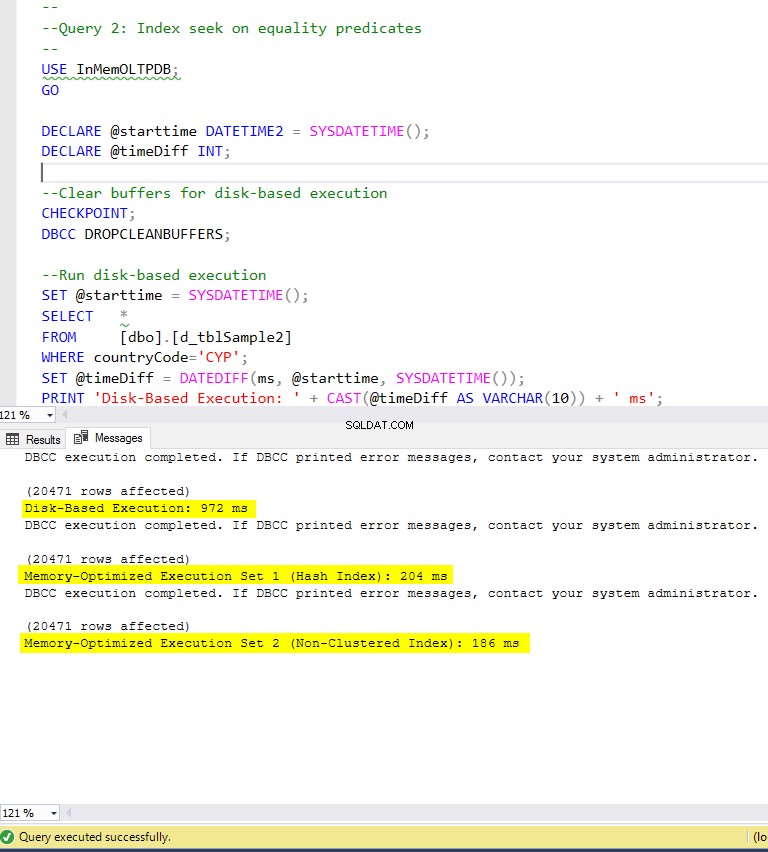
Figure 6 : Temps d'exécution de la requête 2 (avec index).
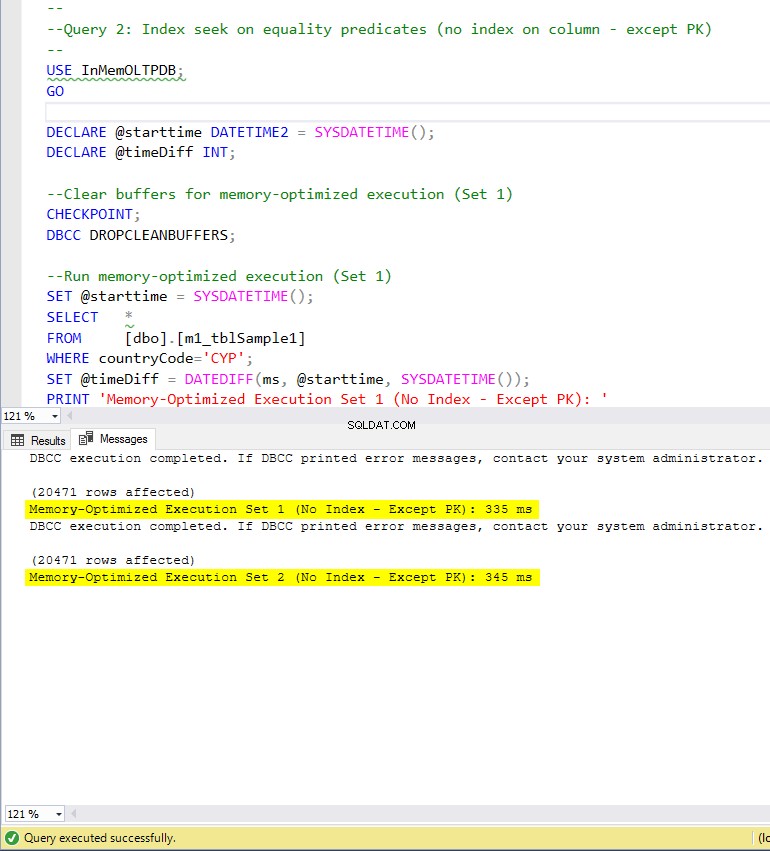
Figure 7 : Temps d'exécution de la requête 2 (sans index, à l'exception de PK).
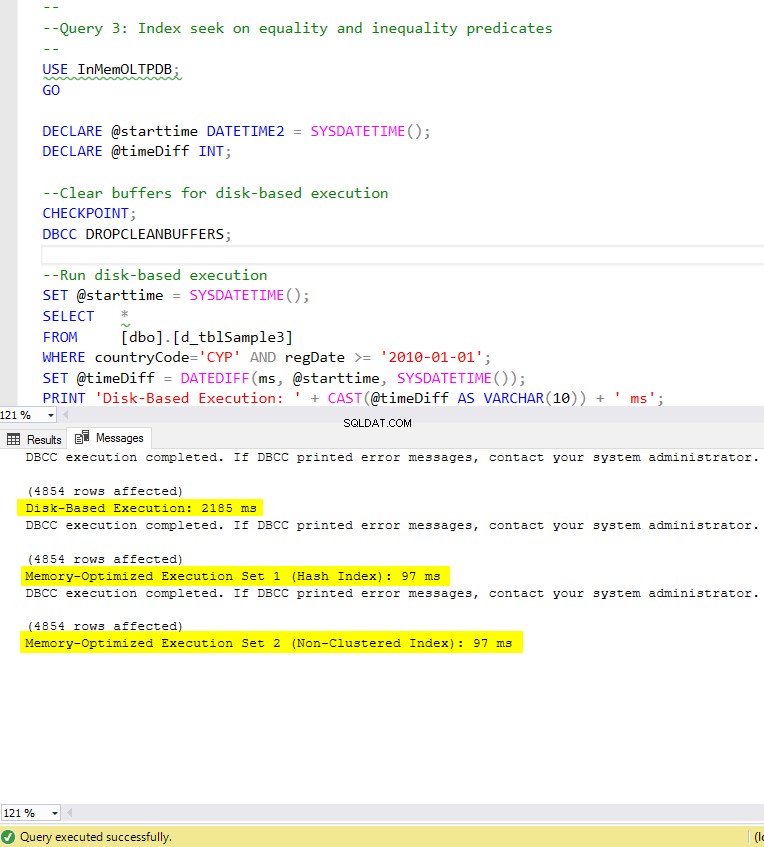
Figure 8 : Temps d'exécution de la requête 3 (avec index).
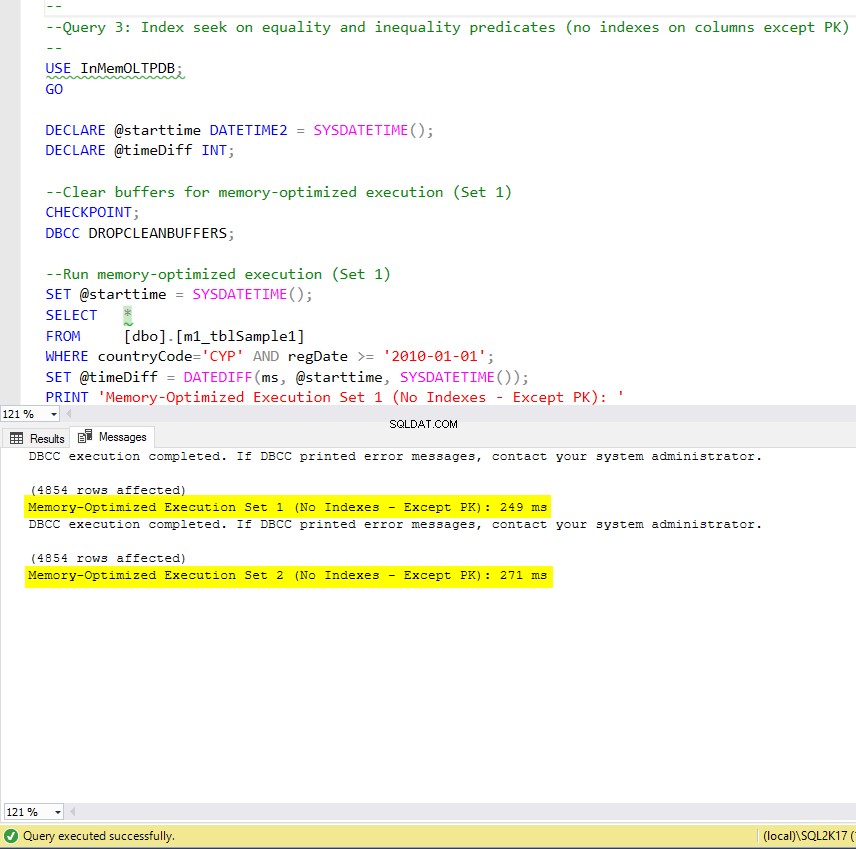
Figure 9 : Temps d'exécution de la requête 3 (sans index, à l'exception de PK).
Maintenant, résumons les résultats obtenus ci-dessus. Le tableau suivant affiche les temps d'exécution mesurés pour toutes les requêtes ci-dessus et les combinaisons table/index.
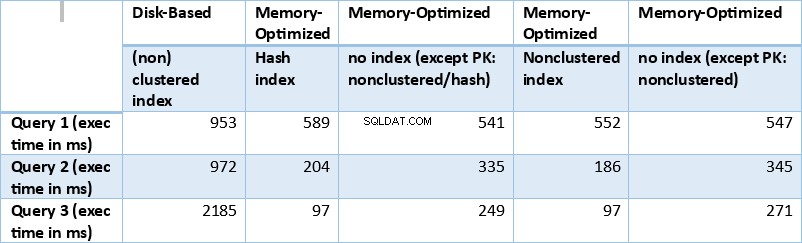
Tableau 1 :Résumé des temps d'exécution (ms) pour toutes les requêtes.
Discussion
Si nous examinons les résultats d'exécution résumés dans le tableau ci-dessus, nous pouvons tirer certaines conclusions. Traçons chaque résultat de requête dans un graphique. Les graphiques ci-dessous illustrent les temps d'exécution, ainsi que l'accélération des tables optimisées en mémoire par rapport aux tables sur disque.
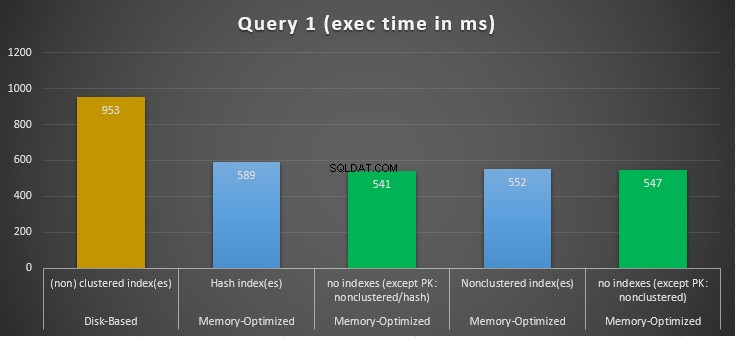
Figure 10 :Comparaison des temps d'exécution de la requête 1.
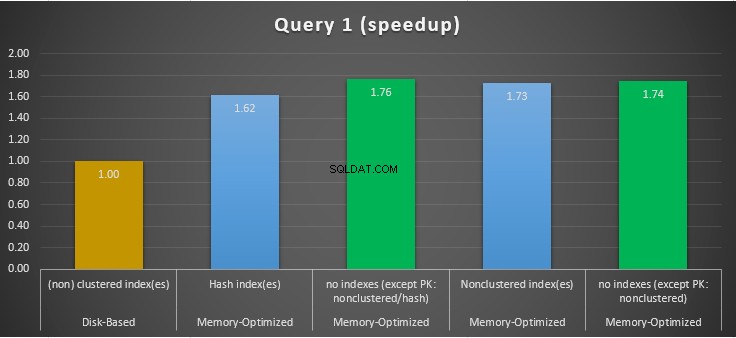
Figure 11 :Comparaison de l'accélération de la requête 1.
En ce qui concerne la requête 1, qui était une agrégation GROUP BY, nous pouvons voir que les deux versions (index vs aucun index) des tables optimisées en mémoire, fonctionnent presque de la même manière avec une accélération sur la table sur disque (activée avec des index) entre 1,62 et 1,76 fois plus rapide.
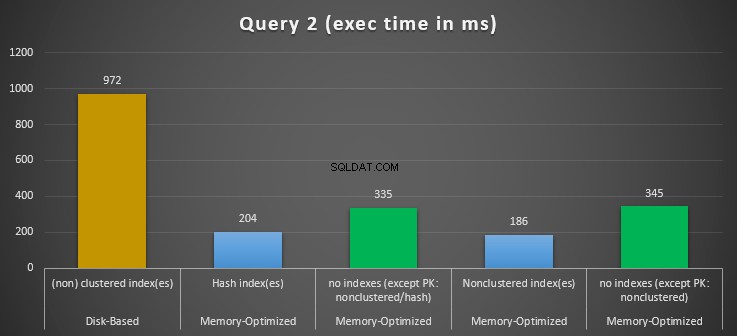
Figure 12 :Comparaison des temps d'exécution de la requête 2.
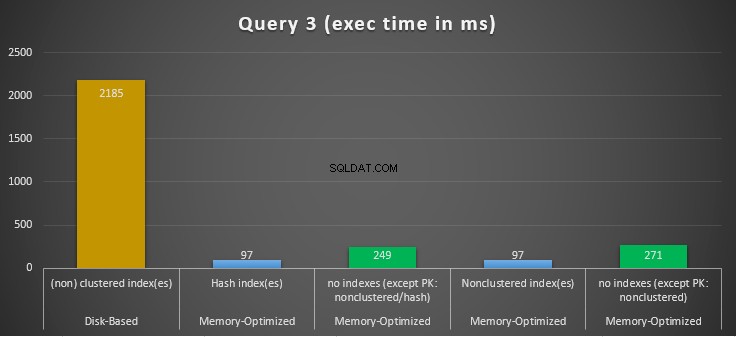
Figure 13 :Comparaison de l'accélération de la requête 2.
En ce qui concerne la requête 2, qui impliquait une recherche d'index sur des prédicats d'égalité, nous pouvons voir que les tables optimisées en mémoire avec index ont bien mieux fonctionné que les tables optimisées en mémoire sans index. De plus, nous observons que la table optimisée en mémoire avec un index non clusterisé dans la colonne utilisée comme prédicat a mieux performé que celle avec l'index de hachage.
Ainsi, pour la requête 2, le gagnant est la table optimisée en mémoire avec l'index non clusterisé, ayant une accélération globale de 5,23 fois plus rapide que l'exécution sur disque.
Figure 14 :Comparaison des temps d'exécution de la requête 3.
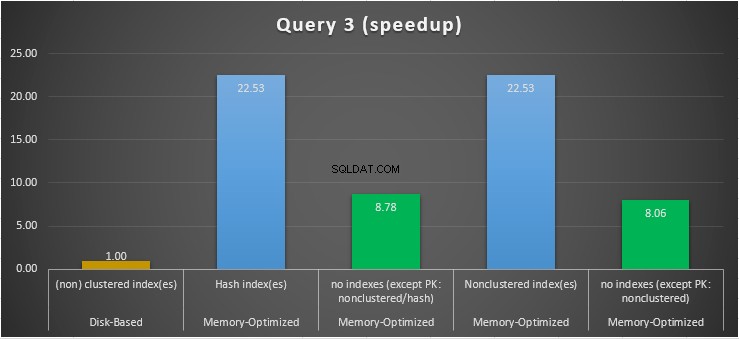
Figure 15 :Comparaison de l'accélération de la requête 3.
En ce qui concerne la requête 3, qui impliquait une recherche d'index sur les prédicats d'égalité et d'inégalité combinés, nous pouvons voir que les tables optimisées en mémoire avec des index ont obtenu de bien meilleurs résultats que les tables optimisées en mémoire sans index. De plus, nous observons que la table optimisée en mémoire avec un index non clusterisé dans la colonne utilisée comme prédicat a fonctionné de la même manière que celle avec l'index de hachage.
À cette fin, nous pouvons voir que les deux tables optimisées en mémoire qui utilisent des index dans les colonnes utilisées comme prédicats, ont fonctionné plus rapidement que celles sans index et ont atteint une accélération de 22,53 fois plus rapide sur l'exécution sur disque.
Conclusion
Dans cet article, nous avons examiné l'utilisation des index dans les tables optimisées en mémoire dans SQL Server. Nous avons utilisé comme référence pour chaque requête, la meilleure configuration de table sur disque possible, puis nous avons comparé les performances de trois requêtes par rapport aux tables sur disque et 4 variantes de tables optimisées en mémoire. Deux des quatre tables optimisées en mémoire utilisaient des index (hachés/non clusterisés) et les deux autres n'utilisaient aucun index, à l'exception de ceux utilisés pour les clés primaires.
La conclusion générale est que vous devez toujours examiner comment les index affectent les performances, non seulement pour les tables à mémoire optimisée, mais également pour celles basées sur disque, et chaque fois que vous identifiez qu'ils améliorent les performances, pour les utiliser. Les résultats des exemples de cet article montrent que si vous utilisez les index appropriés dans les tables optimisées en mémoire, vous pouvez obtenir de bien meilleures performances pour les requêtes similaires à celles utilisées dans cet article par rapport à la simple utilisation de tables optimisées en mémoire sans index. .
Références et lectures complémentaires :
- Microsoft Docs :Tableaux à mémoire optimisée
- Microsoft Docs :Consignes d'utilisation des index sur les tables à mémoire optimisée
- Microsoft Docs :index sur les tables à mémoire optimisée
Outil utile :
dbForge Index Manager - complément SSMS pratique pour analyser l'état des index SQL et résoudre les problèmes de fragmentation d'index.